
Construindo um sistema resiliente: nossa jornada para a observabilidade na Intercom
Publicados: 2022-07-14Na Intercom, focamos acima de tudo na experiência do cliente – a disponibilidade e o desempenho do nosso serviço são nossa principal prioridade. Isso requer uma forte cultura de observabilidade em nossas equipes e sistemas.
Como resultado, investimos muito na confiabilidade de nossa aplicação. Mas falhas imprevisíveis são inevitáveis e, quando acontecem, são os humanos que as consertam.
Operamos um sistema sociotécnico, e sua capacidade de recuperação diante da adversidade é chamada de resiliência. Um dos componentes cruciais da resiliência é a observabilidade, as etapas que damos para permitir que os humanos “olhem” dentro dos sistemas que executam.
Este post explorará o caminho para construir uma cultura de observabilidade mais forte e as lições que aprendemos ao longo do caminho.
O que queremos dizer com observabilidade na Intercom?
Na Intercom, enviamos para aprender. Nosso ambiente de produção é onde nosso código, infraestrutura, dependências de terceiros e nossos clientes se reúnem para criar uma realidade objetiva – é o único lugar para aprender e validar o impacto do nosso trabalho. Definimos observabilidade como um processo contínuo de humanos fazendo perguntas sobre produção e obtendo respostas*.
Vamos detalhar um pouco mais:
- Processo contínuo: observabilidade bem-sucedida significa que as pessoas observam com a maior frequência possível.
- Perguntas sobre produção: queríamos que nossa definição fosse ampla, genérica e representativa do amplo escopo de fluxos de trabalho que atendemos.
- Respostas*: Observe o asterisco. Nenhuma ferramenta lhe dará respostas, apenas ofereça leads que você possa seguir para encontrar as respostas reais. Você tem que usar seus próprios modelos mentais e compreensão dos sistemas que você executa.
Estágio 1: Problema e solução
Armados com nossa própria definição de observabilidade, avaliamos nossas práticas existentes e formulamos uma declaração de problema. Até recentemente, nossas ferramentas de observabilidade eram baseadas principalmente em métricas. Um fluxo de trabalho típico envolvia olhar para um painel cheio de gráficos com métricas divididas e cortadas por várias combinações de atributos. As pessoas procurariam correlações, mas muitas vezes saíam sem insights satisfatórios.
“As métricas são fáceis de adicionar e entender, mas faltam atributos de alta cardinalidade (por exemplo, ID do cliente), dificultando a conclusão de uma investigação”
As métricas são fáceis de adicionar e entender, mas faltam atributos de alta cardinalidade (por exemplo, ID do cliente), dificultando a conclusão de uma investigação. Anteriormente, alguns defensores da observabilidade continuariam o fluxo de trabalho usando ferramentas secundárias (por exemplo, logs, exceções etc.), tentando acessar as informações de alta cardinalidade e criar uma imagem mais completa. Essa habilidade exigia prática constante – um pedido irreal para a maioria dos engenheiros de produto que estão ocupados entregando produtos.
Identificamos essa falta de experiência consolidada de observabilidade como um problema a ser resolvido. Queríamos que fosse fácil para qualquer pessoa fazer uma pergunta arbitrária sobre produção e obter insights sem ter que dominar um conjunto de ferramentas desconectadas, mal configuradas e caras. Para mitigar o problema, decidimos dobrar a telemetria de rastreamento.

Um painel operacional típico que usamos antes de dobrar os rastreamentos
Por que vestígios?
Qualquer ferramenta de observabilidade é apenas uma ferramenta com um humano por trás – e os humanos precisam de boas visualizações. Não importa que tipo de dados alimenta a visualização, apenas que a ferramenta permite alternar facilmente entre diferentes visualizações e obter perspectivas alternativas sobre o problema.
Os rastreamentos têm uma enorme vantagem sobre outros dados de telemetria – eles codificam informações suficientes sobre transações para potencializar praticamente qualquer visualização. A criação de fluxos de trabalho de observabilidade em cima dos rastreamentos garante uma experiência consolidada sem a necessidade de alternar os dados subjacentes ou a ferramenta.
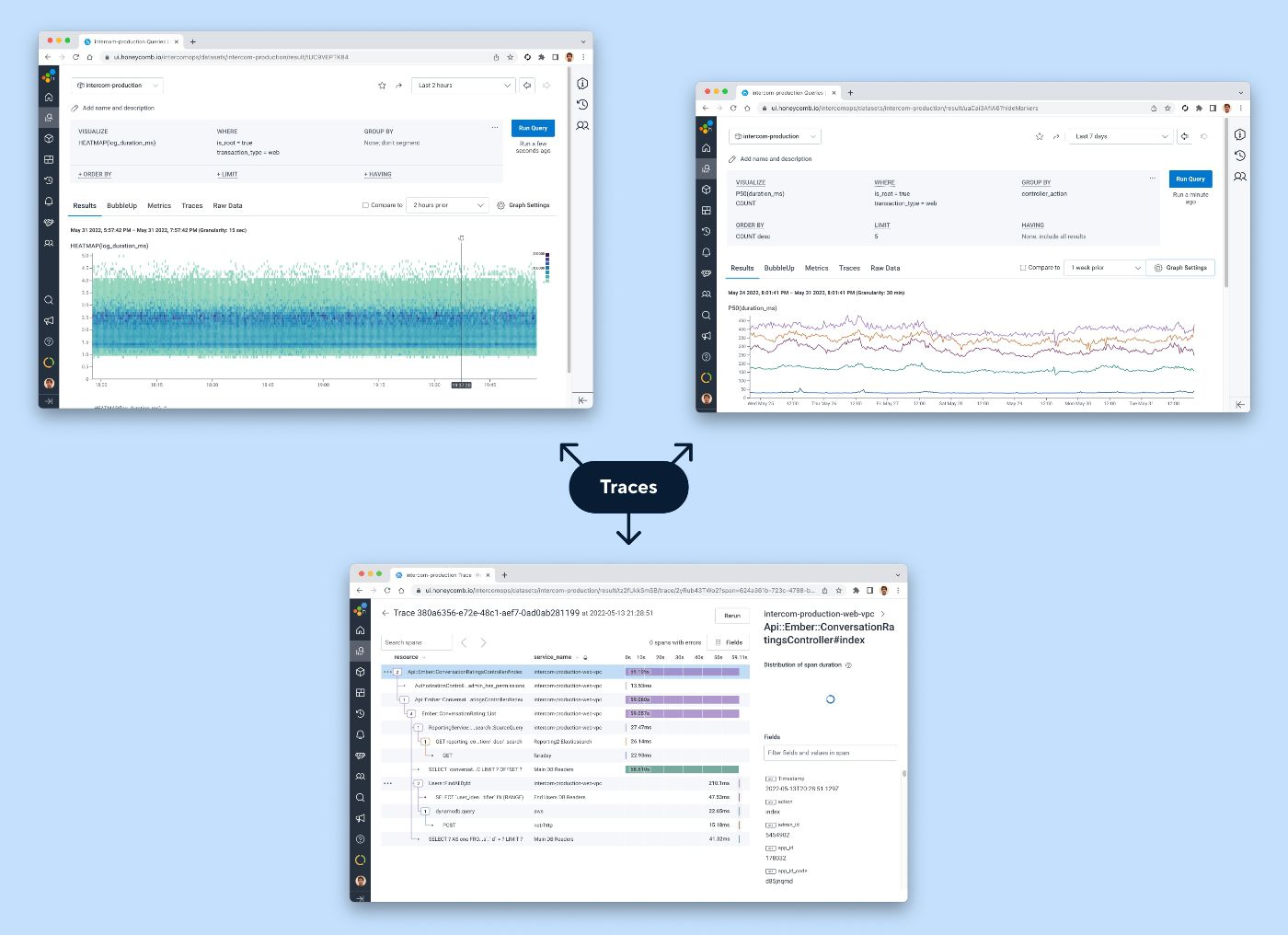
Alguns dos tipos de visualizações que podem ser alimentados por rastreamentos
Etapa 2: implementando rastreamentos
Na Intercom começamos pequeno, decidindo como é o sucesso e monitorando o progresso ao longo do caminho. Nosso principal objetivo foi confirmar que os rastreamentos tornariam os fluxos de trabalho de observabilidade mais eficientes. Para isso, precisávamos colocar os rastros nas mãos dos engenheiros o mais rápido possível.
“Em vez de instrumentar nosso aplicativo com rastreamentos do zero, usamos uma biblioteca de rastreamento existente que já estava nas dependências”
Para economizar tempo, usamos nosso fornecedor existente, Honeycomb, para nossa prova de conceito. Já construímos um ótimo relacionamento com eles ao usar sua ferramenta para eventos estruturados no passado.
Em vez de instrumentar nosso aplicativo com rastreamentos do zero, usamos uma biblioteca de rastreamento existente que já estava nas dependências e realizamos um pequeno ajuste para converter os dados de rastreamento no formato nativo do Honeycomb. Começamos com uma amostragem determinística simples, retendo ~1% de todas as transações que processamos.
Permitindo que os companheiros de equipe adotem rastros
Mudar uma organização para rastros não é pouca coisa. Os rastreamentos são mais complexos do que métricas ou logs e têm uma curva de aprendizado acentuada. Instrumentação, pipeline de dados e ferramentas são importantes, mas o maior desafio é permitir que seus colegas de equipe maximizem o uso de rastreamentos. Com nossa prova de conceito em produção, começamos imediatamente a nos concentrar na construção de uma cultura de observabilidade.
“Não nos concentramos apenas em engenheiros – conversamos com diretores, gerentes de programas técnicos, membros da equipe de segurança e representantes de suporte ao cliente para enfatizar como os rastreamentos podem ajudá-los a resolver seus problemas específicos”
Encontrar aliados foi a chave para o sucesso. Reunimos um grupo de campeões que já eram habilidosos em observabilidade. Eles ajudaram a confirmar nossas suposições e a divulgar os rastros em suas equipes. Mas não nos concentramos apenas em engenheiros – conversamos com diretores, gerentes de programas técnicos, membros da equipe de segurança e representantes de suporte ao cliente para enfatizar como os rastreamentos podem ajudá-los a resolver seus problemas específicos.
Adaptar nossa mensagem ajudou a travar o apoio. A introdução de novas ferramentas sempre traz um certo risco – ao demonstrar potencial e deixar as pessoas empolgadas, aumentamos nossas chances de sucesso.
Fase 3: Decidindo sobre o fornecedor certo
Com o início do programa de capacitação, começamos a analisar os fornecedores modernos centrados em rastreamento e formulamos um conjunto de critérios para avaliar os candidatos em potencial.
Fluxos de trabalho: Identificamos o fluxo de trabalho exploratório como o mais importante – ele permitiria aos engenheiros dividir arbitrariamente os dados de produção e obter insights por meio de visualizações e atributos de alta cardinalidade. Uma grande parte do diagnóstico de um problema é ser capaz de identificá-lo, e isso significa entender como é o “normal”. Queríamos tornar mais fácil para os engenheiros explorarem a produção fazendo perguntas com a maior frequência possível, não apenas quando surgem problemas.

“Queríamos controle total sobre a forma como os dados seriam amostrados e retidos”
Controles de amostragem e retenção : queríamos controle total sobre a forma como os dados seriam amostrados e retidos. A amostragem determinística nos ajudou a começar a trabalhar rapidamente, mas queríamos ser mais seletivos e reter mais traços “interessantes” (por exemplo, erros, solicitações lentas) usando amostragem dinâmica inteligente enquanto permanecemos abaixo do limite do contrato.
Visualizações de dados precisas : queríamos ter certeza de que, independentemente da técnica de amostragem que usássemos, as ferramentas de observabilidade lidassem com isso de forma transparente, expondo números aproximados “verdadeiros” nas visualizações. Cada fornecedor abordou esse problema de forma diferente – alguns exigem o envio de todos os dados para um agregador global para inferir métricas para indicadores-chave como taxa de erro, volume, etc. Esta não era uma opção para nós, dado o enorme volume de dados gerados por nossa rica instrumentação.
Preços : queríamos um esquema de preços simples e previsível que se correlacionasse com o valor que obteríamos da ferramenta. Cobrar pela quantidade de dados retidos e expostos parecia justo.
Métricas de envolvimento : queríamos que o fornecedor fosse um bom parceiro e nos ajudasse a acompanhar a adoção e a eficácia da ferramenta, expondo as principais métricas de uso e os níveis de envolvimento.
Não existe um fornecedor perfeito, então esteja pronto para fazer alguns compromissos. No final, concluímos que o Honeycomb não apenas funcionou melhor para o fluxo de trabalho principal que identificamos, mas também marcou as caixas de amostragem, preços e métricas de uso – portanto, evitamos a onerosa migração de fornecedores.
Após um ano desafiador de trabalho, concluímos a parte técnica do programa de observabilidade. Isto é o que tínhamos conseguido:
- Nosso principal aplicativo de monólito foi auto-instrumentado com traços ricos em atributos de alta qualidade.
- Os engenheiros tinham um pequeno conjunto de métodos convenientes para adicionar instrumentação personalizada ao seu código.
- Implantamos o Honeycomb Refinery para amostrar dados dinamicamente e reter mais traços “interessantes”. Incentivamos os engenheiros a configurar regras de retenção personalizadas para um controle mais granular. Para as transações mais valiosas, e quando economicamente viável, oferecemos 100% de retenção para fornecer às pessoas os dados de que precisavam.
Etapa 4: aumentar a adoção
Depois de nos comprometermos com o Honeycomb e concluirmos o trabalho no pipeline de dados, voltamos nosso foco para a habilitação. Para construir uma cultura de observabilidade, você precisa facilitar a adesão das pessoas. Aqui estão algumas das maneiras pelas quais ajudamos as equipes a adotar novas ferramentas de observabilidade:
Rastreamento em ambiente de desenvolvimento
Para familiarizar os engenheiros com a instrumentação de rastreamento e incentivá-los a adicioná-la ao código, oferecemos rastreamento opcional do ambiente de desenvolvimento local com os rastreamentos expostos no Honeycomb. Isso ajudou as pessoas a visualizar a nova instrumentação personalizada exatamente da mesma maneira que a veriam quando o código chegasse à produção.
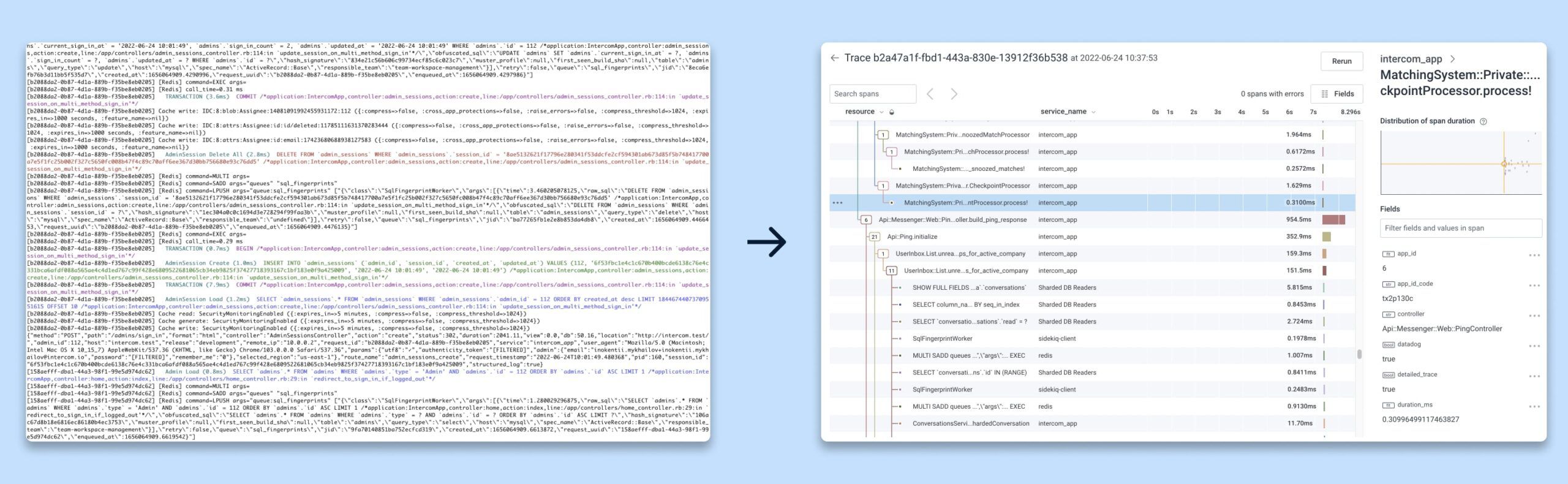
Os logs podem ser difíceis de ler e interpretar, enquanto as visualizações de rastreamento são muito mais estruturadas e organizadas
Atalhos de consulta do Slackbot
Quando a produção está com problemas, a última coisa que você quer é ter que procurar a consulta certa. Adicionamos uma reação de bot personalizada a uma mensagem “mostre-me desempenho na web”. Seguir o link do Slackbot abre um desempenho de endpoints da web dividido por serviço.
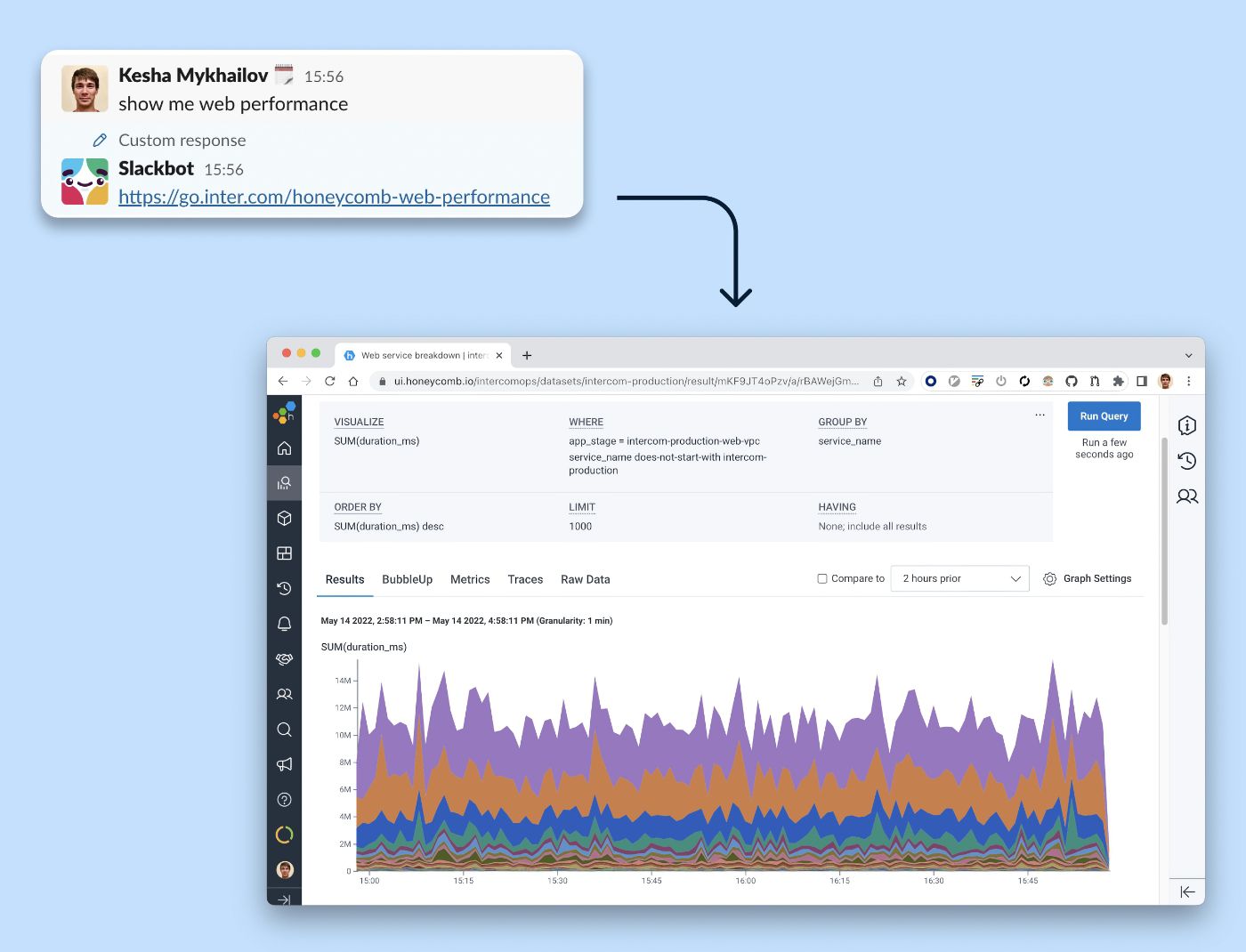
Simplificamos nosso fluxo de trabalho de observabilidade com um Slackbot que fornece um atalho para uma consulta popular em nossas ferramentas de observabilidade
Etapa 5: Reflexões e próximos passos
Medindo a adoção
Medir o retorno do investimento (ROI) em ferramentas de observabilidade é um desafio. O rastreamento do número de usuários ativos é um bom indicador da frequência com que os engenheiros se envolvem com as ferramentas e nos beneficiamos muito das métricas de uso do Honeycomb.

Este gráfico mostra o aumento no número de usuários ativos do Honeycomb desde o início da ativação da observabilidade
Fomos mais longe e medimos a utilidade desses compromissos. Postulamos que, se os insights obtidos com as ferramentas de observabilidade fossem valiosos, as pessoas os compartilhariam com seus pares. Nossos fluxos de trabalho de engenharia dependem muito dos problemas do Github, por isso decidimos contar o número de problemas ou solicitações pull em que o Honeycomb foi mencionado ou vinculado (rastreamento, resultado da consulta etc.) como um proxy para uma métrica de adoção. À medida que dobramos a habilitação no final de 2021, observamos uma explosão no número de questões mencionando o Honeycomb, provando que estávamos no caminho certo.
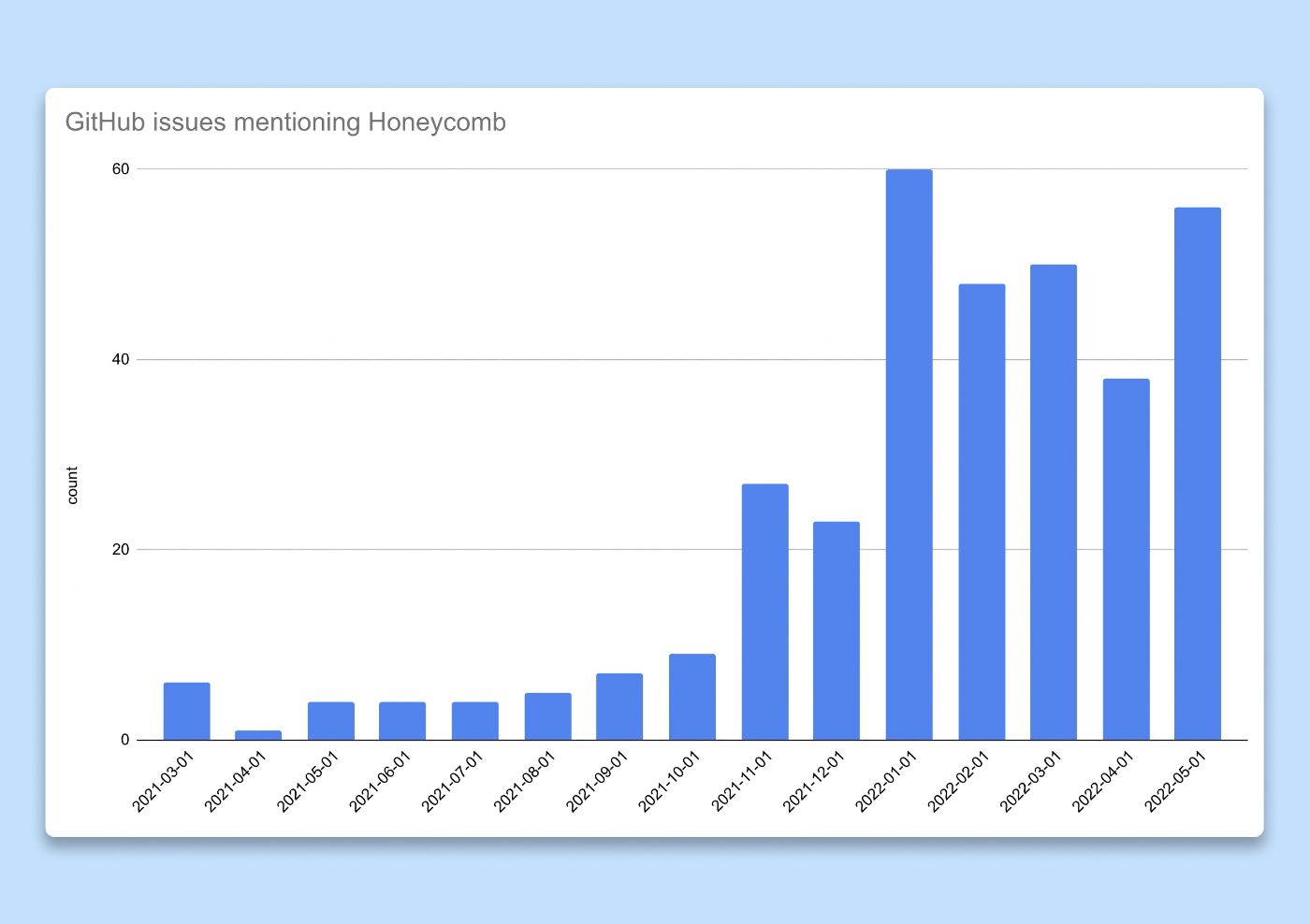
Gráfico de barras mostrando o número de problemas do GitHub em que o Honeycomb é mencionado no título ou na descrição
Fluxos de trabalho inesperados
Construir uma base sólida de observabilidade permitiu fluxos de trabalho que não poderíamos imaginar antes. Aqui estão alguns dos nossos favoritos:
Informando o programa de custo : Como rastreamos todo o tráfego e temos intervalos para consultas SQL, solicitações Elasticsearch, etc., podemos investigar picos de utilização de partes compartilhadas separadas de nossa infraestrutura (por exemplo, cluster de banco de dados) e atribuí-los a um único cliente. Combinando esses dados com o custo de componentes de infraestrutura individuais, podemos colocar um preço aproximado em cada transação que atendemos. A observabilidade inesperadamente se tornou um componente integral do nosso programa de custos de infraestrutura.
Melhorando a auditoria de segurança : Ser capaz de reter 100% das transações selecionadas nos permitiu preservar todas as interações com nosso console de dados de produção, ajudando a segurança a estabelecer uma melhor visibilidade sobre o acesso aos dados de nossos clientes.
Qual é o próximo?
Construir uma cultura de observabilidade continuará a fazer parte de nosso programa técnico: vamos nos concentrar em melhorar nosso material de integração, integrar ainda mais a observabilidade por meio de rastros em nossas operações de P&D e explorar a instrumentação de front-end.
Interessado em se juntar à nossa equipe? Confira nossas funções de engenharia abertas aqui.
