
Construyendo un sistema resiliente: Nuestro viaje hacia la observabilidad en Intercom
Publicado: 2022-07-14En Intercom nos enfocamos en la experiencia del cliente por encima de todo: la disponibilidad y el rendimiento de nuestro servicio son nuestra principal prioridad. Eso requiere una sólida cultura de observabilidad en nuestros equipos y sistemas.
Como resultado, invertimos mucho en la confiabilidad de nuestra aplicación. Pero las fallas impredecibles son inevitables, y cuando ocurren, son los humanos quienes las solucionan.
Operamos un sistema socio-técnico, y su capacidad de recuperación frente a la adversidad se llama resiliencia. Uno de los componentes cruciales de la resiliencia es la observabilidad, los pasos que tomamos para permitir que los humanos "miren" dentro de los sistemas que ejecutan.
Esta publicación explorará el camino hacia la construcción de una cultura de observabilidad más sólida y las lecciones que hemos aprendido en el camino.
¿Qué entendemos por observabilidad en Intercom?
En Intercom, enviamos para aprender. Nuestro entorno de producción es donde nuestro código, infraestructura, dependencias de terceros y nuestros clientes se unen para crear una realidad objetiva: es el único lugar para aprender y validar el impacto de nuestro trabajo. Definimos la observabilidad como un proceso continuo de humanos que hacen preguntas sobre la producción y obtienen respuestas*.
Vamos a desglosarlo un poco más:
- Proceso continuo: la observabilidad exitosa significa que la gente observa con la mayor frecuencia posible.
- Preguntas sobre producción: Queríamos que nuestra definición fuera amplia, genérica y representativa de la amplia gama de flujos de trabajo que atendemos.
- Respuestas*: Nótese el asterisco. Ninguna herramienta le dará respuestas, solo le ofrecerá pistas que puede seguir para encontrar las respuestas reales. Tienes que usar tus propios modelos mentales y la comprensión de los sistemas que ejecutas.
Etapa 1: Problema y solución
Armados con nuestra propia definición de observabilidad, evaluamos nuestras prácticas existentes y formulamos una declaración del problema. Hasta hace poco, nuestras herramientas de observabilidad se basaban principalmente en métricas. Un flujo de trabajo típico consistía en mirar un tablero lleno de gráficos con métricas divididas y divididas en cubitos por varias combinaciones de atributos. La gente buscaría correlaciones, pero a menudo se iría sin conocer las ideas.
"Las métricas son fáciles de agregar y comprender, pero les faltan atributos de alta cardinalidad (por ejemplo, ID de cliente), lo que dificulta completar una investigación".
Las métricas son fáciles de agregar y comprender, pero les faltan atributos de alta cardinalidad (por ejemplo, ID de cliente), lo que dificulta completar una investigación. Anteriormente, un puñado de campeones de la observabilidad continuaría el flujo de trabajo utilizando herramientas secundarias (por ejemplo, registros, excepciones, etc.), tratando de acceder a la información de alta cardinalidad y construir una imagen más completa. Esa habilidad requería práctica constante, una pregunta poco realista para la mayoría de los ingenieros de productos que están ocupados entregando productos.
Identificamos esta falta de experiencia de observabilidad consolidada como un problema a resolver. Queríamos que fuera fácil para cualquier persona hacer una pregunta arbitraria sobre la producción y obtener información sin tener que dominar un conjunto de herramientas costosas, desconectadas y mal configuradas. Para mitigar el problema, decidimos duplicar el seguimiento de la telemetría.

Un tablero operativo típico que usamos antes de duplicar las trazas
¿Por qué huellas?
Cualquier herramienta de observabilidad es solo una herramienta con un humano detrás, y los humanos necesitan buenas visualizaciones. No importa qué tipo de datos impulse la visualización, solo que la herramienta le permite cambiar sin problemas entre diferentes visualizaciones y obtener perspectivas alternativas sobre el problema.
Los seguimientos tienen una gran ventaja sobre otros datos de telemetría: codifican suficiente información sobre las transacciones para potenciar prácticamente cualquier visualización. La creación de flujos de trabajo de observabilidad sobre los seguimientos garantiza una experiencia consolidada fluida sin necesidad de cambiar los datos subyacentes o la herramienta.
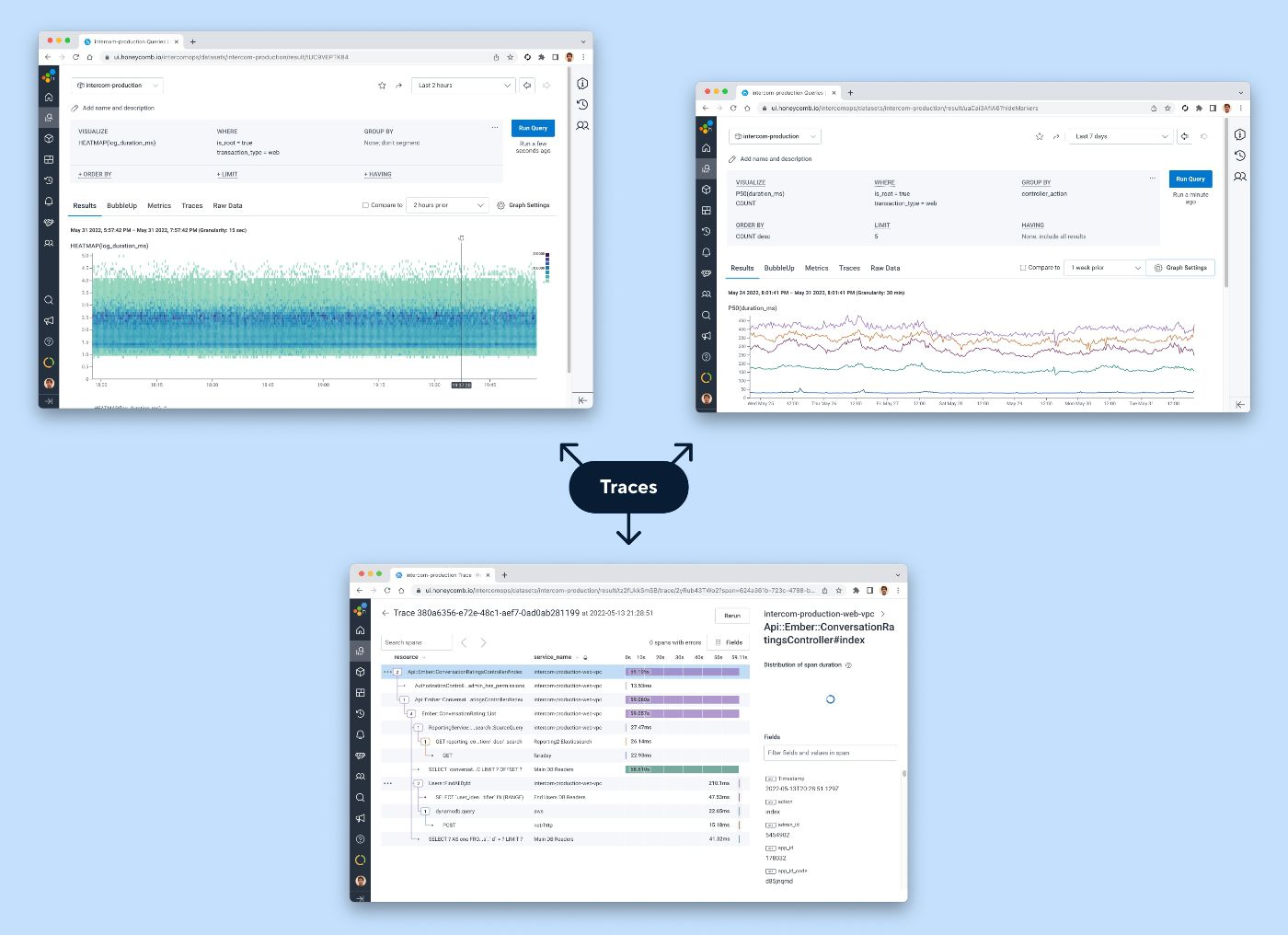
Algunos de los tipos de visualizaciones que pueden funcionar con seguimientos
Etapa 2: Implementación de seguimientos
En Intercom comenzamos poco a poco, decidiendo cómo se ve el éxito y monitoreando el progreso a lo largo del camino. Nuestro principal objetivo era confirmar que las trazas harían que los flujos de trabajo de observabilidad fueran más eficientes. Para eso, necesitábamos que los rastros llegaran a manos de los ingenieros lo antes posible.
“En lugar de instrumentar nuestra aplicación con seguimientos desde cero, utilizamos una biblioteca de seguimiento existente que ya estaba en las dependencias”
Para ahorrar tiempo, utilizamos nuestro proveedor existente, Honeycomb, para nuestra prueba de concepto. Ya habíamos construido una gran relación con ellos mientras usábamos su herramienta para eventos estructurados en el pasado.
En lugar de instrumentar nuestra aplicación con seguimientos desde cero, usamos una biblioteca de seguimiento existente que ya estaba en las dependencias y realizamos un pequeño ajuste para convertir los datos de seguimiento al formato nativo de Honeycomb. Comenzamos con un muestreo determinista simple, reteniendo ~1% de todas las transacciones que procesamos.
Permitir que los compañeros de equipo adopten seguimientos
Cambiar una organización hacia los rastros no es poca cosa. Los seguimientos son más complejos que las métricas o los registros y tienen una curva de aprendizaje pronunciada. La instrumentación, la canalización de datos y las herramientas son importantes, pero el mayor desafío es permitir que sus compañeros de equipo maximicen el uso de las trazas. Con nuestra prueba de concepto funcionando en producción, inmediatamente comenzamos a centrarnos en construir una cultura de observabilidad.
"No nos enfocamos solo en los ingenieros: hablamos con directores, gerentes de programas técnicos, miembros del equipo de seguridad y representantes de atención al cliente para enfatizar cómo los rastreos podrían ayudarlos a resolver sus problemas específicos".
Encontrar aliados fue clave para el éxito. Reunimos un grupo de campeones que ya eran expertos en observabilidad. Ayudaron a confirmar nuestras suposiciones y corrieron la voz sobre los rastros dentro de sus equipos. Pero no nos enfocamos solo en los ingenieros: hablamos con directores, gerentes de programas técnicos, miembros del equipo de seguridad y representantes de atención al cliente para enfatizar cómo los rastreos podrían ayudarlos a resolver sus problemas específicos.
Adaptar nuestro mensaje ayudó a asegurar el apoyo. La introducción de nuevas herramientas siempre conlleva un cierto riesgo: al demostrar el potencial y entusiasmar a la gente, aumentamos nuestras posibilidades de éxito.
Etapa 3: Decidir sobre el proveedor adecuado
Con el inicio del programa de habilitación, comenzamos a buscar proveedores modernos centrados en el rastreo y formulamos un conjunto de criterios para evaluar a los posibles candidatos.
Flujos de trabajo: identificamos el flujo de trabajo exploratorio como el más importante: permitiría a los ingenieros dividir y dividir arbitrariamente los datos de producción y obtener información a través de visualizaciones y atributos de alta cardinalidad. Una gran parte del diagnóstico de un problema es poder detectarlo, y eso significa comprender cómo se ve "normal". Queríamos facilitar a los ingenieros la exploración de la producción haciendo preguntas con la mayor frecuencia posible, no solo cuando surgen problemas.

“Queríamos un control total sobre la forma en que se muestreaban y retenían los datos”
Controles de muestreo y retención : Queríamos un control total sobre la forma en que los datos serían muestreados y retenidos. El muestreo determinista nos ayudó a ponernos en marcha rápidamente, pero queríamos ser más selectivos y retener más de los rastros "interesantes" (por ejemplo, errores, solicitudes lentas) utilizando un muestreo dinámico inteligente mientras permanecíamos por debajo del límite del contrato.
Visualizaciones de datos precisas : Queríamos asegurarnos de que, independientemente de la técnica de muestreo que usáramos, las herramientas de observabilidad lo manejaran de manera transparente al exponer números aproximados "verdaderos" en las visualizaciones. Cada proveedor abordó este problema de manera diferente: algunos requieren enviar todos los datos a un agregador global para inferir métricas para indicadores clave como la tasa de error, el volumen, etc. Esta no era una opción para nosotros dado el volumen masivo de datos generados por nuestra rica instrumentación.
Precios : Queríamos un esquema de precios simple y predecible que se correlacionara con el valor que obtendríamos de la herramienta. Cobrar por la cantidad de datos retenidos y expuestos parecía justo.
Métricas de compromiso : Queríamos que el proveedor fuera un buen socio y nos ayudara a rastrear la adopción y efectividad de la herramienta al exponer métricas de uso clave y niveles de compromiso.
No existe un proveedor perfecto, así que prepárese para hacer algunos compromisos. Al final, llegamos a la conclusión de que Honeycomb no solo funcionaba mejor para el flujo de trabajo principal que habíamos identificado, sino que también cumplía con los requisitos de muestreo, precios y métricas de uso, por lo que evitamos la costosa migración de proveedores.
Después de un año de trabajo desafiante, habíamos completado la parte técnica del programa de observabilidad. Esto es lo que habíamos conseguido:
- Nuestra principal aplicación de monolitos había sido instrumentada automáticamente con trazas ricas en atributos de alta calidad.
- Los ingenieros tenían un pequeño conjunto de métodos convenientes para agregar instrumentación personalizada a su código.
- Habíamos implementado Honeycomb Refinery para muestrear datos de forma dinámica y retener más rastros "interesantes". Alentamos a los ingenieros a configurar reglas de retención personalizadas para un control más granular. Para las transacciones más valiosas, y cuando era económicamente factible, ofrecimos una retención del 100 % para brindarles a las personas los datos que necesitaban.
Etapa 4: Aumento de la adopción
Después de comprometernos con Honeycomb y completar el trabajo en la canalización de datos, volvimos a centrarnos en la habilitación. Para construir una cultura de observabilidad, debe facilitar que las personas se unan. Estas son algunas de las formas en que ayudamos a los equipos a adoptar nuevas herramientas de observabilidad:
Seguimiento en el entorno de desarrollo
Para familiarizar a los ingenieros con la instrumentación de rastreo y alentarlos a agregarla a su código, ofrecimos rastreo opcional desde el entorno de desarrollo local con los rastreos expuestos en Honeycomb. Esto ayudó a la gente a visualizar nueva instrumentación personalizada exactamente de la misma manera que la verían cuando el código llegara a producción.
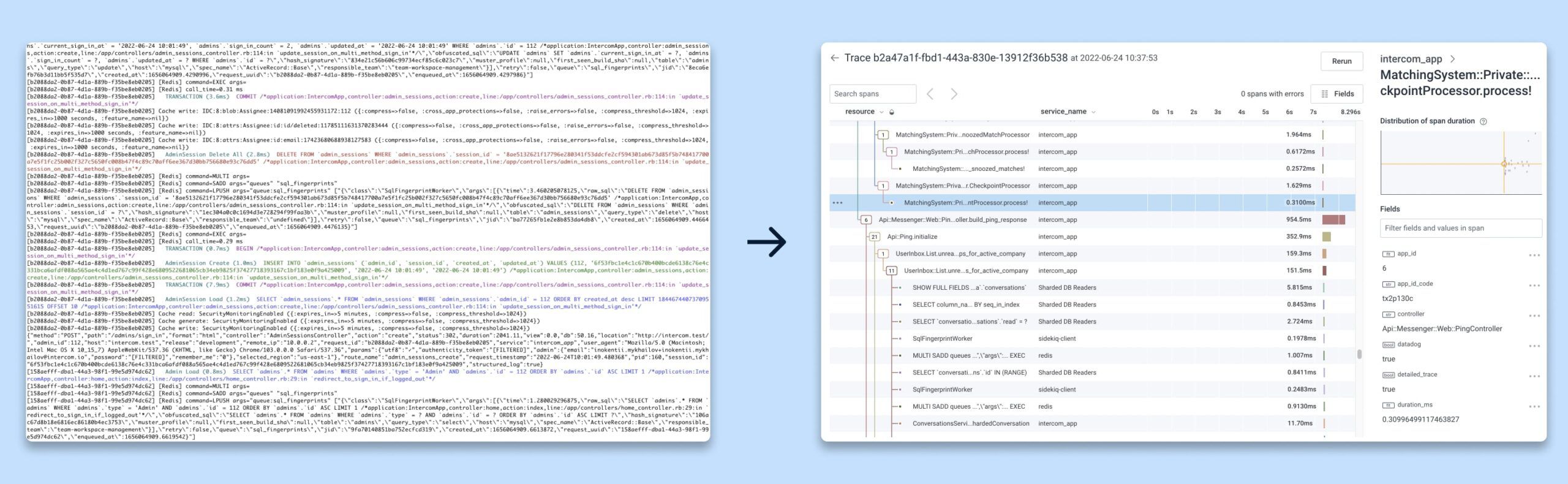
Los registros pueden ser difíciles de leer e interpretar, mientras que las vistas de seguimiento están mucho más estructuradas y organizadas.
Atajos de consulta de Slackbot
Cuando la producción tiene problemas, lo último que desea es tener que buscar la consulta correcta. Agregamos una reacción de bot personalizada al mensaje "Muéstrame el rendimiento web". Seguir el enlace de Slackbot abre un rendimiento de puntos finales web desglosado por servicio.
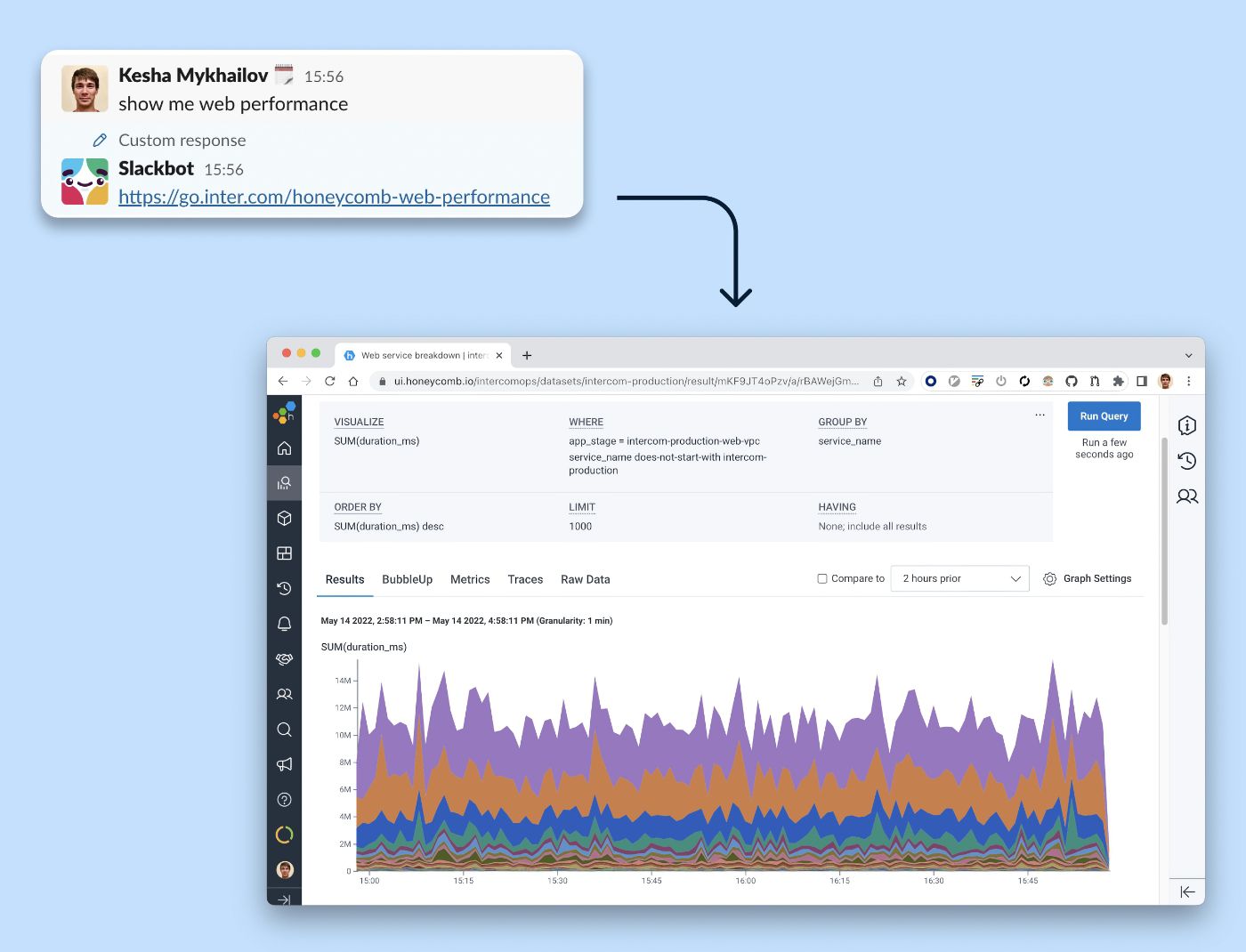
Agilizamos nuestro flujo de trabajo de observabilidad con un Slackbot que proporciona un acceso directo a una consulta popular dentro de nuestras herramientas de observabilidad.
Etapa 5: Reflexiones y próximos pasos
Medición de la adopción
Medir el retorno de la inversión (ROI) en las herramientas de observabilidad es un desafío. El seguimiento del número de usuarios activos es un buen indicador de la frecuencia con la que los ingenieros interactúan con las herramientas, y nos beneficiamos mucho de las métricas de uso de Honeycomb.

Este gráfico muestra el aumento en el número de usuarios activos de Honeycomb desde que comenzó la habilitación de la observabilidad
Fuimos más allá y medimos la utilidad de esos compromisos. Postulamos que si las ideas obtenidas de las herramientas de observabilidad fueran valiosas, las personas las compartirían con sus pares. Nuestros flujos de trabajo de ingeniería dependen en gran medida de los problemas de Github, por lo que decidimos contar la cantidad de problemas o solicitudes de extracción donde se mencionó o vinculó Honeycomb (rastreo, resultado de la consulta, etc.) como un proxy para una métrica de adopción. A medida que duplicamos la habilitación hacia fines de 2021, observamos una explosión en la cantidad de problemas que mencionan Honeycomb, lo que demuestra que estábamos en el camino correcto.
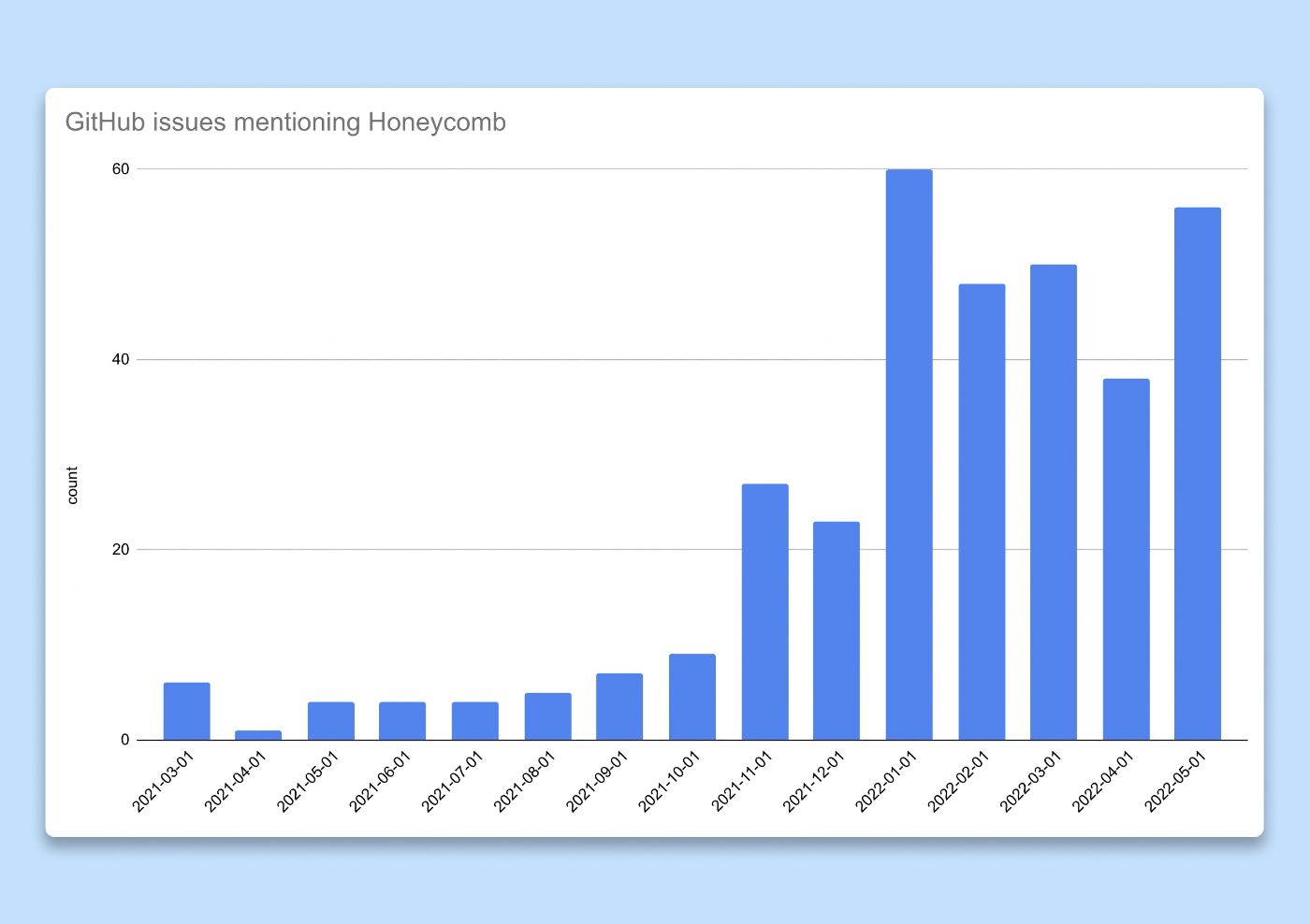
Gráfico de barras que muestra la cantidad de problemas de GitHub en los que se menciona Honeycomb en el título o la descripción
Flujos de trabajo inesperados
Construir una base sólida de observabilidad permitió flujos de trabajo que no podíamos haber imaginado antes. Estos son algunos de nuestros favoritos:
Programa de costos informativos : debido a que rastreamos todo el tráfico y tenemos tramos para consultas SQL, solicitudes de Elasticsearch, etc., podemos investigar picos en la utilización de partes compartidas separadas de nuestra infraestructura (por ejemplo, clúster de base de datos) y atribuirlas a un solo cliente. Haciendo coincidir estos datos con el costo de los componentes de infraestructura individuales, podemos poner una etiqueta de precio aproximado en cada transacción que atendemos. La observabilidad se ha convertido inesperadamente en un componente integral de nuestro programa de costos de infraestructura.
Mejora de la auditoría de seguridad : Poder retener el 100 % de las transacciones seleccionadas nos ha permitido preservar todas las interacciones con nuestra consola de datos de producción, lo que ayuda a la seguridad a establecer una mejor visibilidad sobre el acceso a los datos de nuestros clientes.
¿Que sigue?
La construcción de una cultura de observabilidad seguirá siendo parte de nuestro programa técnico: nos centraremos en mejorar nuestro material de incorporación, entretejiendo aún más la observabilidad a través de trazas en nuestras operaciones de I+D y explorando la instrumentación de front-end.
¿Interesado en unirte a nuestro equipo? Consulte nuestros puestos abiertos de ingeniería aquí.
