
Construire un système résilient : notre parcours vers l'observabilité chez Intercom
Publié: 2022-07-14Chez Intercom, nous nous concentrons avant tout sur l'expérience client - la disponibilité et la performance de notre service sont notre priorité absolue. Cela nécessite une forte culture d'observabilité au sein de nos équipes et de nos systèmes.
De ce fait, nous investissons beaucoup dans la fiabilité de notre application. Mais les pannes imprévisibles sont inévitables, et lorsqu'elles se produisent, ce sont les humains qui les résolvent.
Nous opérons un système socio-technique, et sa capacité à se redresser face à l'adversité s'appelle la résilience. L'un des éléments cruciaux de la résilience est l'observabilité, les mesures que nous prenons pour permettre aux humains de « regarder » à l'intérieur des systèmes qu'ils gèrent.
Cet article explorera la voie vers la construction d'une culture d'observabilité plus forte et les leçons que nous avons apprises en cours de route.
Qu'entend-on par observabilité chez Intercom ?
Chez Intercom, nous expédions pour apprendre. Notre environnement de production est l'endroit où notre code, notre infrastructure, nos dépendances tierces et nos clients se réunissent pour créer une réalité objective. C'est le seul endroit pour apprendre et valider l'impact de notre travail. Nous définissons l'observabilité comme un processus continu par lequel les humains posent des questions sur la production et obtiennent des réponses*.
Décomposons cela un peu plus :
- Processus continu : Une observabilité réussie signifie que les gens observent aussi souvent que possible.
- Questions sur la production : Nous voulions que notre définition soit large, générique et représentative du large éventail de flux de travail que nous prenons en charge.
- Réponses* : Notez l'astérisque. Aucun outil ne vous donnera de réponses, ne propose que des pistes que vous pouvez suivre pour trouver les vraies réponses. Vous devez utiliser vos propres modèles mentaux et votre compréhension des systèmes que vous gérez.
Étape 1 : Problème et solution
Armés de notre propre définition de l'observabilité, nous avons évalué nos pratiques existantes et formulé un énoncé du problème. Jusqu'à récemment, nos outils d'observabilité étaient principalement basés sur des métriques. Un flux de travail typique consistait à consulter un tableau de bord rempli de graphiques avec des mesures découpées en tranches et en dés par diverses combinaisons d'attributs. Les gens chercheraient des corrélations, mais partiraient souvent sans avoir des idées satisfaisantes.
"Les métriques sont faciles à ajouter et à comprendre, mais il leur manque des attributs à haute cardinalité (par exemple, l'ID client), ce qui rend difficile la réalisation d'une enquête"
Les mesures sont faciles à ajouter et à comprendre, mais il leur manque des attributs à cardinalité élevée (par exemple, l'ID client), ce qui rend difficile la réalisation d'une enquête. Auparavant, une poignée de champions de l'observabilité poursuivaient le flux de travail à l'aide d'outils secondaires (par exemple, journaux, exceptions, etc.), en essayant d'accéder aux informations à haute cardinalité et de créer une image plus complète. Cette compétence nécessitait une pratique constante - une demande irréaliste pour la majorité des ingénieurs produit occupés à livrer le produit.
Nous avons identifié ce manque d'expérience d'observabilité consolidée comme un problème à résoudre. Nous voulions qu'il soit facile pour quiconque de poser une question arbitraire sur la production et d'obtenir des informations sans avoir à maîtriser un ensemble d'outils déconnectés, sous-configurés et coûteux. Pour atténuer le problème, nous avons décidé de doubler la télémétrie de traçage.

Un tableau de bord opérationnel typique que nous avons utilisé avant de doubler les traces
Pourquoi tracer ?
Tout outil d'observabilité n'est qu'un outil avec un humain derrière lui - et les humains ont besoin de bonnes visualisations. Peu importe le type de données qui alimente la visualisation, l'outil vous permet simplement de basculer de manière transparente entre différentes visualisations et d'obtenir des perspectives alternatives sur le problème.
Les traces ont un énorme avantage sur les autres données de télémétrie : elles encodent suffisamment d'informations sur les transactions pour alimenter pratiquement n'importe quelle visualisation. La création de flux de travail d'observabilité sur les traces garantit une expérience consolidée fluide sans qu'il soit nécessaire de changer les données sous-jacentes ou l'outil.
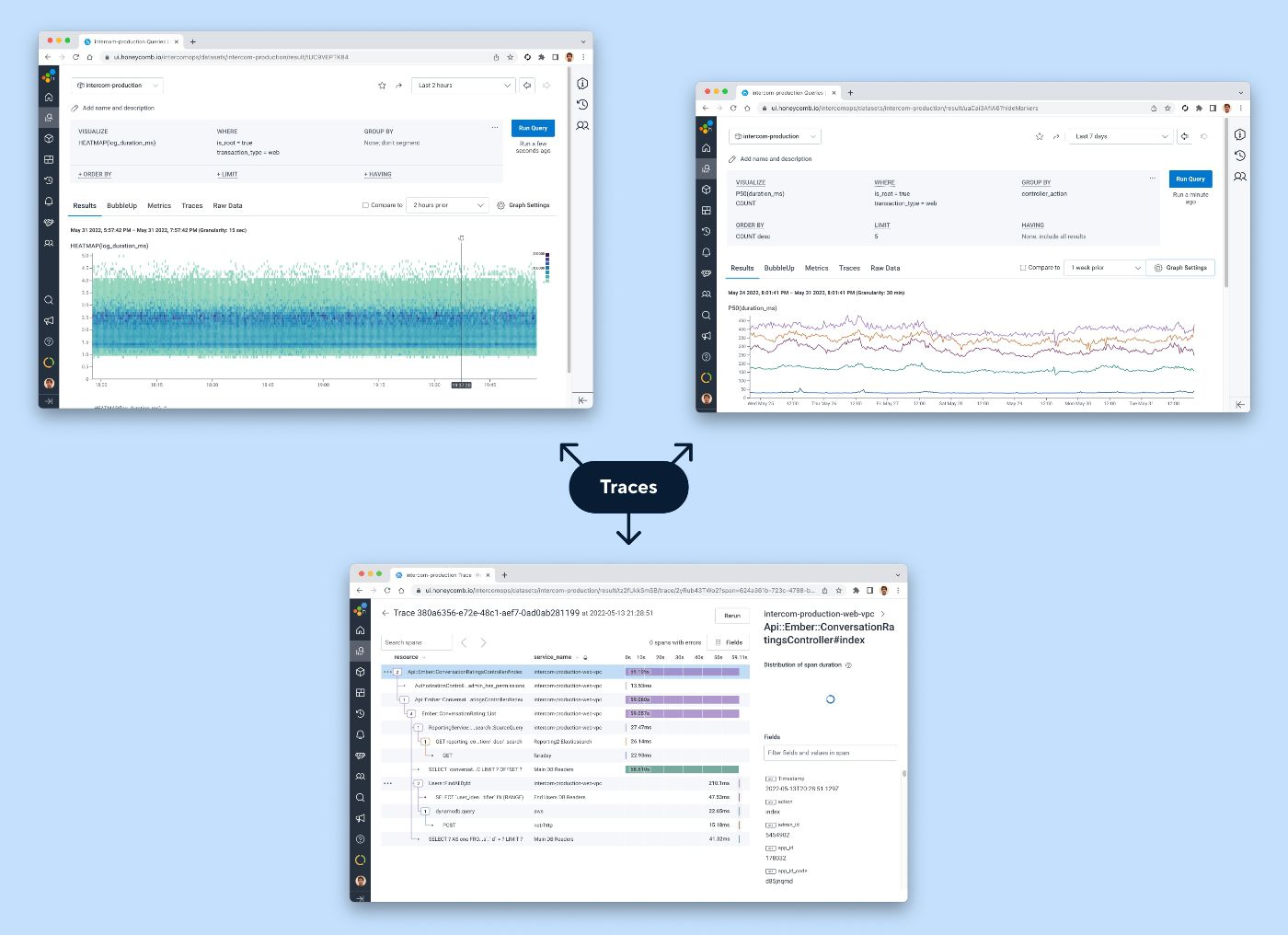
Certains des types de visualisations qui peuvent être alimentées par des traces
Etape 2 : Implémentation des traces
Chez Intercom, nous commençons petit, en décidant à quoi ressemble le succès et en surveillant les progrès en cours de route. Notre objectif principal était de confirmer que les traces rendraient les workflows d'observabilité plus efficaces. Pour cela, nous devions mettre les traces entre les mains des ingénieurs le plus tôt possible.
"Au lieu d'instrumenter notre application avec des traces à partir de zéro, nous avons utilisé une bibliothèque de traçage existante qui se trouvait déjà dans les dépendances"
Pour gagner du temps, nous avons fait appel à notre fournisseur existant, Honeycomb, pour notre preuve de concept. Nous avions déjà construit une excellente relation avec eux en utilisant leur outil pour des événements structurés dans le passé.
Au lieu d'instrumenter notre application avec des traces à partir de zéro, nous avons utilisé une bibliothèque de traçage existante qui se trouvait déjà dans les dépendances et effectué un petit ajustement pour convertir les données de trace au format natif Honeycomb. Nous avons commencé par un simple échantillonnage déterministe, en retenant ~1 % de toutes les transactions que nous avons traitées.
Permettre aux coéquipiers d'adopter des traces
Faire basculer une organisation vers des traces n'est pas une mince affaire. Les traces sont plus complexes que les métriques ou les journaux et ont une courbe d'apprentissage abrupte. L'instrumentation, le pipeline de données et les outils sont tous importants, mais le plus grand défi consiste à permettre à vos coéquipiers de maximiser leur utilisation des traces. Avec notre preuve de concept en cours de production, nous avons immédiatement commencé à nous concentrer sur la construction d'une culture d'observabilité.
"Nous ne nous sommes pas concentrés uniquement sur les ingénieurs - nous avons parlé avec des directeurs, des responsables de programmes techniques, des membres de l'équipe de sécurité et des représentants du support client pour souligner comment les traces pourraient les aider à résoudre leurs problèmes spécifiques"
Trouver des alliés était la clé du succès. Nous avons réuni un groupe de champions qui étaient déjà doués pour l'observabilité. Ils ont aidé à confirmer nos hypothèses et à faire passer le mot sur les traces au sein de leurs équipes. Mais nous ne nous sommes pas concentrés uniquement sur les ingénieurs. Nous avons discuté avec des directeurs, des responsables de programmes techniques, des membres de l'équipe de sécurité et des représentants du support client pour souligner comment les traces pouvaient les aider à résoudre leurs problèmes spécifiques.
Adapter notre message a aidé à verrouiller le soutien. L'introduction de nouveaux outils comporte toujours un certain risque - en démontrant le potentiel et en excitant les gens, nous avons augmenté nos chances de succès.
Étape 3 : Choisir le bon fournisseur
Avec le lancement du programme d'activation, nous avons commencé à examiner les fournisseurs modernes centrés sur le traçage et avons formulé un ensemble de critères pour évaluer les candidats potentiels.
Flux de travail : nous avons identifié le flux de travail exploratoire comme le plus important : il permettrait aux ingénieurs de découper et de découper arbitrairement les données de production et d'obtenir des informations via des visualisations et des attributs à haute cardinalité. Une grande partie du diagnostic d'un problème consiste à pouvoir le repérer, ce qui signifie comprendre à quoi ressemble la "normale". Nous voulions permettre aux ingénieurs d'explorer facilement la production en posant des questions aussi fréquemment que possible, pas seulement lorsque des problèmes surviennent.

"Nous voulions un contrôle total sur la manière dont les données seraient échantillonnées et conservées"
Contrôles d' échantillonnage et de rétention : nous voulions un contrôle total sur la manière dont les données seraient échantillonnées et conservées. L'échantillonnage déterministe nous a permis d'être rapidement opérationnel, mais nous voulions être plus sélectifs et conserver davantage de traces "intéressantes" (par exemple, erreurs, requêtes lentes) en utilisant un échantillonnage dynamique intelligent tout en restant en dessous de la limite du contrat.
Visualisations de données précises : nous voulions nous assurer que, quelle que soit la technique d'échantillonnage que nous utilisions, les outils d'observabilité la géraient de manière transparente en exposant les "vrais" nombres approximés dans les visualisations. Chaque fournisseur a abordé ce problème différemment - certains nécessitent d'envoyer toutes les données à un agrégateur mondial pour déduire des métriques pour des indicateurs clés tels que le taux d'erreur, le volume, etc. Ce n'était pas une option pour nous étant donné le volume massif de données générées par notre riche instrumentation.
Tarification : Nous voulions un schéma de tarification simple et prévisible en corrélation avec la valeur que nous obtiendrions de l'outil. Facturer la quantité de données conservées et exposées semblait juste.
Métriques d' engagement : nous voulions que le fournisseur soit un bon partenaire et nous aide à suivre l'adoption et l'efficacité de l'outil en exposant les métriques d'utilisation clés et les niveaux d'engagement.
Il n'y a pas de fournisseur parfait, alors soyez prêt à faire des compromis. En fin de compte, nous avons conclu que Honeycomb fonctionnait non seulement mieux pour le flux de travail principal que nous avions identifié, mais cochait également les cases sur l'échantillonnage, la tarification et les mesures d'utilisation - nous avons donc évité la migration coûteuse des fournisseurs.
Après une année de travail exigeante, nous avions terminé la partie technique du programme d'observabilité. Voici ce que nous avions réalisé :
- Notre principale application monolithe avait été auto-instrumentée avec des traces riches en attributs de haute qualité.
- Les ingénieurs disposaient d'un petit ensemble de méthodes pratiques pour ajouter une instrumentation personnalisée à leur code.
- Nous avions déployé Honeycomb Refinery pour échantillonner dynamiquement les données et conserver davantage de traces « intéressantes ». Nous avons encouragé les ingénieurs à configurer des règles de conservation personnalisées pour un contrôle plus précis. Pour les transactions les plus précieuses, et lorsque cela est économiquement faisable, nous avons proposé une rétention à 100 % pour donner aux gens les données dont ils avaient besoin.
Étape 4 : Accroître l'adoption
Après nous être engagés dans Honeycomb et avoir terminé le travail sur le pipeline de données, nous nous sommes recentrés sur l'activation. Pour construire une culture de l'observabilité, il faut faciliter l'adhésion des gens. Voici quelques-unes des façons dont nous avons aidé les équipes à adopter de nouveaux outils d'observabilité :
Traçage dans l'environnement de développement
Pour familiariser les ingénieurs avec l'instrumentation de traçage et les encourager à l'ajouter à leur code, nous avons proposé un traçage facultatif à partir de l'environnement de développement local avec les traces exposées dans Honeycomb. Cela a aidé les gens à visualiser une nouvelle instrumentation personnalisée exactement de la même manière qu'ils le verraient lorsque le code entrerait en production.
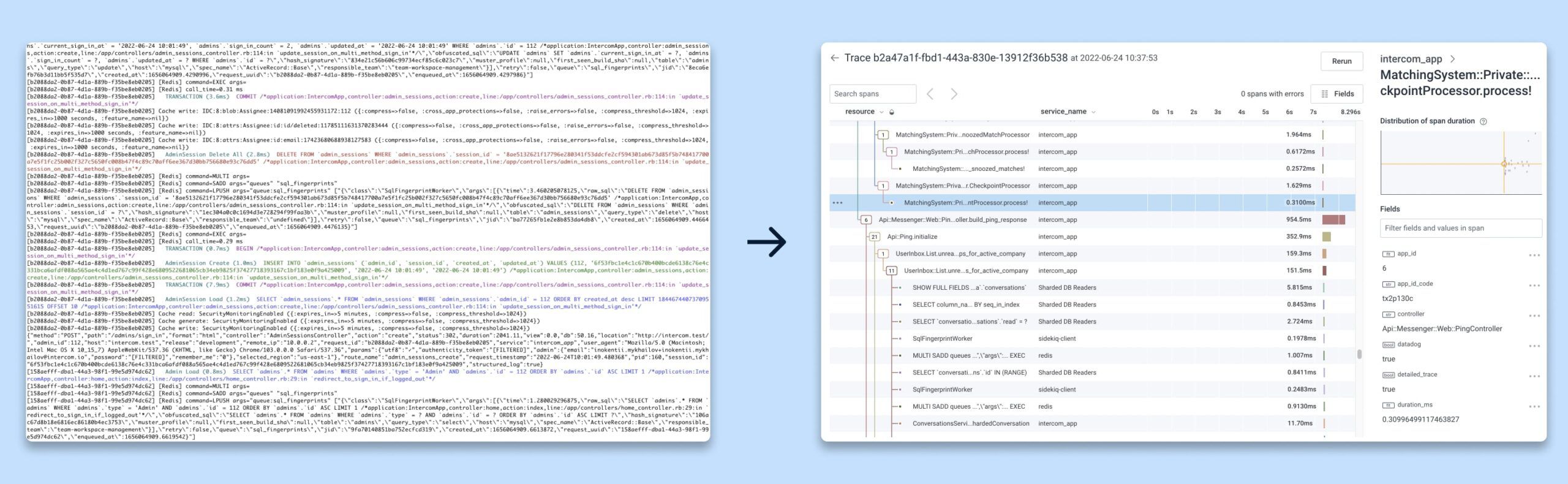
Les journaux peuvent être difficiles à lire et à interpréter, tandis que les vues de trace sont beaucoup plus structurées et organisées
Raccourcis de requête Slackbot
Lorsque la production est en difficulté, la dernière chose que vous souhaitez est de devoir vous démener pour trouver la bonne requête. Nous avons ajouté une réaction de bot personnalisée à un message « Montrez-moi les performances Web ». Suivre le lien Slackbot ouvre une performance des points de terminaison Web ventilée par service.
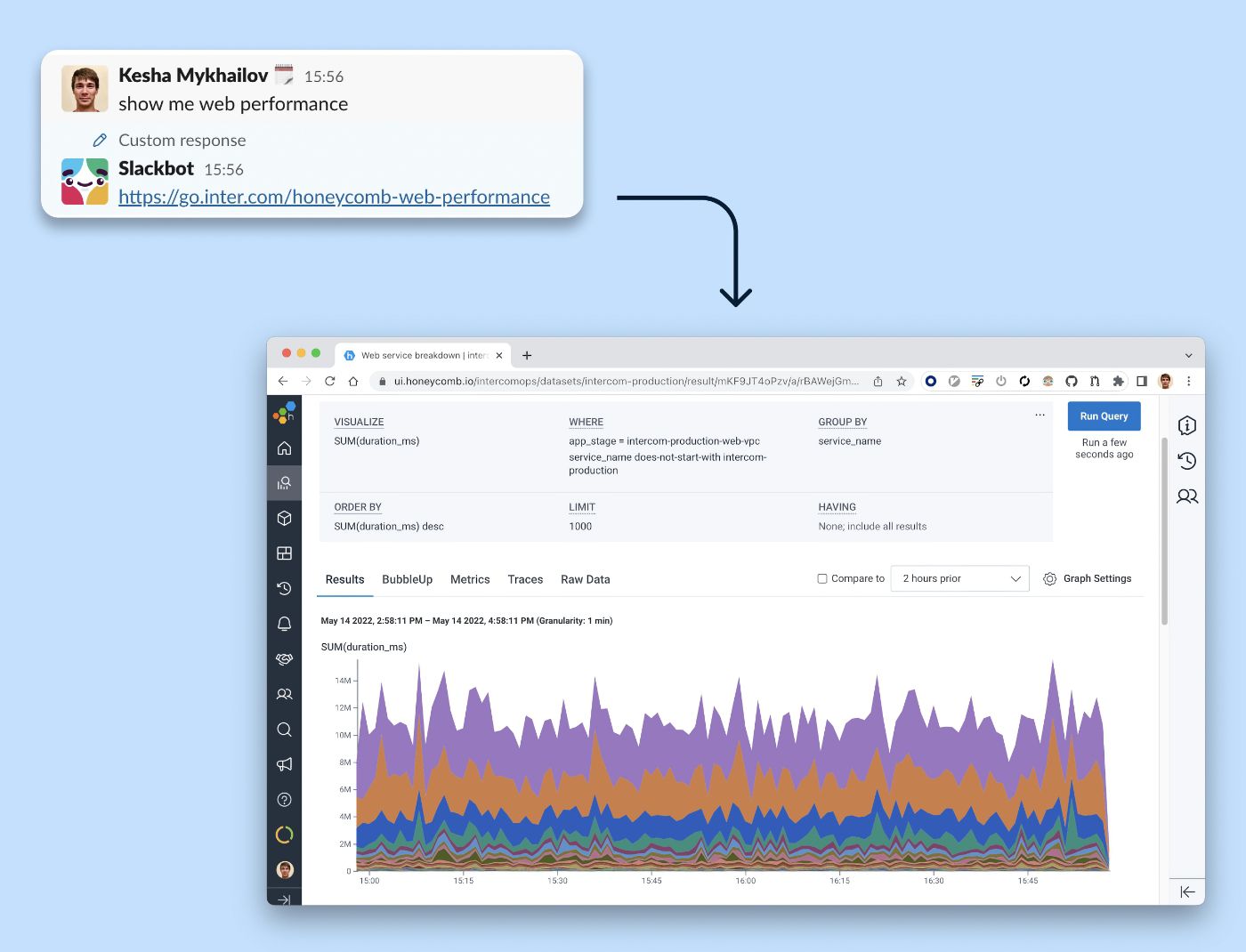
Nous rationalisons notre flux de travail d'observabilité avec un Slackbot qui fournit un raccourci vers une requête populaire dans notre outil d'observabilité
Étape 5 : Réflexions et prochaines étapes
Mesurer l'adoption
Mesurer le retour sur investissement (ROI) sur les outils d'observabilité est un défi. Le suivi du nombre d'utilisateurs actifs est un bon indicateur de la fréquence à laquelle les ingénieurs interagissent avec l'outillage, et nous avons beaucoup profité des mesures d'utilisation d'Honeycomb.

Ce graphique montre l'augmentation du nombre d'utilisateurs actifs d'Honeycomb depuis le début de l'activation de l'observabilité
Nous sommes allés plus loin et avons mesuré l'utilité de ces engagements. Nous avons postulé que si les informations obtenues grâce à l'outil d'observabilité étaient utiles, les gens les partageraient avec leurs pairs. Nos workflows d'ingénierie dépendent fortement des problèmes de Github, nous avons donc décidé de compter le nombre de problèmes ou de demandes d'extraction où Honeycomb était mentionné ou lié (trace, résultat de requête, etc.) comme proxy pour une métrique d'adoption. Alors que nous doublions l'activation vers la fin de 2021, nous avons observé une explosion du nombre de problèmes mentionnant Honeycomb, prouvant que nous étions sur la bonne voie.
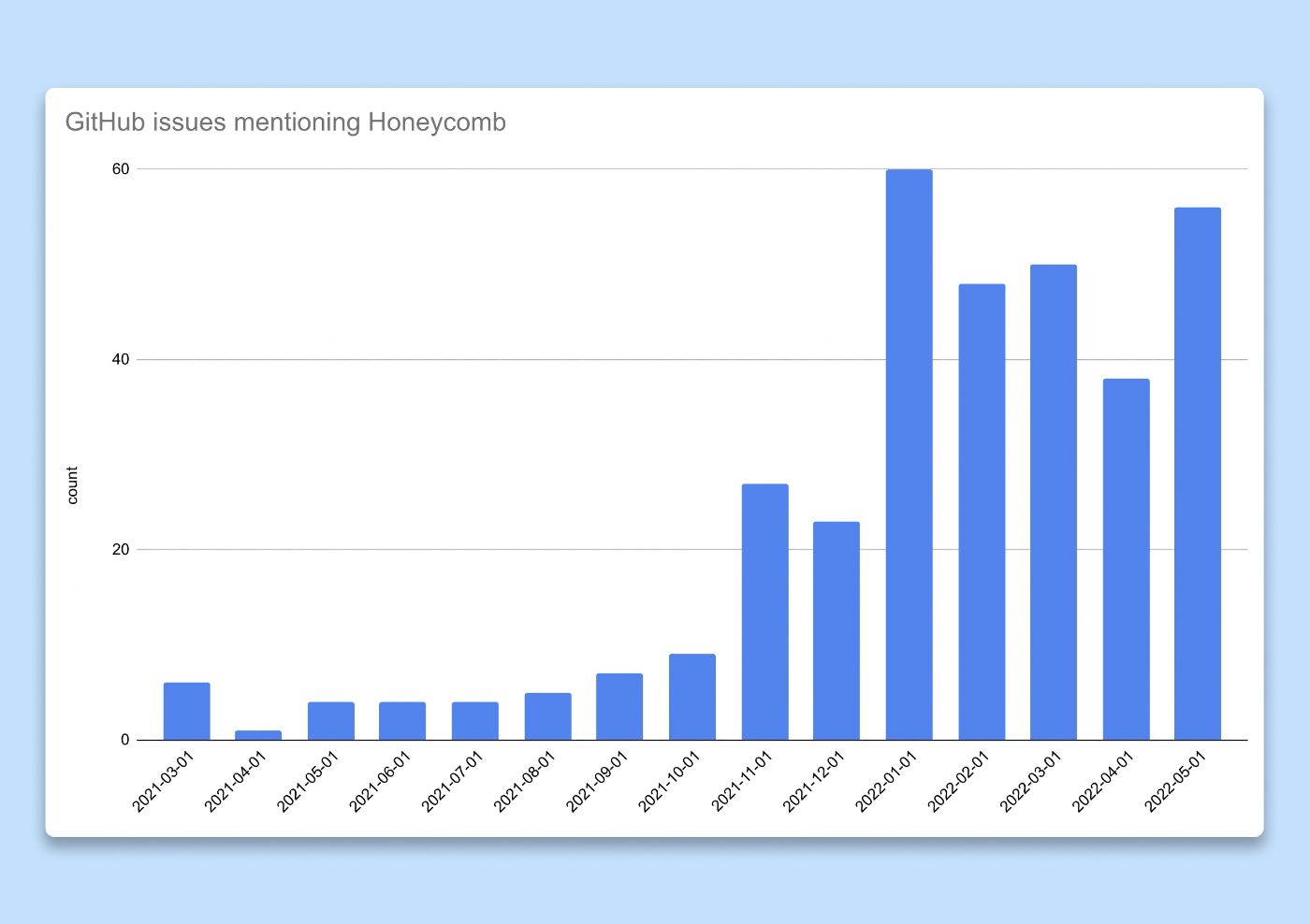
Graphique à barres montrant le nombre de problèmes GitHub où Honeycomb est mentionné dans le titre ou la description
Workflows inattendus
La construction d'une base d'observabilité solide a permis des flux de travail que nous n'aurions pas pu imaginer auparavant. Voici quelques-uns de nos choix favoris:
Programme d'information sur les coûts : étant donné que nous traçons tout le trafic et que nous disposons de plages pour les requêtes SQL, les requêtes Elasticsearch, etc., nous pouvons enquêter sur les pics d'utilisation de parties partagées distinctes de notre infrastructure (par exemple, un cluster de bases de données) et les attribuer à un seul client. En faisant correspondre ces données avec le coût des composants d'infrastructure individuels, nous pouvons mettre un prix approximatif sur chaque transaction que nous servons. L'observabilité est devenue de manière inattendue une partie intégrante de notre programme de coûts d'infrastructure.
Amélioration de l'audit de sécurité : Pouvoir conserver 100 % des transactions sélectionnées nous a permis de préserver toutes les interactions avec notre console de données de production, aidant la sécurité à établir une meilleure visibilité sur l'accès aux données de nos clients.
Et après?
Construire une culture d'observabilité continuera de faire partie de notre programme technique : nous nous concentrerons sur l'amélioration de notre matériel d'intégration, l'intégration de l'observabilité via des traces dans nos opérations de R&D et l'exploration de l'instrumentation frontale.
Vous souhaitez rejoindre notre équipe? Découvrez nos rôles d'ingénierie ouverts ici.
