
GoogleDataStudioでのデータブレンディングの制限を克服する方法
公開: 2021-11-12Google Data Studioの上級ユーザーの場合、データブレンディング機能をすでに使用している可能性があります。
これは、データの可能性をすばやく高め、解き放つことができる優れた機能です。 特に、複数のソースからデータを取得してスプレッドシートに結合する時間がない場合。
ただし、データブレンディングにはいくつかの制限があり、レポートの速度が低下し、最悪の場合はデータの精度に影響を与える可能性があります。
この記事では、チームの2人の専門家であるBartoszSchneiderとEvanKaedingと協力して、Data Studioでのデータブレンディングの長所と短所、およびすべての頭痛の種を回避する方法について説明しました。
同じページにいることを確認するために、最初に基本を見てみましょう。
データ結合の基本
データ結合とは何ですか?
あなたがオンラインストアを管理しているとしましょう。 人気のソーシャルメディアプラットフォーム全体で有料広告を掲載しています。 どのチャネルが最も多くの収益をもたらすかを知りたいと思います。 これを行うには、有料のソーシャルデータをShopifyのデータと組み合わせる必要があります。
または、eコマースファネルがどのように見えるかを確認したい場合。 たとえば、顧客がアクセスしたページや、購入前にショッピングカートに追加した商品などです。 この場合、GoogleAnalyticsデータをShopifyデータに接続できます。
これは、データ結合の大まかな説明です。 複数のデータソースからのデータを単一のデータセットに結合するときはいつでも、データ結合を実行しています。 データ結合は、結合されたデータソースが少なくとも1つの共通のディメンション、つまり「結合キー」を共有している場合に機能します。
通常、ビジネスはさまざまなソースからデータを蓄積します。 すべてのデータを組み合わせると、パフォーマンスの全体像が失われます。 データ結合は次のことに役立ちます。
- 個別のデータソースから貴重な洞察を明らかにします。
- データセット間の意味のある関係を発見します。
- データに基づいたより適切な意思決定を行います。
さまざまな種類の結合
- 内部結合とは、両方のソースからのデータを結合することを意味します。結合キーが同じ場合にデータを一致させ、一致しないデータを削除します。
- 外部結合とは、両方のソースからすべてのデータを取得することを意味します。つまり、結合キーが同じ場合にデータを一致させます。 そして最後に、結合されたテーブルで、一致しない列に空の値を埋め込みます。
- 左結合とは、結合キーが同じである左側のテーブルからすべてのデータを取得し、右側のテーブルから一致するデータを取得することを意味します。
- 同様に、右結合とは、右のテーブルからすべてのデータを取得し、結合キーが同じである左のテーブルから一致するデータを取得することを意味します。
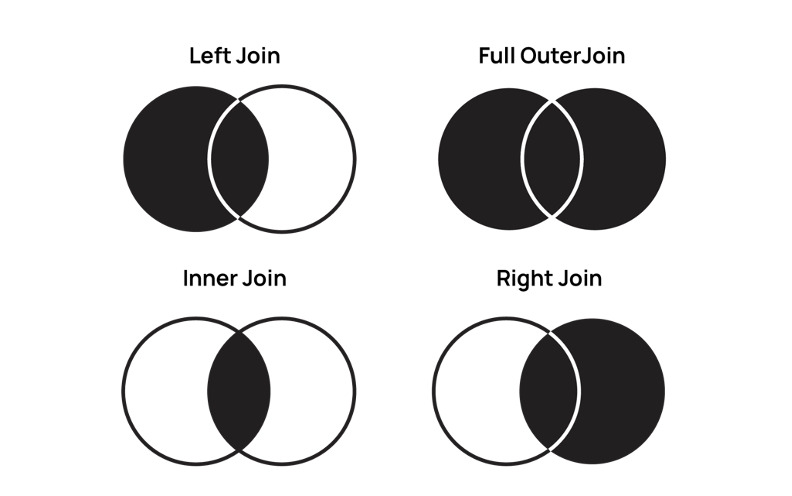
では、データ結合はデータブレンディングと関係がありますか?
ネタバレ注意:そうです。 Data Studioでのデータブレンディングは、左外部結合です。
GoogleDataStudioでのデータブレンディング
デフォルトでは、Google Data Studioでグラフを作成すると、単一のデータソースからデータを取得することになります。 ただし、複数のデータソースを接続して、データブレンディングを使用してチャートまたはテーブルにまとめて視覚化することができます。
データブレンディングは左外部結合です
データをブレンドするには、次を選択する必要があります。
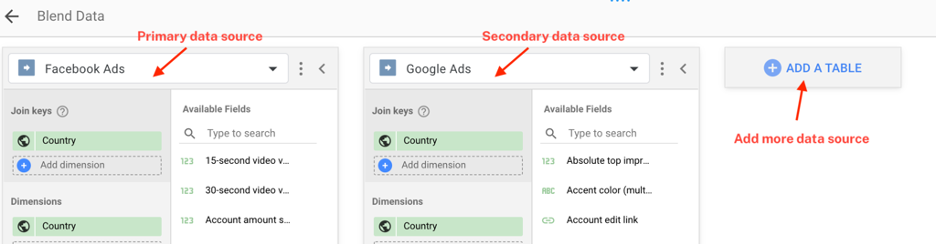
- プライマリソース:「ブレンドデータパネル」に追加する最初の(または左端の)データソース。
- 少なくとも1つのセカンダリソース:プライマリソースの右側に追加されたデータソース
- 参加キー
Data Studioでのデータブレンディングは左外部結合であるため、ブレンディングされたデータには、同じ結合キーを共有するプライマリデータソースからのすべてのデータとセカンダリソースからの一致するデータが含まれます。
以下の例を見てみましょう。
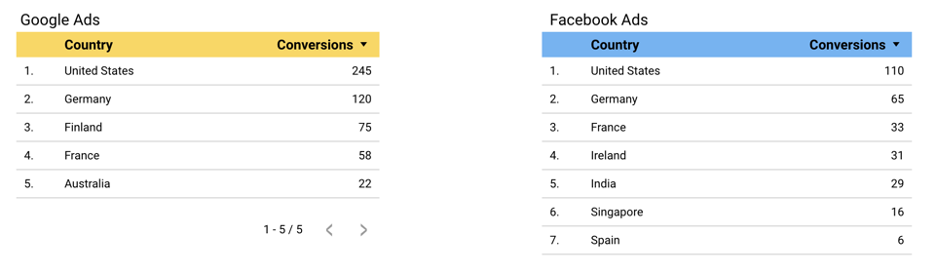
ここで、Google広告には、米国、ドイツ、フィンランド、フランス、オーストラリアの5か国のコンバージョンデータがあります。
Facebook Adsには、米国、ドイツ、フランス、アイルランド、インド、シンガポール、スペインの7か国のコンバージョンデータがあります。
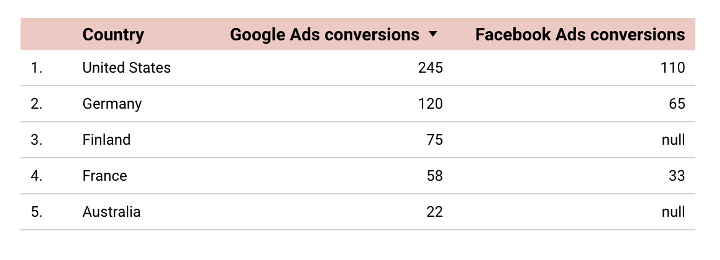
プライマリデータソースとしてGoogle広告を選択した場合、ブレンドされた結果には、米国、ドイツ、フィンランド、フランス、オーストラリアからのコンバージョンのみが表示されます。 アイルランド、インド、シンガポール、スペインはGoogle広告(主要な情報源)に含まれていないため、データは混合テーブルから除外されます。
また、Facebook広告テーブルではなくGoogle広告テーブルにデータがあるフィンランドは、混合テーブルにとどまることがわかります。 ただし、Facebook広告のコンバージョン値は「null」になります。
または、Facebook広告が主要なソースである場合、結果は米国、ドイツ、フランス、アイルランド、インド、シンガポール、スペインからのコンバージョンデータになります。
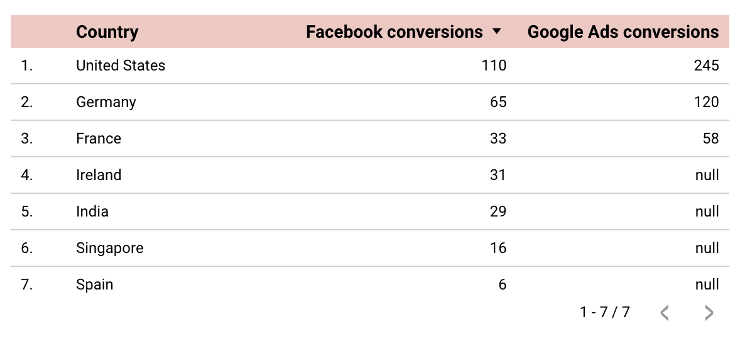

「プライマリテーブルに存在しないデータはすべて失われます。これが最初に注意する必要があることです。 一次情報源として最も長いテーブル(ブレンドの左側のテーブル)を選択することは理にかなっています。 そうしないと、プロセス中にいくつかの重要なデータが失われる可能性があります。」Bartosz Schneider、リード分析コンサルタント、スーパーメトリクス
Google Data Studioでは、[ブレンドデータ]ビューに最初に取り込むデータソースがプライマリソースです。 データソースの順序の変更は非常に簡単です。 データソースを目的の位置にドラッグアンドドロップするだけです。
ブレンディッドデータソースを作成する方法
データをブレンドするために使用できる2つのアプローチがあります。
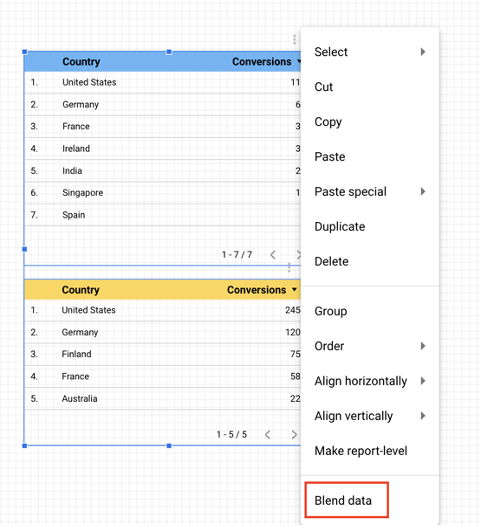
最初のアプローチは非常に迅速で簡単です。 共通のディメンションを持つ2つのテーブルがある場合は、両方のテーブルを選択して右クリックし、[データのブレンド]を選択できます。 Data Studioは、2つのテーブルをすばやく1つに結合します。 次に、ソーステーブルで提供されるフィールドに基づいてブレンドデータビューを自動的に生成します。
2番目のアプローチでは、より多くの手順が必要ですが、データをもう少し制御できます。
開始するには、[リソース]→[ブレンドデータの管理]をクリックします。
次に、[データビューの追加]をクリックして、[データのブレンド]ビューを開きます。
次に、ブレンドするデータソースを追加します。 ビューに追加する最初のデータソースがプライマリソースになることを忘れないでください。
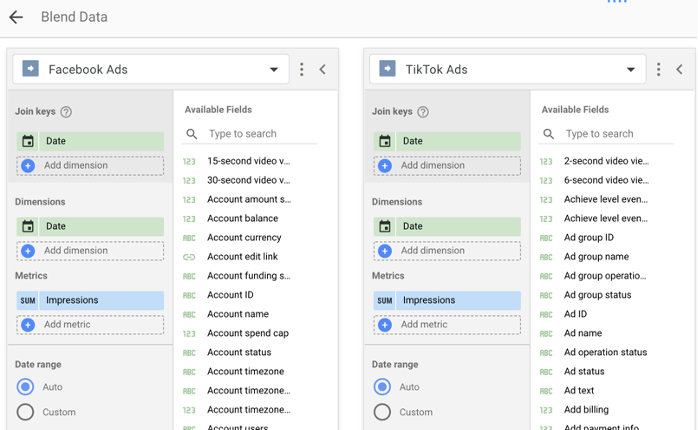
ここから、ブレンドする結合キー、ディメンション、指標を選択できます。
ヒント:後で他のソースと簡単に区別できるように、ブレンドされたデータソースに名前を付けます。
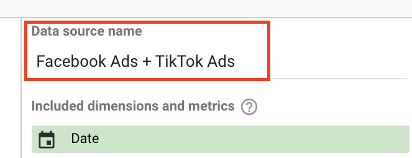
設定に問題がなければ、[保存]をクリックします。
[データソース]フィールドに追加して、ブレンドされたデータソースを使用してグラフの作成を開始します。
GoogleDataStudioでのデータブレンディングの制限
正確さ
従来、スプレッドシートでデータを結合する場合、さまざまな数式を使用して、取得するデータを正確にコンピューターに伝えることができます。 これにより、各ステップでデータに何が起こっているかを確認できます。 エラーが発生した場合は、いつでも生データに戻って問題を追跡できます。
ただし、Data Studioでは、結合は内部で行われるため、ブレンドされたデータにエラーがある場合、問題の原因はわかりません。

「DataStudioでは、結合されたデータを確認する方法は実際にはありません。 だからあなたは一種の空飛ぶ盲目です。 検査するのは非常に難しいです。 Googleが何をしているのか、Data Studioが重複を生成しているかどうか、またはフィールドが一致しない場合にフィールドが削除されたかどうかを理解する方法はありません。」Supermetrics、シニアセールスエンジニア、Evan Kaeding
左外側結合のみをサポート
上記のように、GoogleDataStudioでのデータ結合は常に左外部結合です。 さまざまなタイプの結合を使用してデータを強化することに慣れている場合、これは多少制限される可能性があります。
データをブレンドするとき、特にデータを結合する順序には特に注意する必要があります。 一次資料に関する1つの問題は、ブレンドされた結果の精度を損なう可能性があります。
スピード
GoogleDataStudioがレポートの読み込みに時間がかかることに気付くでしょう。 データブレンディングを画像に取り入れると、事態はさらに悪化します。
ブレンディッドデータソースを作成するときはいつでも、Googleはデータを取得するためにさまざまなAPIを経由する必要があります。 そして、そのプロセスにはかなりの計算能力が必要です。
追加するデータソースが多ければ多いほど、ダッシュボードの速度は遅くなります。
限られた数のブレンドされたソース
もう1つの苛立たしい制限は、最大5つのデータソースをブレンドできることです。 この数は多くのように聞こえますが、そうではありません。 多くの高度で詳細なレポートでは、5つ以上のソースからのデータをブレンドする必要がある場合があります。 多くの列を持つ非常に詳細なテーブルを作成する場合は、簡単に制限を超えることができます。
それで、あなたはすべてのトラブルから身を守り、データブレンディングを避けるべきですか?
公平を期すために、Google Data Studioは、シンプルで軽いブレンドで素晴らしい仕事をしています。 したがって、1つから2つのデータソースを日付などの単純な結合キーとブレンドする場合は、DataStudioを使用できます。
一方、データをより細かく制御し、より高度なブレンディングを実行したい場合は、Googleスプレッドシートが最適です。
Googleスプレッドシートでのデータブレンディング
Google Data Studioでのデータブレンディングが少し面倒になった場合は、Googleスプレッドシートでデータをブレンディングし、データスタジオに戻してレポートを作成できます。
このアプローチにより、データの柔軟性が高まります。 Googleスプレッドシートの数式を利用して、データを充実させることができます。 さらに、複数のソースからよりもGoogleスプレッドシートからブレンドデータをロードする方がはるかに高速です。
さらに、スーパーメトリクスを使用して、データをGoogleスプレッドシートに自動的に取り込むことができます。 データを分析し、意味のある洞察を得ることで、得意なことを実行するためのより多くの時間があります。

データを数分でGoogleスプレッドシートに移動
14日間の無料Supermetricsトライアルを開始します。 フル機能。 クレジットカードは必要ありません。
Googleスプレッドシートでデータを結合するためのヒントをいくつか見てみましょう。
Googleスプレッドシートでデータを管理する
さまざまなソースからGoogleスプレッドシートにデータを持ち込んでブレンドすると、すぐに混乱する可能性があります。 データを整理しておくための良い方法は、データを別々のタブに分割することです。
「データを生データ、混合データ、レポートデータの3つのバケットに分割することをお勧めします。 したがって、基本的には、生のレイヤーとブレンドされたレイヤーの両方に変更を加えることができるようにする必要があります。 しかし、その後は、最終レポートを可能な限りクリーンに保ちたいと考えています。」スーパーメトリクスのシニアセールスエンジニア、Kaedingでさえ
[生データ]タブには、データソースからのフォーマットされていないすべての生データが保存されます。 このレポート例では、Supermetricsを使用して、Facebook、Microsoft、およびGoogle広告から3つの別々のタブにデータをプルします。
![フォーマットされていないデータを[生データ]タブに配置します](/uploads/article/951/qp59Ca40vi4w9V0n.png)
「ブレンドデータ」タブは、魔法が起こる場所です。 データを照合し、いくつかの計算を実行して、データからより多くの洞察を得ることができます。

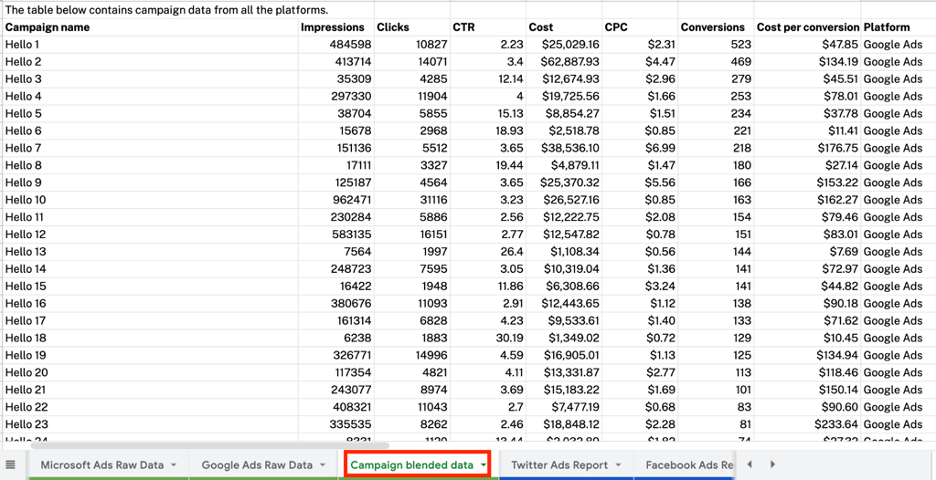
[レポートデータ]タブは、パズルの最後のピースを配置する場所です。 データの強化と変換が完了したら、監視しやすい別のタブにデータを表示できます。
さらに、[レポートデータ]タブをGoogle Data Studioに接続して、最終結果をダッシュボードに表示できます。 Googleスプレッドシートのコネクタは、コネクタギャラリーにあります。
次に、Googleスプレッドシートでデータをブレンドするときに知っておく必要のあるいくつかの関数を見てみましょう。
Googleスプレッドシートでデータを結合するための3つの便利な関数
VLOOKUP
VLOOKUPは、データ結合に最もよく使用される関数の1つです。 あるテーブルで値を検索し、それを別のテーブルで使用できます。
VLOOKUPの構文は次のとおりです。
VLOOKUP (search_key, range, index, [is_sort])
- search_key :検索する値。
- range :検索する値を含む範囲。 VLOOKUPは、範囲内の最初の列から検索することに注意してください。
- index :戻り値を含む(選択した範囲内の)列番号。
- is_sort :このパラメーターはオプションです。 ここで、完全一致(FALSE)または最も近い一致値(TRUE)のどちらを受信するかを指定できます。 データ結合の場合は、完全に一致するように設定する必要があります。
Googleスプレッドシートに、検索する値、検索する場所、返す値が含まれる範囲の列番号、最後に完全一致(FALSE)または最も近い一致(TRUE)。
2つのテーブルがあるとしましょう。
- 日付、ソース、メディア、キャンペーン、インプレッション、コスト、クリックに関するデータを含むマーケティングテーブル
- 日付、ソース、メディア、トランザクション、および収益に関するデータを含む変換テーブル。
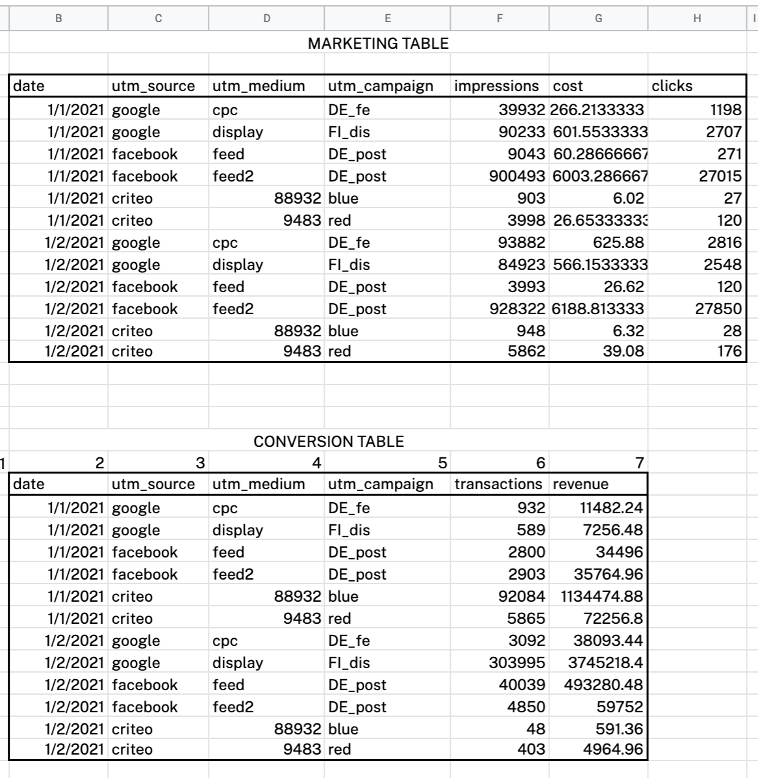
Bartoszによると、パズルをつなぐには2つのステップがあります。
まず、TEXTJOIN関数を使用して2つのテーブルの複合キーを作成する必要があります。 各複合キーを使用して、テーブルの各行を一意に識別できます。 複合キーがないと、1対多の関係に遭遇する可能性があります。 さらに、それらをVLOOKUPの結合キーとして使用できます。
複合キーには、キャンペーンの日付、ソース、メディア、およびキャンペーン(この場合はキャンペーン名を意味します)が含まれます。 こんな感じになります。
次に、VLOOKUPを使用して2つのテーブルを結合します。 たとえば、トランザクションデータをマーケティングテーブルと組み合わせるための式は次のとおりです。
VLOOKUP($A4,$A$22:$J$33,6,0)
ヒント:絶対参照を使用すると、Googleが値を検索したり、数式をスプレッドシート全体にドラッグしたりするのが簡単になります。
簡単に言えば、Googleは最初の列で複合キーを検索し、対応するトランザクションを返します。

IF + REGEXPMATCH
最初のステップは、IF関数(列FおよびN)を使用してキャンペーン名を新しい値に再マップすることです。 次に、その新しいクリーンアップされた名前が結合キーとして使用され、シートの右側にメトリックテーブルが生成されます。ここで、2つのソースからのメトリックが、以前に再マップされたキャンペーン名と一致する場所に集約されます。
次に見ている関数は入れ子関数です— IF + REGEXPMATCH、ここで
- IFは条件付き評価を開始します。
- REGEXPMATCHは、ターゲットのテキスト一致をチェックします
Bartoszは、1つまたは複数の異なるデータソースからキャンペーン名を再マッピングする必要がある場合に、この関数が役立つことを発見しました。
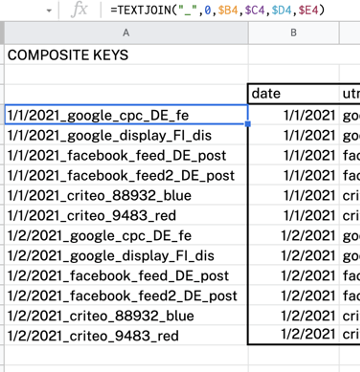
下の表を見てみましょう。 ご覧のとおり、「GoogleDataStudio」と「googledatastudio」または「Enterprise」と「enterprise」などのさまざまな命名規則があります。
次の式を使用して、すべてのGoogle Data Studioキャンペーンを1つのバスケットに入れ、Enterpriseキャンペーンを1つのバスケットに入れることができます。
=IF(
REGEXMATCH(A7,"Data Studio|datastudio"),"Data Studio Campaigns",
IF(REGEXMATCH(A7,"Enterprise|enterprise"),"Enterprise campaigns"
))
簡単に言うと、関数は列A7で「DataStudio」または「datastudio」を検索し、「DataStudioCampaigns」を返します。 そのような値がない場合は、「エンタープライズ」または「エンタープライズ」を検索して、「エンタープライズキャンペーン」を返します。
さまざまなソースからキャンペーン名を再マップして、それらを参加キーとして使用できます。
条件付き集計
Googleスプレッドシートでは、さまざまな集計関数を使用してデータを要約できます—合計、平均の計算、またはデータポイントの数のカウント。 ただし、実際には、所有しているすべてのデータを集約したくない場合があります。 その場合、条件付き集計を使用して、集計するデータを指定できます。
条件付き集計は、特定の基準を満たしたときに一連のデータに対してデータ集計を実行するようにGoogleに指示する機能です。 一般的な条件付き集計関数をいくつか見ていきます。
SUMIF関数は、範囲内の事前定義された条件を満たすデータの合計を計算するようにGoogleに指示します。 SUMIF関数の構文は次のとおりです。
SUMIF (range, criterion, [sum_range])
- range :条件を適用するデータ範囲を指定します。
- 基準:合計するセルを定義する条件を指定する必要があります。
- sum_range :'range'と異なる場合は、合計する範囲を指定する必要があります。 これはオプションです。
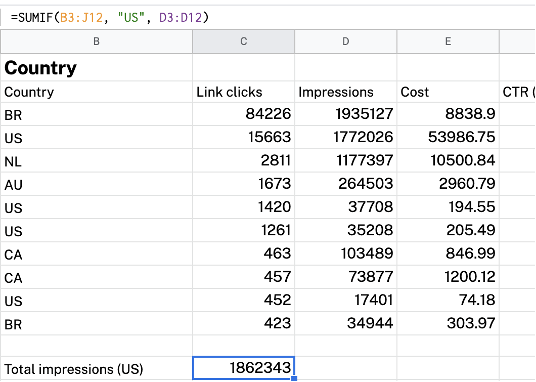
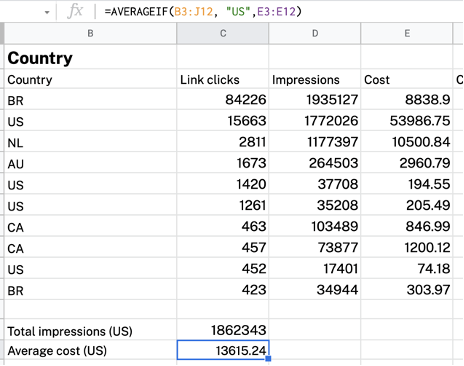
以下の表を例として取り上げます。 米国からのインプレッションを計算するとします。 これは、SUMIF (B3:J12, “US”, D3:D12)を使用して行うことができます。
AVERAGEIF関数は、範囲内の特定の基準を満たすデータの平均値を返します。 AVERAGEIF関数の構文は次のとおりです。
AVERAGEIF (criteria_range, criterion, [average_range])
- 基準範囲:条件を適用するデータ範囲を選択する必要があります。
- 基準:平均化されるセルを定義する条件を指定します。
- average_range:'criteria_range'と異なる場合は、平均化する範囲を指定する必要があります。 これはオプションです。
たとえば、米国からの平均コストを計算する場合は、 AVERAGEIF(B3:J12, “US”, E3:E12)を使用できます。
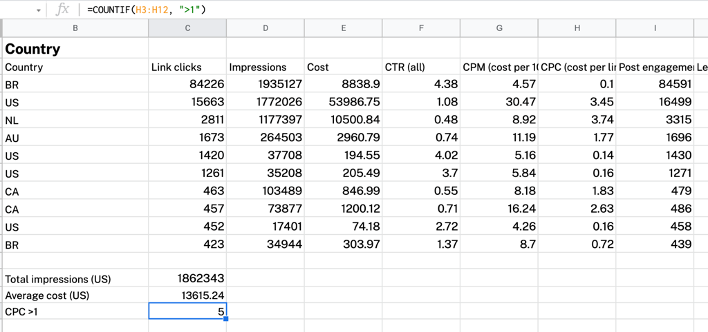
同様に、COUNTIF関数は、データに対して条件付きカウントを実行します。 COUNTIFの構文は次のとおりです。
COUNTIF (range, criterion)
- range :カウントしたい範囲。
- 基準:適用したい条件。
たとえば、CPCが1より大きい国の数を数えたいとします。これは、 COUNTIF(H3:H12, “>1”)を使用して行うことができます。
データブレンディングを使用するさまざまな方法
データブレンディングを実践する方法はたくさんあります。 このセクションでは、いくつかの例を見ていきます。 さらに、すぐに使用できるブレンドデータを含む既製のテンプレートもいくつかあります。
データソースをテンプレートに接続すると、14日間の無料Supermetricsトライアルが自動的に開始されることに注意してください。
Facebook広告とGoogle広告のパフォーマンスを比較する
Google広告とFacebook広告は、最も人気のある広告プラットフォームの1つです。 正確な比較ではありませんが、Facebook広告データとGoogle広告データを組み合わせると、どのタイプのキャンペーンがどのチャネルで最も効果的かがわかります。
たとえば、以下のGoogle広告とFacebook広告のダッシュボードでは、次のことが簡単にわかります。
- 各チャネルのサイドバイサイドパフォーマンス。
- 2つのチャネル間の費用、表示回数、クリック数、コンバージョンの分割。
- チャネルごとの最もパフォーマンスの高いキャンペーン。
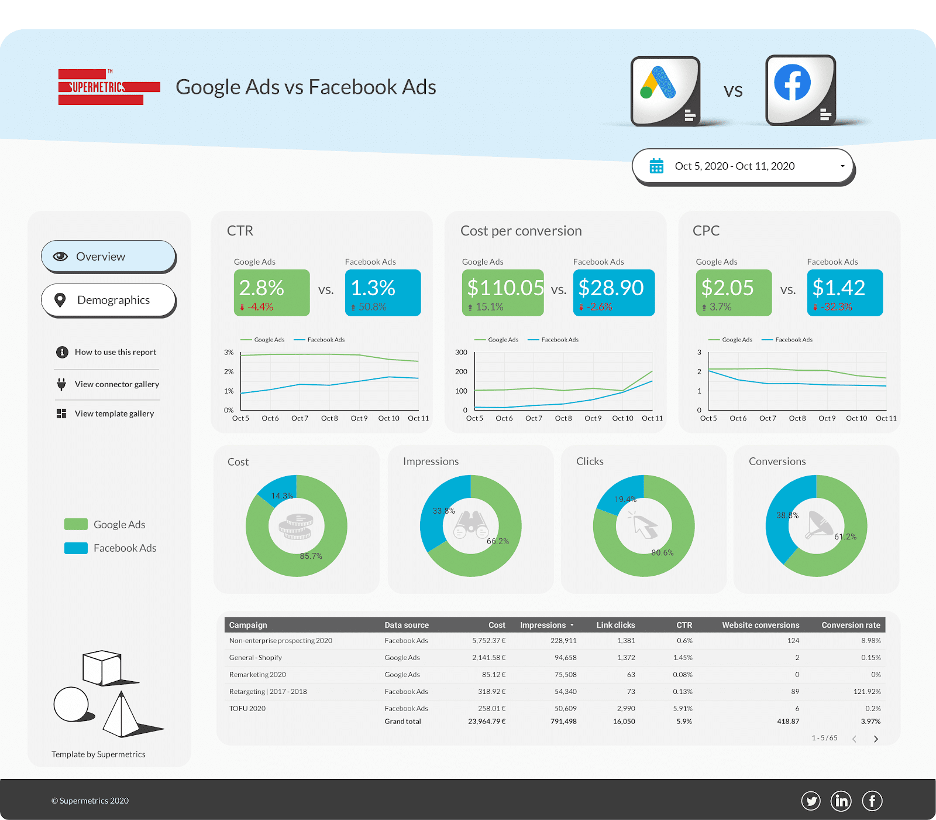
Google広告とFacebook広告のテンプレートをスワイプします>>
有機ソーシャルメディア
あなたの会社のソーシャルメディアアカウントを管理することは、公園を散歩することではありません。 1つには、少なくとも3つの異なるアカウントを管理する必要があります。これらのアカウントはすべて、コンテンツのアルゴリズムと要件が異なります。
ソーシャルメディアプラットフォームからのデータをブレンドすることで、パフォーマンスを簡単に管理し、ソーシャルゲームを常に把握することができます。
たとえば、以下のダッシュボードでは、Facebook、Instagram、Twitter、LinkedInの4つの人気のソーシャルメディアチャネルからのデータを組み合わせています。 このダッシュボードは次の場合に最適です。
- チャネル全体のパフォーマンスを監視します。
- さまざまなチャネルのパフォーマンスを比較します。
- 各チャネルのパフォーマンスを深く掘り下げます。
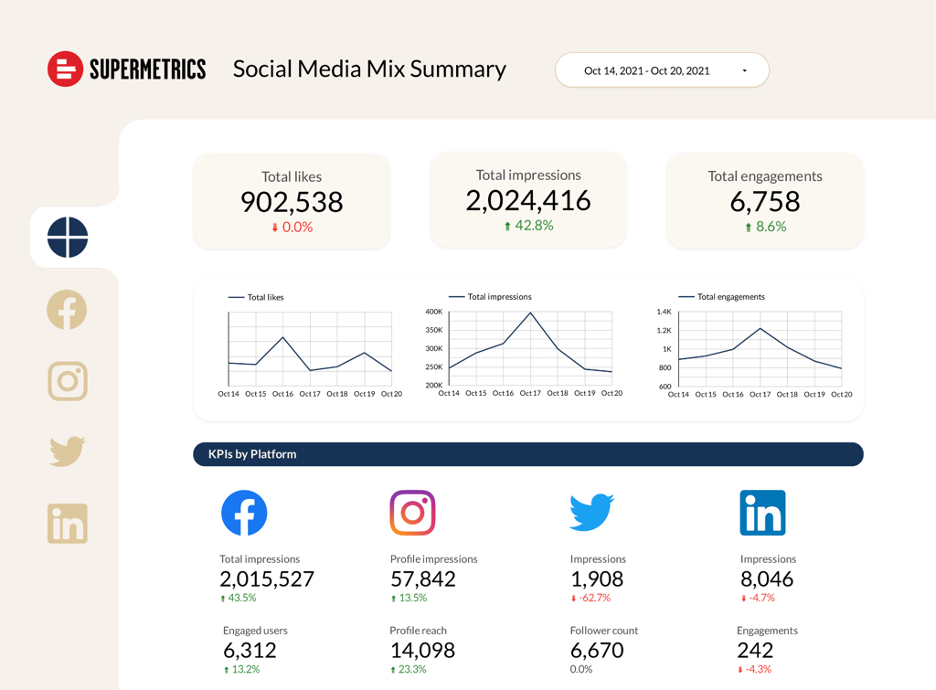
ソーシャルメディアミックスダッシュボードをスワイプします>>
有料チャンネルミックス
おそらく、有料チャネルプラットフォームとセッションのパフォーマンスマーケティングデータと、Googleアナリティクスのコンバージョンデータがあります。 有料広告データとウェブ分析データをブレンドすると、どのキャンペーンとチャネルが高品質のトラフィックを促進しているかを理解するのに役立ちます。
たとえば、この有料チャンネルミックスダッシュボードでは、Google、LinkedIn、Twitter、Facebook、Microsoftの有料データとGoogleアナリティクスのデータをブレンドしています。 これを使用すると、次のように表示されます。
- 有料キャンペーンの一般的な概要。
- 前の期間とのパフォーマンスの比較。
- 最高のパフォーマンスを発揮するチャネルの主要な指標を示す表。
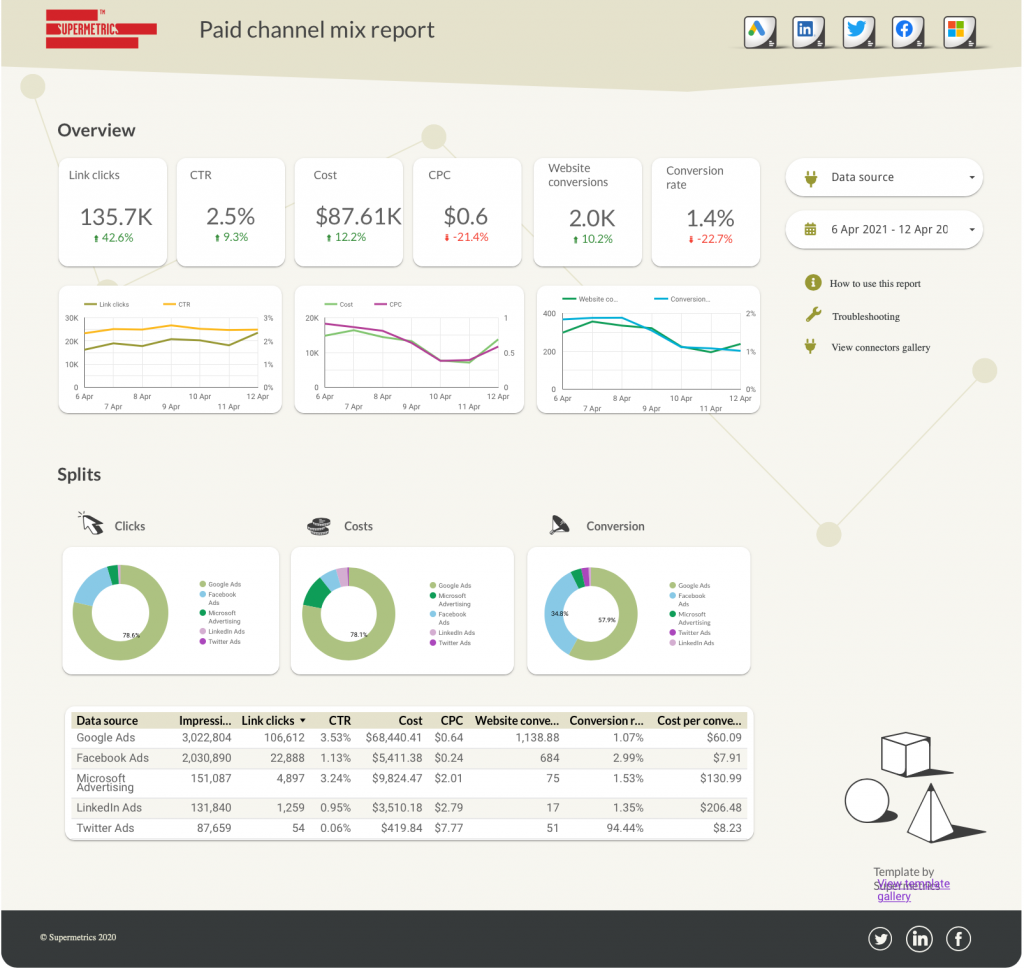
有料チャンネルミックスダッシュボードを入手>>
有機検索と有料検索の分析
オーガニック検索と有料検索ではありません。 あなたのビジネスを成長させるために、あなたは両方を必要とします。 たとえば、パフォーマンスマーケターは、上位の検索フレーズを見て、それらのキーワードに入札することが理にかなっているかどうかを判断できます。
同様に、コンテンツマーケターは、有料検索データを使用してコンテンツ戦略を推進することもできます。
このオーガニック検索と有料検索の分析テンプレートでは、OIKIOエージェンシーの友人がGoogle広告とGoogle検索コンソールのデータを組み合わせています。 両方のチャネルでコンバージョンを促進するのに役立ちます。 それを使用して、次のことを決定できます。
- オーガニック検索に含まれていないGoogle広告のフレーズのパフォーマンス。
- Google広告でまだ入札していないオーガニック検索フレーズのパフォーマンス。
- 特定の検索フレーズのPPC/SEO比。
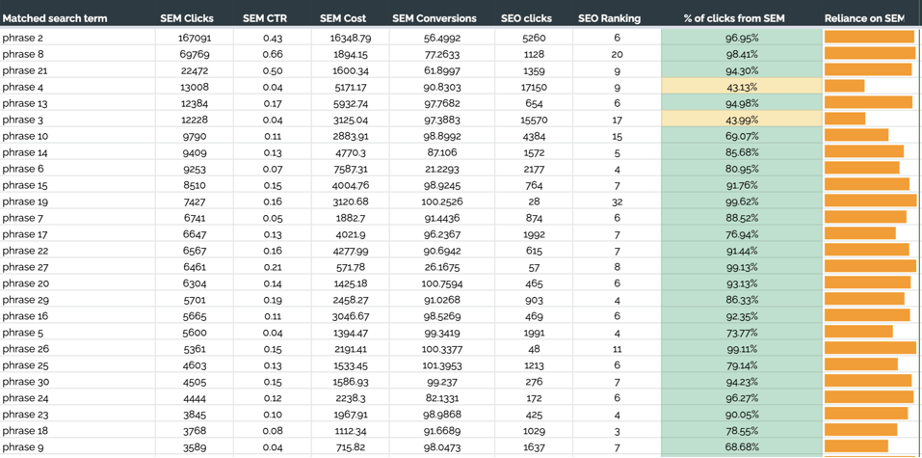
有機検索と有料検索の分析テンプレートをスワイプします>>
オーガニックトラフィックとキーワード分析
グーグルがグーグルアナリティクスから検索フレーズデータを削除したとき、それはかなりイライラしました。 ただし、回避策があるので心配しないでください。 Google検索コンソールのデータとGoogleAnalyticsのデータを組み合わせることで、どのオーガニックキーワードがウェブサイトにトラフィックをもたらしているかを把握できます。
OIKIOの友人によるこのオーガニックトラフィックとキーワード分析テンプレートを見てみましょう。 このテンプレートを使用すると、次のことができます。
- どの検索フレーズが最も多くのトラフィックをもたらすかを把握します。
- さまざまなランディングページのパフォーマンスを比較します。
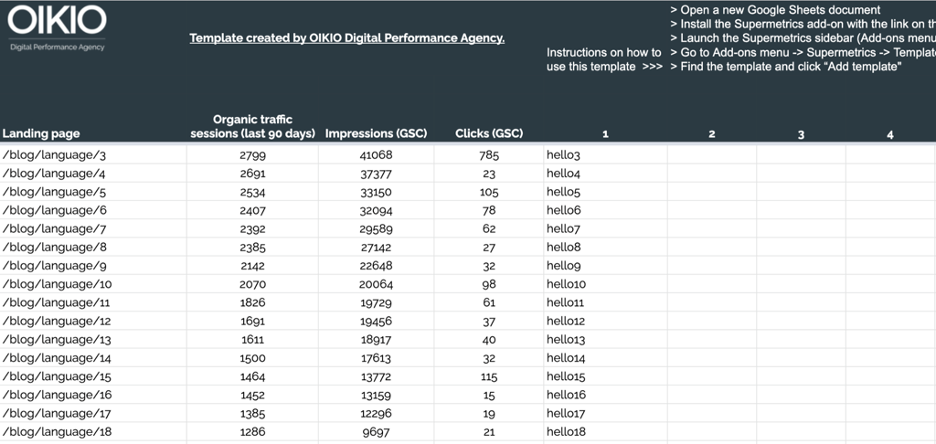
オーガニックトラフィックとキーワード分析テンプレートを入手する>>
あなたに
おめでとうございます、あなたはこの記事の終わりに到達しました。 さあ、背中を軽くたたいてください。
結局のところ、データブレンディングは、データを最大限に活用し、より意味のある洞察を明らかにするのに役立ちます。
少量で管理しやすい量のデータを使用している場合は、GoogleDataStudioのデータブレンディング機能を完全に活用できます。
一方、はるかに大きなデータセットを処理していて、データをより適切に制御したい場合は、Googleスプレッドシートがより優れたソリューションです。
また、データをGoogleスプレッドシートに移動する際にサポートが必要な場合はいつでも、14日間のSupermetrics無料トライアルを開始できることを忘れないでください。