
Budowanie odpornego systemu: Nasza podróż do obserwowalności w Intercomie
Opublikowany: 2022-07-14W Intercom skupiamy się przede wszystkim na doświadczeniu klienta – dostępność i wydajność naszych usług jest naszym najwyższym priorytetem. Wymaga to silnej kultury obserwowalności w naszych zespołach i systemach.
Dzięki temu dużo inwestujemy w niezawodność naszej aplikacji. Ale nieprzewidywalne awarie są nieuniknione, a kiedy się zdarzają, to ludzie je naprawiają.
Działamy w systemie socjotechnicznym, a jego zdolność do regeneracji w obliczu przeciwności nazywamy odpornością. Jednym z kluczowych elementów odporności jest obserwowalność, kroki, które podejmujemy, aby umożliwić ludziom „zajrzenie” do wnętrza systemów, które prowadzą.
W tym poście omówimy drogę do budowania silniejszej kultury obserwowalności oraz wnioski, których nauczyliśmy się po drodze.
Co rozumiemy przez obserwowalność w Intercomie?
W Intercom wysyłamy do nauki. Nasze środowisko produkcyjne to miejsce, w którym nasz kod, infrastruktura, zależności od stron trzecich i nasi klienci spotykają się, aby stworzyć obiektywną rzeczywistość — to jedyne miejsce, w którym można uczyć się i sprawdzać wpływ naszej pracy. Definiujemy obserwowalność jako ciągły proces, w którym ludzie zadają pytania dotyczące produkcji i uzyskują odpowiedzi*.
Rozłóżmy to trochę bardziej:
- Ciągły proces: Udana obserwowalność oznacza, że ludzie obserwują tak często, jak to możliwe.
- Pytania dotyczące produkcji: Chcieliśmy, aby nasza definicja była szeroka, ogólna i reprezentatywna dla szerokiego zakresu przepływów pracy, które obsługujemy.
- Odpowiedzi*: Zwróć uwagę na gwiazdkę. Żadne narzędzie nie da ci odpowiedzi, tylko proponuj leady, za którymi możesz podążać, aby znaleźć prawdziwe odpowiedzi. Musisz użyć własnych modeli mentalnych i zrozumienia systemów, którymi kierujesz.
Etap 1: Problem i rozwiązanie
Uzbrojeni we własną definicję obserwowalności, oceniliśmy nasze dotychczasowe praktyki i sformułowaliśmy opis problemu. Do niedawna nasze narzędzia do obserwowania opierały się głównie na metrykach. Typowy przepływ pracy obejmował przeglądanie pulpitu nawigacyjnego pełnego wykresów z metrykami podzielonymi na różne kombinacje atrybutów. Ludzie szukaliby korelacji, ale często odchodzili bez spełnienia spostrzeżeń.
„Dane są łatwe do dodania i zrozumienia, ale brakuje im atrybutów o wysokiej kardynalności (np. Identyfikatora klienta), co utrudnia zakończenie dochodzenia”
Metryki są łatwe do dodania i zrozumienia, ale brakuje w nich atrybutów o wysokiej kardynalności (np. identyfikatora klienta), co utrudnia zakończenie dochodzenia. Wcześniej garstka mistrzów obserwowalności kontynuowała przepływ pracy, korzystając z narzędzi pomocniczych (np. dzienników, wyjątków itp.), próbując uzyskać dostęp do informacji o wysokiej kardynalności i zbudować pełniejszy obraz. Ta umiejętność wymagała ciągłej praktyki – nierealne pytanie dla większości inżynierów produktu, którzy są zajęci dostarczaniem produktu.
Zidentyfikowaliśmy ten brak skonsolidowanego doświadczenia w zakresie obserwowalności jako problem do rozwiązania. Chcieliśmy, aby każdy mógł łatwo zadać dowolne pytanie na temat produkcji i uzyskać wgląd bez konieczności opanowania zestawu rozłączonych, niedostatecznie skonfigurowanych i kosztownych narzędzi. Aby złagodzić ten problem, zdecydowaliśmy się podwoić śledzenie telemetrii.

Typowy pulpit operacyjny, którego używaliśmy przed podwojeniem śladów
Dlaczego ślady?
Każde narzędzie do obserwacji to tylko narzędzie, za którym stoi człowiek – a ludzie potrzebują dobrych wizualizacji. Nie ma znaczenia, jaki rodzaj danych zasila wizualizację, wystarczy, że narzędzie pozwala płynnie przełączać się między różnymi wizualizacjami i uzyskiwać alternatywne perspektywy problemu.
Ślady mają ogromną przewagę nad innymi danymi telemetrycznymi — kodują wystarczającą ilość informacji o transakcjach, aby zasilać praktycznie każdą wizualizację. Budowanie przepływów pracy umożliwiających obserwowanie na podstawie śladów zapewnia płynne, skonsolidowane środowisko bez konieczności przełączania podstawowych danych lub narzędzia.
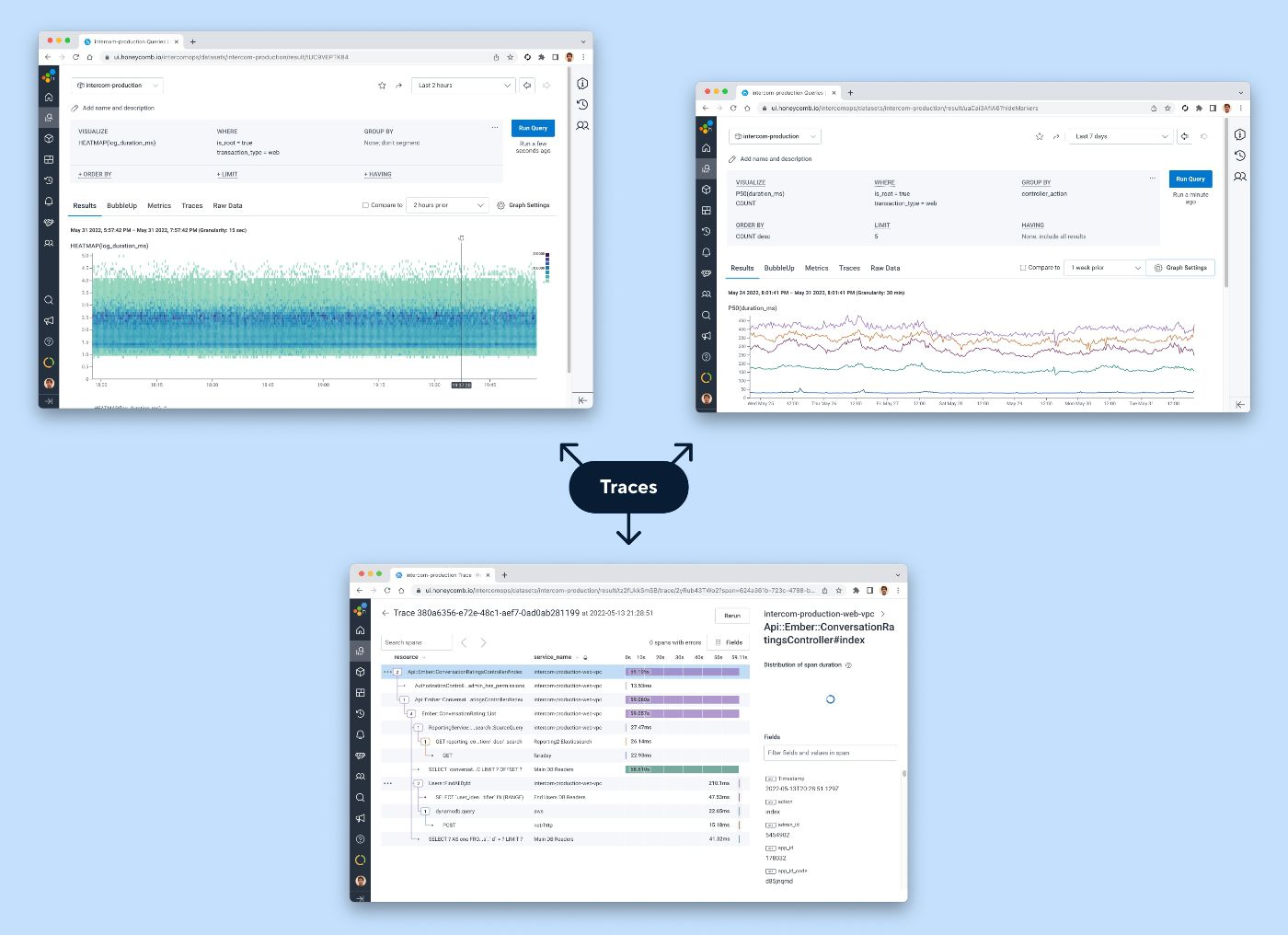
Niektóre rodzaje wizualizacji, które mogą być zasilane śladami
Etap 2: Implementacja śladów
W Intercom zaczynamy od małych, decydując o tym, jak wygląda sukces i monitorując postępy po drodze. Naszym głównym celem było potwierdzenie, że ślady sprawią, że przepływy pracy związane z obserwowalnością będą bardziej wydajne. W tym celu musieliśmy jak najszybciej przekazać ślady w ręce inżynierów.
„Zamiast oprzyrządować naszą aplikację śladami od zera, wykorzystaliśmy istniejącą bibliotekę śledzenia, która akurat znajdowała się już w zależnościach”
Aby zaoszczędzić czas, wykorzystaliśmy naszego dotychczasowego dostawcę, Honeycomb, do weryfikacji koncepcji. Już w przeszłości zbudowaliśmy z nimi świetne relacje, korzystając z ich narzędzia do zorganizowanych wydarzeń.
Zamiast oprzyrządować naszą aplikację śladami od zera, użyliśmy istniejącej biblioteki śledzenia, która akurat znajdowała się już w zależnościach, i wykonaliśmy niewielką korektę, aby przekonwertować dane śledzenia do formatu Honeycomb-natywnego. Zaczęliśmy od prostego próbkowania deterministycznego, zachowując ~1% wszystkich przetworzonych transakcji.
Umożliwienie członkom drużyny adopcji śladów
Przesuwanie organizacji w stronę śladów to nie lada wyczyn. Ślady są bardziej złożone niż metryki lub dzienniki i wymagają stromej krzywej uczenia się. Instrumenty, potok danych i narzędzia są ważne, ale największym wyzwaniem jest umożliwienie członkom zespołu maksymalizacji wykorzystania śladów. Dzięki naszemu proof-of-concept uruchomionemu na produkcji, natychmiast zaczęliśmy koncentrować się na budowaniu kultury obserwowalności.
„Nie skupialiśmy się tylko na inżynierach – rozmawialiśmy z dyrektorami, kierownikami programów technicznych, członkami zespołu ds. bezpieczeństwa i przedstawicielami obsługi klienta, aby podkreślić, w jaki sposób ślady mogą pomóc im rozwiązać ich konkretne problemy”
Kluczem do sukcesu było znalezienie sojuszników. Zebraliśmy grupę mistrzów, którzy byli już wykwalifikowani w obserwowalności. Pomogli potwierdzić nasze przypuszczenia i rozpowszechnić informacje o śladach w swoich zespołach. Ale nie skupiliśmy się tylko na inżynierach — rozmawialiśmy z dyrektorami, kierownikami programów technicznych, członkami zespołu ds. bezpieczeństwa i przedstawicielami obsługi klienta, aby podkreślić, jak ślady mogą pomóc im rozwiązać ich konkretne problemy.
Dostosowanie naszego przekazu pomogło w uzyskaniu wsparcia. Wprowadzanie nowego oprzyrządowania zawsze niesie ze sobą pewne ryzyko – demonstrując potencjał i podniecając ludzi, zwiększyliśmy nasze szanse na sukces.
Etap 3: Wybór właściwego dostawcy
Po uruchomieniu programu wdrożeniowego zaczęliśmy przyglądać się nowoczesnym dostawcom zorientowanym na śledzenie i sformułowaliśmy zestaw kryteriów do oceny potencjalnych kandydatów.
Przepływy pracy : Zidentyfikowaliśmy przepływ pracy eksploracyjnej jako najważniejszy – umożliwiłby inżynierom arbitralne krojenie i wycinanie danych produkcyjnych oraz uzyskiwanie wglądu za pomocą wizualizacji i atrybutów o wysokiej kardynalności. Dużą częścią diagnozowania problemu jest możliwość jego wykrycia, a to oznacza zrozumienie, jak wygląda „normalny”. Chcieliśmy ułatwić inżynierom eksplorację produkcji poprzez zadawanie pytań tak często, jak to możliwe, a nie tylko wtedy, gdy pojawiają się problemy.

„Chcieliśmy mieć pełną kontrolę nad sposobem próbkowania i przechowywania danych”
Kontrola próbkowania i przechowywania : Chcieliśmy mieć pełną kontrolę nad sposobem próbkowania i przechowywania danych. Próbkowanie deterministyczne pomogło nam szybko rozpocząć pracę, ale chcieliśmy być bardziej selektywni i zachować więcej „interesujących” śladów (np. błędów, powolnych żądań) przy użyciu inteligentnego próbkowania dynamicznego, pozostając jednocześnie poniżej limitu umowy.
Dokładne wizualizacje danych : Chcieliśmy się upewnić, że niezależnie od zastosowanej techniki próbkowania, narzędzia do obserwowalności obsługiwały to w przejrzysty sposób, eksponując „prawdziwe” przybliżone liczby w wizualizacjach. Każdy dostawca inaczej podszedł do tego problemu – niektórzy wymagają przesłania wszystkich danych do globalnego agregatora, aby wywnioskować metryki dla kluczowych wskaźników, takich jak poziom błędów, wolumen itp. Nie było to dla nas rozwiązaniem, biorąc pod uwagę ogromną ilość danych generowanych przez nasze bogate oprzyrządowanie.
Ceny : chcieliśmy mieć prosty, przewidywalny schemat cenowy, który korelowałby z wartością, jaką otrzymalibyśmy z narzędzia. Pobieranie opłat za ilość przechowywanych i ujawnianych danych wydawało się sprawiedliwe.
Wskaźniki zaangażowania : Chcieliśmy, aby dostawca był dobrym partnerem i pomagał nam śledzić wdrażanie i skuteczność narzędzia, ujawniając kluczowe wskaźniki użycia i poziomy zaangażowania.
Nie ma idealnego dostawcy, więc bądź gotowy na pewne kompromisy. Ostatecznie doszliśmy do wniosku, że Honeycomb nie tylko działał lepiej w przypadku zidentyfikowanego przez nas głównego przepływu pracy, ale także zaznaczyliśmy pola próbkowania, cen i wskaźników użytkowania – dzięki czemu uniknęliśmy kosztownej migracji dostawców.
Po trudnym roku pracy zakończyliśmy techniczną część programu obserwowalności. Oto, co osiągnęliśmy:
- Nasza główna aplikacja monolitu została wyposażona w automatyczne oprzyrządowanie z wysokiej jakości, bogatymi w atrybuty śladami.
- Inżynierowie mieli mały zestaw wygodnych metod dodawania niestandardowej instrumentacji do swojego kodu.
- Wdrożyliśmy Honeycomb Refinery, aby dynamicznie próbkować dane i zachować więcej „interesujących” śladów. Zachęcaliśmy inżynierów do skonfigurowania niestandardowych reguł przechowywania w celu uzyskania bardziej szczegółowej kontroli. W przypadku najbardziej wartościowych transakcji, gdy było to ekonomicznie wykonalne, oferowaliśmy 100% retencji, aby zapewnić użytkownikom potrzebne dane.
Etap 4: Zwiększenie adopcji
Po zaangażowaniu się w Honeycomb i zakończeniu prac nad potokiem danych skoncentrowaliśmy się z powrotem na włączaniu. Aby zbudować kulturę obserwowalności, musisz ułatwić ludziom wejście na pokład. Oto kilka sposobów, w jakie pomogliśmy zespołom wdrożyć nowe narzędzia do obserwacji:
Śledzenie w środowisku programistycznym
Aby zapoznać inżynierów z oprzyrządowaniem do śledzenia i zachęcić ich do dodania go do kodu, zaoferowaliśmy opcjonalne śledzenie z lokalnego środowiska programistycznego ze śladami widocznymi w Honeycomb. Pomogło to ludziom zwizualizować nowe niestandardowe oprzyrządowanie w dokładnie taki sam sposób, w jaki zobaczyliby je, gdy kod trafi do produkcji.
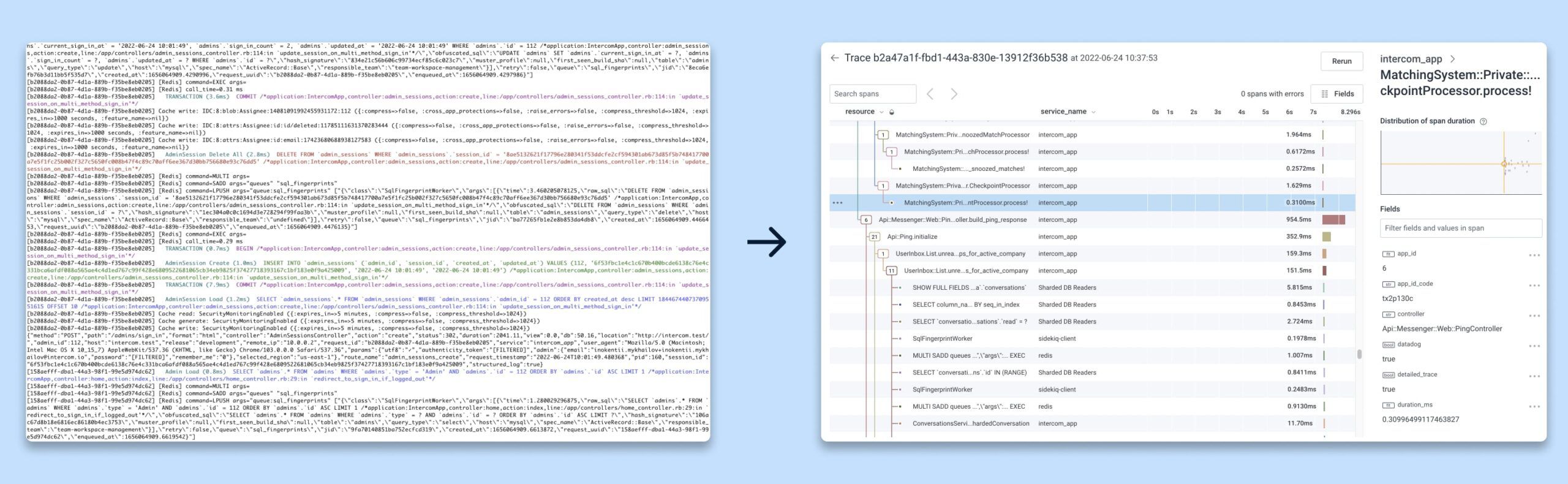
Dzienniki mogą być trudne do odczytania i interpretacji, podczas gdy widoki śladów są znacznie bardziej ustrukturyzowane i zorganizowane
Skróty zapytań Slackbota
Gdy produkcja jest w tarapatach, ostatnią rzeczą, jakiej chcesz, jest konieczność szukania właściwego zapytania. Dodaliśmy niestandardową reakcję bota do komunikatu „pokaż mi wydajność sieci”. Podążanie za linkiem Slackbot otwiera wydajność punktów końcowych sieci z podziałem na usługi.
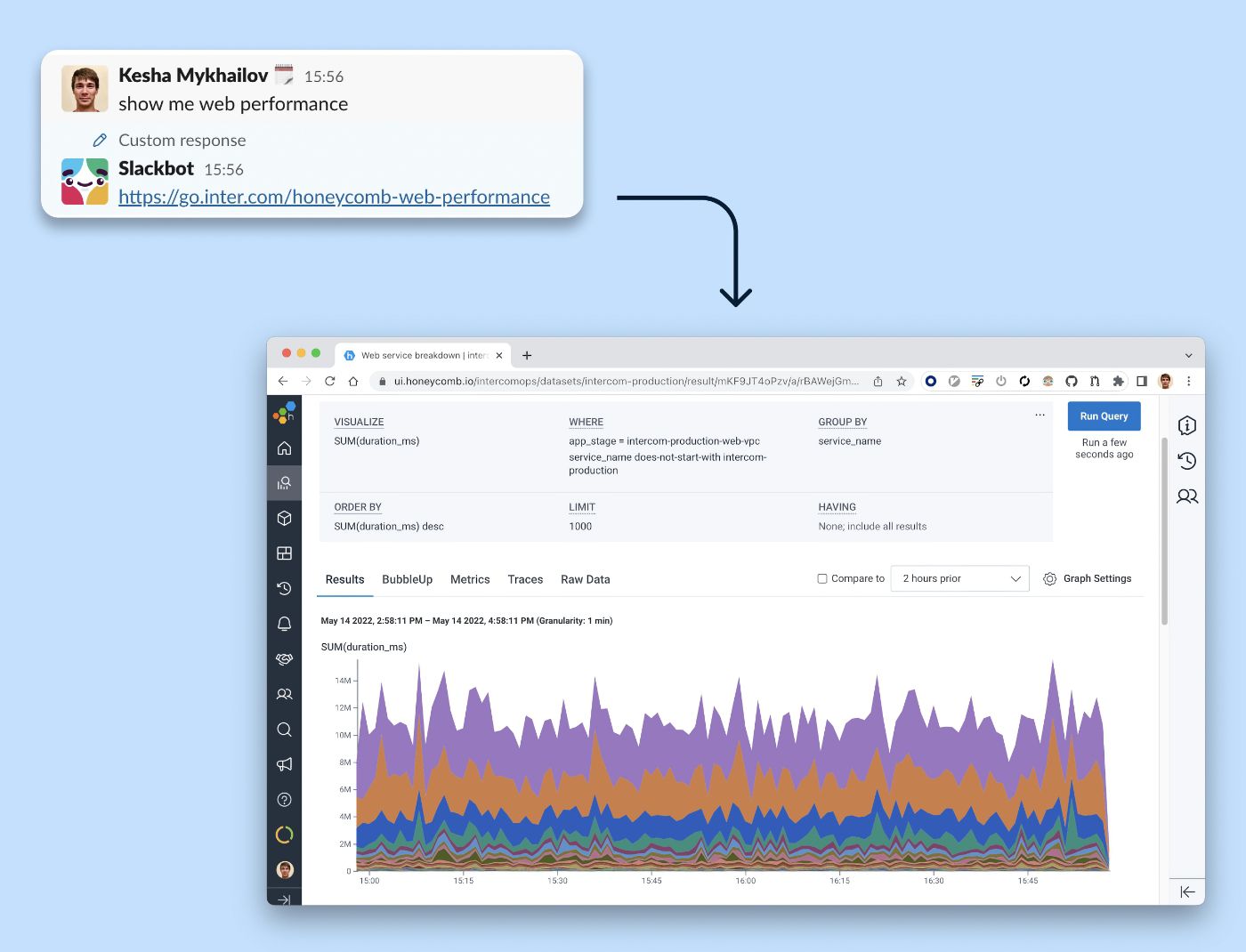
Usprawniamy nasz przepływ pracy w zakresie obserwowalności za pomocą Slackbota, który zapewnia skrót do popularnego zapytania w naszym narzędziu do obserwacji
Etap 5: Refleksje i kolejne kroki
Przyjęcie pomiaru
Mierzenie zwrotu z inwestycji (ROI) w narzędzia do obserwacji jest trudne. Śledzenie liczby aktywnych użytkowników jest dobrym wskaźnikiem tego, jak często inżynierowie angażują się w narzędzia, a my wiele skorzystaliśmy z metryk użytkowania Honeycomb.

Ten wykres pokazuje wzrost liczby aktywnych użytkowników Honeycomb od rozpoczęcia włączania obserwowalności
Poszliśmy dalej i zmierzyliśmy przydatność tych zadań. Postulowaliśmy, że jeśli spostrzeżenia uzyskane z narzędzi do obserwacji są cenne, ludzie podzielą się nimi z rówieśnikami. Nasze przepływy pracy inżynieryjne w dużym stopniu zależą od problemów z Github, więc zdecydowaliśmy się policzyć liczbę problemów lub żądań ściągnięcia, w których wspomniano lub powiązano Honeycomb (śledzenie, wynik zapytania itp.) jako proxy dla metryki przyjęcia. Gdy podwoiliśmy włączanie pod koniec 2021 roku, zaobserwowaliśmy eksplozję liczby problemów z wzmianką o plastrze miodu, co dowodzi, że jesteśmy na dobrej drodze.
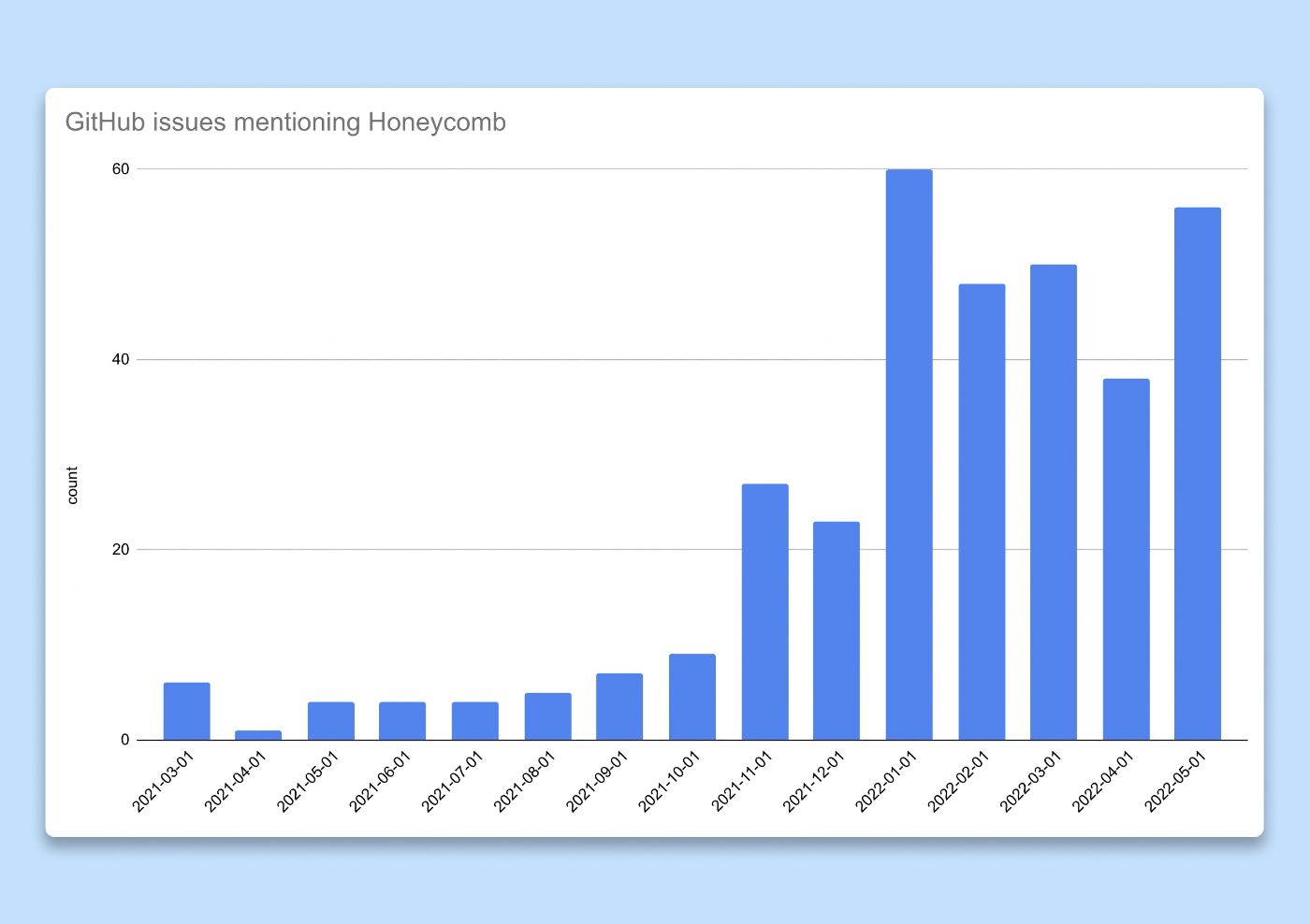
Wykres słupkowy pokazujący liczbę problemów z GitHub, w których Honeycomb jest wymieniony w tytule lub opisie
Nieoczekiwane przepływy pracy
Zbudowanie solidnej podstawy obserwowalności umożliwiło przepływy pracy, których wcześniej nie mogliśmy sobie wyobrazić. Oto kilka naszych ulubionych:
Program informowania o kosztach : Ponieważ śledzimy cały ruch i posiadamy zasięgi dla zapytań SQL, żądań Elasticsearch, itp., możemy badać skoki wykorzystania osobnych, współdzielonych części naszej infrastruktury (np. klastra bazy danych) i przypisywać je do jednego klienta. Dopasowując te dane do kosztu poszczególnych elementów infrastruktury, możemy na każdej obsługiwanej przez nas transakcji umieścić przybliżoną cenę. Obserwowalność niespodziewanie stała się integralną częścią naszego programu kosztów infrastruktury.
Poprawa audytu bezpieczeństwa : Możliwość zachowania 100% wybranych transakcji pozwoliła nam zachować wszystkie interakcje z naszą konsolą danych produkcyjnych, pomagając bezpieczeństwu w zapewnieniu lepszej widoczności dostępu do danych naszych klientów.
Co dalej?
Budowanie kultury obserwowalności będzie nadal częścią naszego programu technicznego: skoncentrujemy się na ulepszaniu naszego materiału wprowadzającego, dalszym wplataniu obserwowalności za pomocą śladów do naszych działań badawczo-rozwojowych oraz eksploracji oprzyrządowania front-end.
Chcesz dołączyć do naszego zespołu? Sprawdź nasze otwarte role inżynierskie tutaj.
