
Aufbau eines belastbaren Systems: Unser Weg zur Observability bei Intercom
Veröffentlicht: 2022-07-14Bei Intercom konzentrieren wir uns vor allem auf das Kundenerlebnis – die Verfügbarkeit und Leistung unseres Dienstes hat für uns oberste Priorität. Das erfordert eine starke Kultur der Beobachtbarkeit in unseren Teams und Systemen.
Daher investieren wir viel in die Zuverlässigkeit unserer Anwendung. Aber unvorhersehbare Ausfälle sind unvermeidlich, und wenn sie passieren, sind es die Menschen, die sie beheben.
Wir betreiben ein soziotechnisches System, und seine Fähigkeit, sich angesichts von Widrigkeiten zu erholen, wird Resilienz genannt. Eine der entscheidenden Komponenten der Resilienz ist die Beobachtbarkeit, die Schritte, die wir unternehmen, damit Menschen in die von ihnen betriebenen Systeme „hineinschauen“ können.
Dieser Beitrag wird den Weg zum Aufbau einer stärkeren Kultur der Beobachtbarkeit und die Lektionen, die wir auf diesem Weg gelernt haben, untersuchen.
Was verstehen wir unter Beobachtbarkeit bei Intercom?
Bei Intercom versenden wir, um zu lernen. Unsere Produktionsumgebung ist der Ort, an dem unser Code, unsere Infrastruktur, Abhängigkeiten von Drittanbietern und unsere Kunden zusammenkommen, um eine objektive Realität zu schaffen – es ist der einzige Ort, um die Auswirkungen unserer Arbeit zu erfahren und zu validieren. Wir definieren Beobachtbarkeit als einen kontinuierlichen Prozess, bei dem Menschen Fragen zur Produktion stellen und Antworten bekommen*.
Lassen Sie uns das etwas weiter aufschlüsseln:
- Kontinuierlicher Prozess: Erfolgreiche Beobachtbarkeit bedeutet, dass die Leute so oft wie möglich beobachten.
- Fragen zur Produktion: Wir wollten, dass unsere Definition breit, generisch und repräsentativ für das breite Spektrum der von uns abgedeckten Arbeitsabläufe ist.
- Antworten*: Beachten Sie das Sternchen. Kein Tool gibt Ihnen Antworten, sondern bietet nur Hinweise, denen Sie folgen können, um die wirklichen Antworten zu finden. Sie müssen Ihre eigenen mentalen Modelle und Ihr eigenes Verständnis der von Ihnen betriebenen Systeme verwenden.
Stufe 1: Problem und Lösung
Bewaffnet mit unserer eigenen Definition von Beobachtbarkeit haben wir unsere bestehenden Praktiken bewertet und eine Problemstellung formuliert. Bis vor kurzem basierten unsere Observability-Tools hauptsächlich auf Metriken. Ein typischer Arbeitsablauf bestand darin, sich ein Dashboard voller Diagramme mit Metriken anzusehen, die nach verschiedenen Attributkombinationen aufgeteilt und gewürfelt wurden. Die Leute suchten nach Korrelationen, gingen aber oft ohne erfüllende Erkenntnisse.
„Metriken sind einfach hinzuzufügen und zu verstehen, aber ihnen fehlen Attribute mit hoher Kardinalität (z. B. Kunden-ID), was es schwierig macht, eine Untersuchung abzuschließen.“
Metriken sind einfach hinzuzufügen und zu verstehen, aber ihnen fehlen Attribute mit hoher Kardinalität (z. B. Kunden-ID), was es schwierig macht, eine Untersuchung abzuschließen. Früher setzte eine Handvoll Observability-Champions den Workflow mit sekundären Tools (z. B. Protokollen, Ausnahmen usw.) fort und versuchte, auf die Informationen mit hoher Kardinalität zuzugreifen und ein vollständigeres Bild zu erstellen. Diese Fähigkeit erforderte ständiges Üben – eine unrealistische Forderung für die Mehrheit der Produktingenieure, die damit beschäftigt sind, Produkte zu liefern.
Wir haben diesen Mangel an konsolidierter Beobachtbarkeitserfahrung als ein zu lösendes Problem identifiziert. Wir wollten, dass es für jeden einfach ist, eine willkürliche Frage zur Produktion zu stellen und Einblicke zu erhalten, ohne eine Reihe von unzusammenhängenden, unzureichend eingerichteten und teuren Tools beherrschen zu müssen. Um das Problem zu entschärfen, haben wir uns entschieden, die Tracing-Telemetrie zu verdoppeln.

Ein typisches operatives Dashboard, das wir verwendet haben, bevor wir uns auf Traces konzentriert haben
Warum Spuren?
Jedes Observability-Tool ist nur ein Tool, hinter dem ein Mensch steht – und Menschen brauchen gute Visualisierungen. Es spielt keine Rolle, welche Art von Daten die Visualisierung antreibt, nur dass Sie mit dem Tool nahtlos zwischen verschiedenen Visualisierungen wechseln und alternative Perspektiven auf das Problem erhalten können.
Traces haben einen enormen Vorteil gegenüber anderen Telemetriedaten – sie kodieren genügend Informationen über Transaktionen, um praktisch jede Visualisierung zu unterstützen. Das Erstellen von Beobachtbarkeits-Workflows auf der Grundlage von Ablaufverfolgungen gewährleistet ein reibungsloses, konsolidiertes Erlebnis, ohne dass die zugrunde liegenden Daten oder das Tool gewechselt werden müssen.
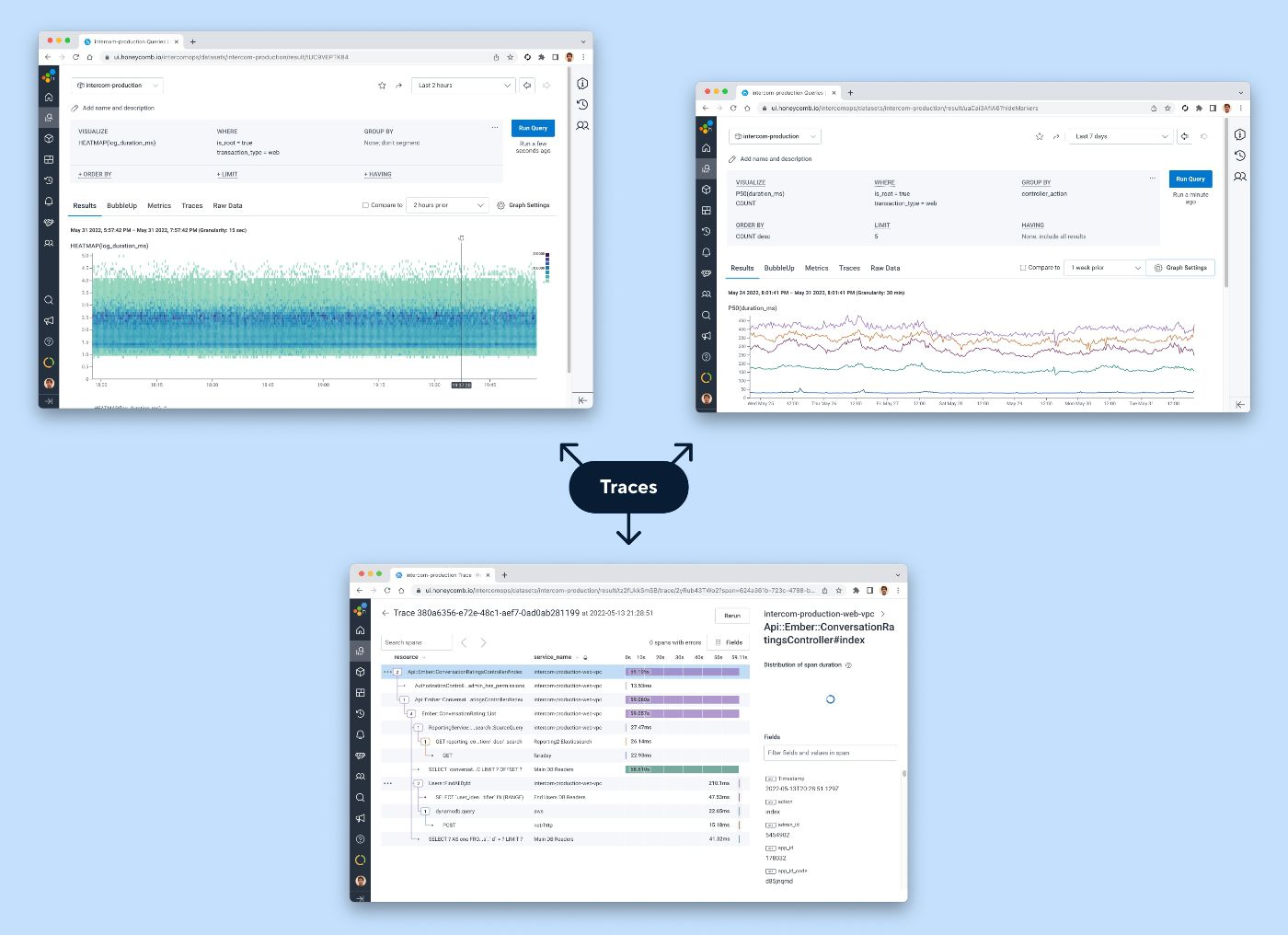
Einige der Arten von Visualisierungen, die durch Ablaufverfolgungen unterstützt werden können
Stufe 2: Implementieren von Ablaufverfolgungen
Bei Intercom fangen wir klein an, entscheiden, wie der Erfolg aussieht, und überwachen den Fortschritt auf dem Weg. Unser Hauptziel war es, zu bestätigen, dass Traces Beobachtbarkeits-Workflows effizienter machen würden. Dafür mussten wir Spuren so schnell wie möglich in die Hände von Ingenieuren bringen.
„Anstatt unsere Anwendung von Grund auf mit Ablaufverfolgungen zu instrumentieren, haben wir eine vorhandene Ablaufverfolgungsbibliothek verwendet, die sich zufällig bereits in den Abhängigkeiten befand.“
Um Zeit zu sparen, haben wir unseren bestehenden Anbieter Honeycomb für unseren Proof-of-Concept verwendet. Wir hatten bereits eine großartige Beziehung zu ihnen aufgebaut, als wir ihr Tool in der Vergangenheit für strukturierte Events nutzten.
Anstatt unsere Anwendung von Grund auf mit Ablaufverfolgungen zu instrumentieren, haben wir eine vorhandene Ablaufverfolgungsbibliothek verwendet, die sich zufällig bereits in den Abhängigkeiten befand, und eine kleine Anpassung vorgenommen, um Ablaufverfolgungsdaten in das native Honeycomb-Format zu konvertieren. Wir begannen mit einem einfachen deterministischen Sampling, bei dem ~1 % aller von uns verarbeiteten Transaktionen zurückbehalten wurden.
Teamkollegen ermöglichen, Spuren zu übernehmen
Die Umstellung einer Organisation auf Traces ist keine Kleinigkeit. Traces sind komplexer als Metriken oder Protokolle und haben eine steile Lernkurve. Instrumentierung, Datenpipeline und Werkzeuge sind alle wichtig, aber die größte Herausforderung besteht darin, Ihren Teamkollegen zu ermöglichen, ihre Nutzung von Ablaufverfolgungen zu maximieren. Nachdem unser Proof-of-Concept in der Produktion lief, konzentrierten wir uns sofort auf den Aufbau einer Kultur der Beobachtbarkeit.
„Wir haben uns nicht nur auf Ingenieure konzentriert – wir haben mit Direktoren, technischen Programmmanagern, Mitgliedern des Sicherheitsteams und Vertretern des Kundensupports gesprochen, um zu betonen, wie Traces ihnen bei der Lösung ihrer spezifischen Probleme helfen können.“
Verbündete zu finden war der Schlüssel zum Erfolg. Wir haben eine Gruppe von Champions zusammengestellt, die sich bereits mit Beobachtbarkeit auskennen. Sie halfen dabei, unsere Annahmen zu bestätigen, und verbreiteten das Wort über Spuren in ihren Teams. Aber wir haben uns nicht nur auf Ingenieure konzentriert – wir haben mit Direktoren, technischen Programmmanagern, Mitgliedern des Sicherheitsteams und Vertretern des Kundensupports gesprochen, um zu betonen, wie Traces ihnen helfen können, ihre spezifischen Probleme zu lösen.
Das Anpassen unserer Botschaft hat dazu beigetragen, Unterstützung zu gewinnen. Die Einführung neuer Werkzeuge birgt immer ein gewisses Risiko – indem wir Potenzial zeigen und Menschen begeistern, erhöhen wir unsere Erfolgschancen.
Stufe 3: Entscheidung für den richtigen Anbieter
Mit dem Start des Enablement-Programms begannen wir, uns die modernen Tracing-zentrierten Anbieter anzusehen und eine Reihe von Kriterien zu formulieren, anhand derer potenzielle Kandidaten bewertet werden sollten.

Arbeitsabläufe : Wir haben den explorativen Arbeitsablauf als den wichtigsten identifiziert – er würde Ingenieuren ermöglichen, Produktionsdaten willkürlich zu zerlegen und Einblicke über Visualisierungen und Attribute mit hoher Kardinalität zu erhalten. Ein großer Teil der Diagnose eines Problems besteht darin, es zu erkennen, und das bedeutet, zu verstehen, wie „normal“ aussieht. Wir wollten es Ingenieuren erleichtern, die Produktion zu erkunden, indem wir so häufig wie möglich Fragen stellen, nicht nur, wenn Probleme auftreten.
„Wir wollten die volle Kontrolle darüber, wie Daten erfasst und aufbewahrt werden.“
Stichproben- und Aufbewahrungskontrollen : Wir wollten die vollständige Kontrolle darüber, wie Daten gesammelt und aufbewahrt werden. Deterministisches Sampling hat uns geholfen, schnell loszulegen, aber wir wollten selektiver vorgehen und mehr „interessante“ Spuren (z. B. Fehler, langsame Anfragen) mithilfe von Smart Dynamic Sampling behalten und gleichzeitig unter dem Vertragslimit bleiben.
Präzise Datenvisualisierungen : Wir wollten sicherstellen, dass Observability-Tools unabhängig von der von uns verwendeten Sampling-Technik diese transparent handhaben, indem sie „wahre“ angenäherte Zahlen in den Visualisierungen anzeigen. Jeder Anbieter ging dieses Problem anders an – einige verlangen, dass alle Daten an einen globalen Aggregator gesendet werden, um Metriken für Schlüsselindikatoren wie Fehlerrate, Volumen usw. abzuleiten. Angesichts der enormen Datenmenge, die von unserer umfangreichen Instrumentierung generiert wird, war dies für uns keine Option.
Preisgestaltung : Wir wollten ein einfaches, vorhersehbares Preisschema, das mit dem Wert korreliert, den wir aus dem Tool ziehen würden. Gebühren für die Menge der gespeicherten und offengelegten Daten zu erheben, schien fair.
Engagement-Metriken : Wir wollten, dass der Anbieter ein guter Partner ist und uns dabei hilft, die Akzeptanz und Effektivität des Tools zu verfolgen, indem wir wichtige Nutzungsmetriken und Engagement-Niveaus offenlegen.
Es gibt keinen perfekten Anbieter, seien Sie also bereit, einige Kompromisse einzugehen. Am Ende kamen wir zu dem Schluss, dass Honeycomb nicht nur für den von uns identifizierten Hauptworkflow besser funktionierte, sondern auch die Kästchen in Bezug auf Stichproben, Preise und Nutzungsmetriken ankreuzte – sodass wir die kostspielige Anbietermigration vermieden haben.
Nach einem herausfordernden Arbeitsjahr hatten wir den technischen Teil des Beobachtbarkeitsprogramms abgeschlossen. Das hatten wir erreicht:
- Unsere monolithische Hauptanwendung wurde automatisch mit hochwertigen attributreichen Spuren instrumentiert.
- Entwickler hatten eine kleine Auswahl praktischer Methoden, um ihrem Code benutzerdefinierte Instrumentierung hinzuzufügen.
- Wir hatten Honeycomb Refinery eingesetzt, um Daten dynamisch abzutasten und mehr der „interessanten“ Spuren zu behalten. Wir haben Ingenieure ermutigt, benutzerdefinierte Aufbewahrungsregeln für eine genauere Kontrolle zu konfigurieren. Für die wertvollsten Transaktionen und wenn es wirtschaftlich machbar ist, haben wir eine 100-prozentige Aufbewahrung angeboten, um den Leuten die Daten zu geben, die sie brauchen.
Stufe 4: Steigende Akzeptanz
Nachdem wir uns für Honeycomb entschieden und die Arbeit an der Datenpipeline abgeschlossen hatten, verlagerten wir unseren Fokus wieder auf die Aktivierung. Um eine Kultur der Beobachtbarkeit aufzubauen, müssen Sie es den Menschen leicht machen, an Bord zu kommen. Hier sind einige der Möglichkeiten, wie wir Teams bei der Einführung neuer Observability-Tools geholfen haben:
Ablaufverfolgung in der Entwicklungsumgebung
Um Ingenieure mit der Ablaufverfolgungsinstrumentierung vertraut zu machen und sie zu ermutigen, sie ihrem Code hinzuzufügen, haben wir optionale Ablaufverfolgung aus der lokalen Entwicklungsumgebung mit den in Honeycomb bereitgestellten Ablaufverfolgungen angeboten. Dies half den Leuten, neue benutzerdefinierte Instrumentierung genau so zu visualisieren, wie sie es sehen würden, wenn der Code in Produktion ging.
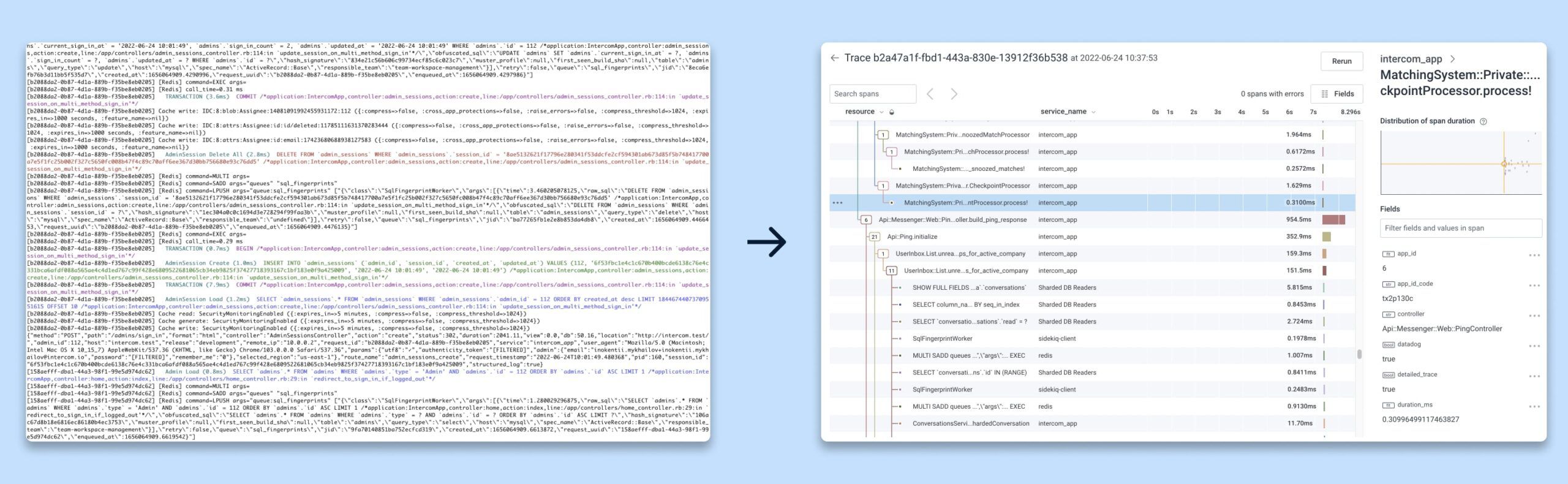
Protokolle können schwierig zu lesen und zu interpretieren sein, wohingegen Ablaufverfolgungsansichten viel strukturierter und organisierter sind
Slackbot-Abfrageverknüpfungen
Wenn die Produktion in Schwierigkeiten gerät, ist es das Letzte, was Sie wollen, um die richtige Abfrage zu finden. Wir haben eine benutzerdefinierte Bot-Reaktion zu einer „Show me web performance“-Nachricht hinzugefügt. Wenn Sie dem Slackbot-Link folgen, wird eine nach Dienst aufgeschlüsselte Webendpunktleistung geöffnet.
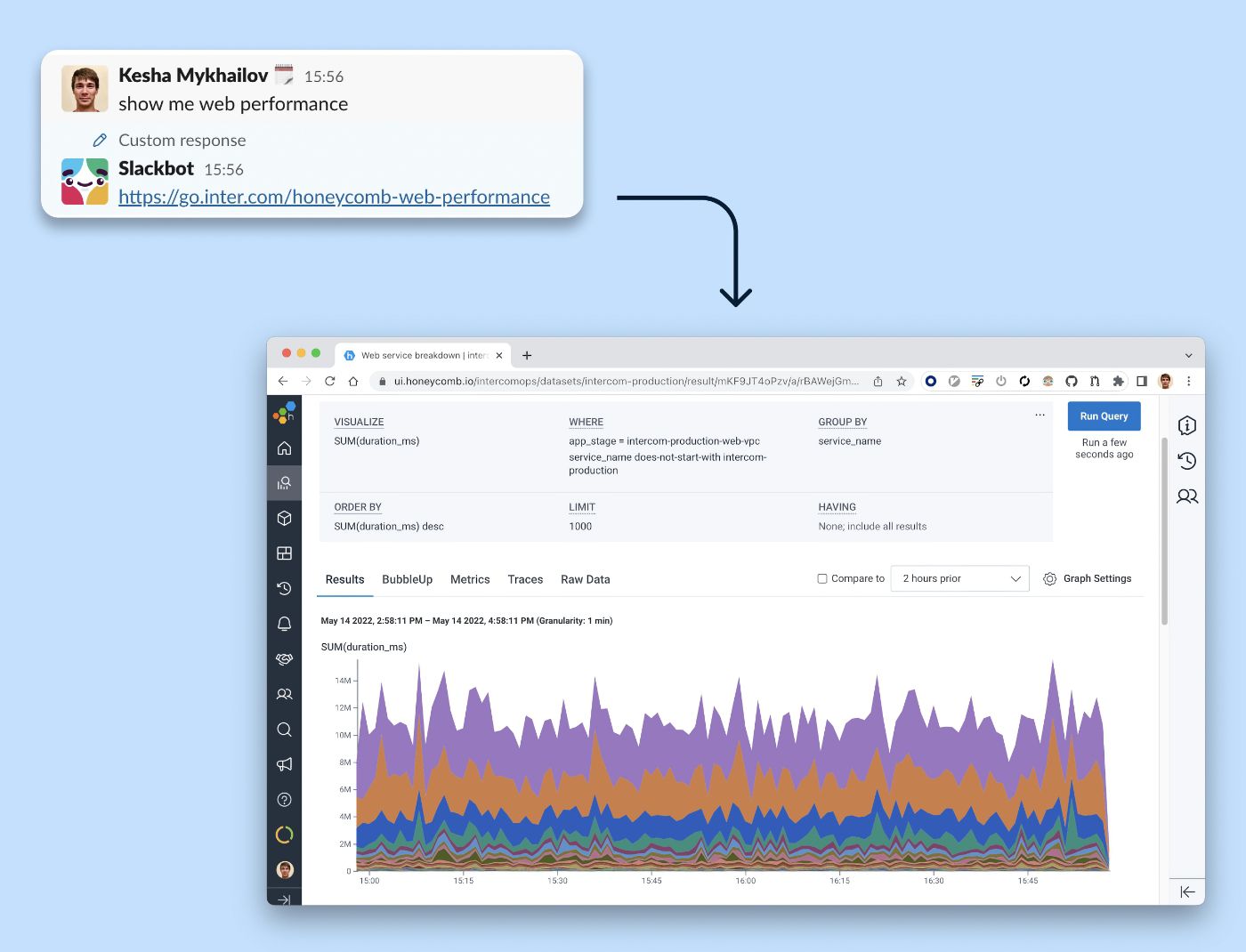
Wir rationalisieren unseren Beobachtbarkeits-Workflow mit einem Slackbot, der eine Verknüpfung zu einer beliebten Abfrage in unseren Beobachtbarkeits-Tools bietet
Phase 5: Reflexionen und nächste Schritte
Akzeptanz messen
Die Messung des Return of Investment (ROI) von Observability Tools ist eine Herausforderung. Die Verfolgung der Anzahl aktiver Benutzer ist ein guter Indikator dafür, wie oft Ingenieure mit den Tools arbeiten, und wir haben sehr von den Nutzungsmetriken von Honeycomb profitiert.

Dieses Diagramm zeigt die Zunahme der Anzahl aktiver Honeycomb-Benutzer seit Beginn der Beobachtbarkeitsaktivierung
Wir gingen noch weiter und maßen den Nutzen dieser Engagements. Wir postulierten, dass die Menschen, wenn sie aus den Observability-Tools gewonnene Erkenntnisse wertvoll wären, sie mit ihren Kollegen teilen würden. Unsere Engineering-Workflows hängen stark von Github-Problemen ab, daher haben wir uns entschieden, die Anzahl der Probleme oder Pull-Requests zu zählen, bei denen Honeycomb erwähnt oder mit denen verknüpft wurde (Trace, Abfrageergebnis usw.), als Proxy für eine Akzeptanzmetrik. Als wir die Aktivierung gegen Ende 2021 verdoppelten, beobachteten wir eine explosionsartige Anzahl von Problemen, in denen Honeycomb erwähnt wurde, was beweist, dass wir auf dem richtigen Weg waren.
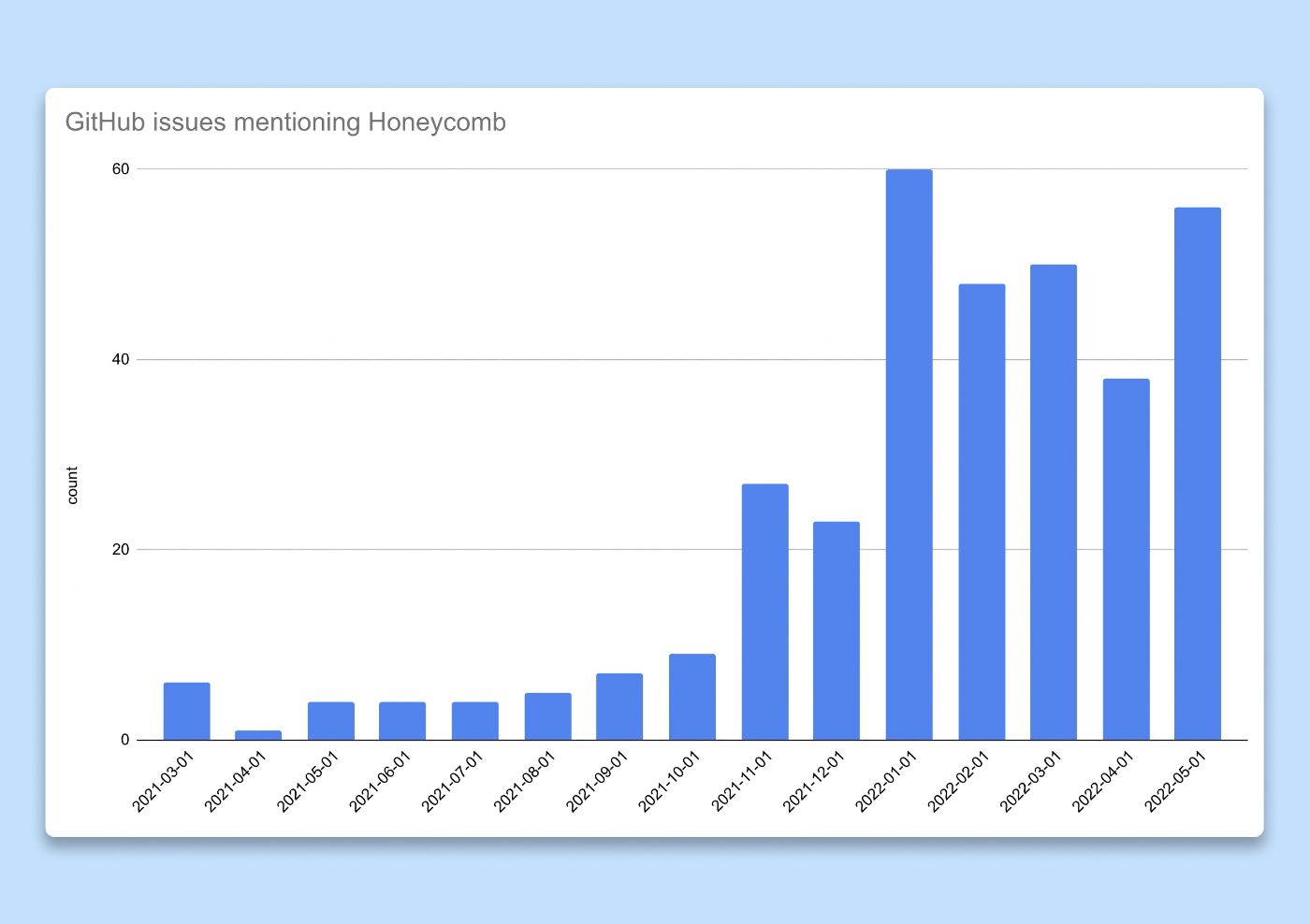
Balkendiagramm mit der Anzahl der GitHub-Probleme, bei denen Honeycomb im Titel oder in der Beschreibung erwähnt wird
Unerwartete Arbeitsabläufe
Der Aufbau einer soliden Beobachtbarkeitsgrundlage ermöglichte Arbeitsabläufe, die wir uns vorher nicht hätten vorstellen können. Hier sind einige unserer Favoriten:
Informationskostenprogramm : Da wir den gesamten Datenverkehr nachverfolgen und Spans für SQL-Abfragen, Elasticsearch-Anfragen usw. haben, können wir Auslastungsspitzen einzelner gemeinsam genutzter Teile unserer Infrastruktur (z. B. Datenbank-Cluster) untersuchen und sie einem einzelnen Kunden zuordnen. Wenn wir diese Daten mit den Kosten einzelner Infrastrukturkomponenten abgleichen, können wir jeder Transaktion, die wir bedienen, einen ungefähren Preisschild geben. Observability ist unerwartet zu einem integralen Bestandteil unseres Infrastrukturkostenprogramms geworden.
Verbesserung der Sicherheitsüberprüfung : Die Möglichkeit, 100 % der ausgewählten Transaktionen aufzubewahren, hat es uns ermöglicht, alle Interaktionen mit unserer Produktionsdatenkonsole aufzubewahren, was der Sicherheit hilft, eine bessere Transparenz über den Zugriff auf unsere Kundendaten zu schaffen.
Was kommt als nächstes?
Der Aufbau einer Kultur der Beobachtbarkeit wird weiterhin Teil unseres technischen Programms sein: Wir werden uns darauf konzentrieren, unser Onboarding-Material zu verbessern, die Beobachtbarkeit über Traces weiter in unsere F&E-Aktivitäten einzubinden und die Front-End-Instrumentierung zu erforschen.
Interessiert, unserem Team beizutreten? Sehen Sie sich hier unsere offenen Engineering-Rollen an.
