
Głębokie uczenie a uczenie maszynowe – jak odróżnić?
Opublikowany: 2020-03-10W ostatnich latach uczenie maszynowe, głębokie uczenie i sztuczna inteligencja stały się modnymi słowami. W rezultacie można je znaleźć wszędzie w materiałach marketingowych i reklamach coraz większej liczby firm.
Ale czym są uczenie maszynowe i uczenie głębokie? A jakie są między nimi różnice? W tym artykule postaram się odpowiedzieć na te pytania i pokazać kilka przypadków aplikacji Deep i Machine Learning.
Co to jest uczenie maszynowe?
Uczenie maszynowe to część informatyki, która zajmuje się przedstawianiem zdarzeń lub obiektów ze świata rzeczywistego za pomocą modeli matematycznych opartych na danych. Modele te są budowane za pomocą specjalnych algorytmów, które dostosowują ogólną strukturę modelu tak, aby pasował do danych uczących. W zależności od rodzaju rozwiązywanego problemu definiujemy nadzorowane i nienadzorowane algorytmy uczenia maszynowego i uczenia maszynowego.
Nadzorowane a nienadzorowane uczenie maszynowe
Nadzorowane uczenie maszynowe koncentruje się na tworzeniu modeli, które byłyby w stanie przenieść posiadaną już wiedzę o dostępnych danych do nowych danych. Nowe dane są niewidoczne dla algorytmu budowania modelu (uczenia) podczas fazy uczenia. Podajemy algorytm z danymi cech wraz z odpowiadającymi im wartościami, które algorytm powinien nauczyć się z nich wnioskować (tzw. zmienna docelowa).
W nienadzorowanym uczeniu maszynowym udostępniamy algorytmowi tylko funkcje. To pozwala mu samodzielnie określić ich strukturę i/lub zależności. Nie określono jasnej zmiennej docelowej. Pojęcie uczenia się bez nadzoru może być początkowo trudne do uchwycenia, ale przyjrzenie się przykładom przedstawionym na czterech poniższych wykresach powinno wyjaśnić tę ideę.
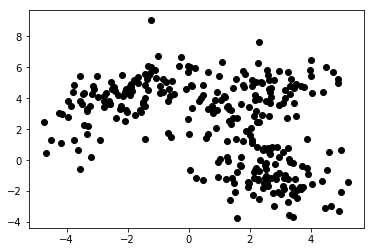
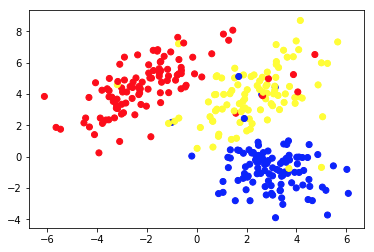
Wykres 1a przedstawia niektóre dane opisane 2 cechami na osiach x i y . Ta oznaczona jako 1b pokazuje te same dane w kolorze. Użyliśmy algorytmu grupowania K-średnich , aby pogrupować te punkty w 3 skupienia i odpowiednio je pokolorować. To jest przykład nienadzorowanego algorytmu uczenia maszynowego. Algorytmowi nadano tylko cechy, a etykiety (numery klastrów) miały zostać wymyślone.
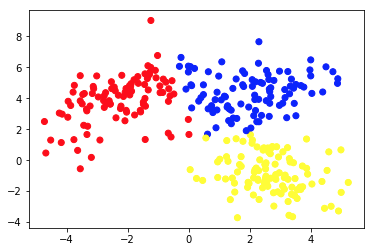
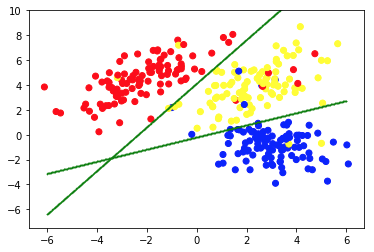
Drugie zdjęcie przedstawia wykres 2a, który przedstawia inny zestaw oznaczonych (i odpowiednio pokolorowanych) danych. Znamy grupy, do których każdy z punktów danych należy a priori . Używamy algorytmu SVM , aby znaleźć 2 proste linie, które pokażą nam, jak podzielić punkty danych, aby najlepiej pasowały do tych grup. Ten podział nie jest idealny, ale to najlepsze, co można zrobić prostymi liniami. Jeśli chcemy przypisać grupę do nowego, nieoznakowanego punktu danych, wystarczy sprawdzić, gdzie leży na płaszczyźnie. To jest przykład nadzorowanej aplikacji Machine Learning.
Zastosowania modeli uczenia maszynowego
Standardowe algorytmy uczenia maszynowego są tworzone do obsługi danych w formie tabelarycznej. Oznacza to, że aby z nich skorzystać, potrzebujemy jakiegoś stolika. W takiej tabeli wiersze można traktować jako instancje modelowanego obiektu (np. pożyczka). Jednocześnie kolumny należy traktować jako cechy (cechy) tego konkretnego przypadku (np. miesięczna spłata kredytu, miesięczny dochód kredytobiorcy).

Ciekawi Cię rozwój uczenia maszynowego?
Ucz się więcejTabela 1. jest bardzo krótkim przykładem takich danych. Oczywiście nie oznacza to, że same dane muszą być tabelaryczne i ustrukturyzowane. Ale jeśli chcemy zastosować standardowy algorytm uczenia maszynowego na jakimś zbiorze danych, zwykle musimy go wyczyścić, wymieszać i przekształcić w tabelę. W uczeniu nadzorowanym istnieje również jedna specjalna kolumna, która zawiera wartość docelową (np. informację, czy pożyczka jest niespłacona).
Algorytm uczący próbuje dopasować ogólną strukturę modelu do tych danych. Wspomniany algorytm robi to, dostosowując parametry modelu. Daje to model, który jak najdokładniej opisuje relację między podanymi danymi a zmienną docelową.
Ważne jest, aby model nie tylko dobrze pasował do danych treningowych, ale był również zdolny do generalizacji. Generalizacja oznacza, że możemy użyć modelu do wywnioskowania celu dla instancji nieużywanych podczas uczenia. Jest to również kluczowa cecha użytecznego modelu. Budowanie dobrze uogólniającego modelu nie jest łatwym zadaniem. Często wymaga wyrafinowanych technik walidacji i dokładnych testów modelu.
| identyfikator_pożyczki | wiek_pożyczkobiorcy | dochód_miesięczny | Kwota kredytu | miesięczna płatność | domyślna |
| 1 | 34 | 10 000 | 100 000 | 1200 | 0 |
| 2 | 43 | 5700 | 25 000 | 800 | 0 |
| 3 | 25 | 2500 | 24 000 | 400 | 0 |
| 4 | 67 | 4600 | 40 000 | 2000 | 1 |
| 5 | 38 | 35 000 | 2 500 000 | 10 000 | 0 |
Tabela 1. Dane kredytowe w formie tabelarycznej
Ludzie używają algorytmów uczenia maszynowego w różnych aplikacjach. Tabela 2. przedstawia niektóre biznesowe przypadki użycia, które pozwalają na zastosowanie algorytmów i modeli uczenia maszynowego bez głębokiego uczenia maszynowego. Znajdują się tam również krótkie opisy potencjalnych danych, zmiennych docelowych oraz wybranych odpowiednich algorytmów.
| Przypadek użycia | Przykłady danych | Wartość docelowa (modelowana) | Użyty algorytm/model |
| Rekomendacje artykułów na blogu | Identyfikatory artykułów czytanych przez użytkowników, czas spędzony nad każdym z nich | Preferencje użytkowników wobec artykułów | Filtrowanie grupowe z naprzemiennymi najmniejszymi kwadratami |
| Scoring kredytowy kredytów hipotecznych | Historia transakcyjna i kredytowa, dane o dochodach potencjalnego kredytobiorcy | Wartość binarna pokazująca, czy pożyczka zostanie spłacona w całości, czy też będzie niespłacona | LightGBM |
| Przewidywanie rezygnacji użytkowników premium z gry mobilnej | Czas spędzony na codziennej grze, czas od pierwszego uruchomienia, postęp w grze | Wartość binarna pokazująca, czy użytkownik zamierza anulować subskrypcję w przyszłym miesiącu | XGBoost |
| Wykrywanie oszustw związanych z kartą kredytową | Historyczne dane transakcji kartą kredytową – kwota, miejsce, data i godzina | Wartość binarna pokazująca, czy transakcja kartą kredytową jest fałszywa | Losowy las |
| Segmentacja klientów sklepu internetowego | Historia zakupów członków programu lojalnościowego | Numer segmentu przypisany do każdego klienta | K-średnie |
| Predykcyjne utrzymanie parku maszynowego | Dane z czujników wydajności, temperatury, wilgotności itp. | Jedna z następujących klas – „w porządku”, „do obserwacji”, „wymaga konserwacji” | Drzewo decyzyjne |
Tabela 2. Przykłady przypadków użycia uczenia maszynowego
Głębokie uczenie i głębokie sieci neuronowe
Głębokie uczenie jest częścią uczenia maszynowego, w którym wykorzystujemy modele określonego typu, zwane głębokimi sztucznymi sieciami neuronowymi (ANN). Od momentu wprowadzenia sztuczne sieci neuronowe przeszły rozległy proces ewolucji. Doprowadziło to do powstania wielu podtypów, z których niektóre są bardzo skomplikowane. Ale żeby je przedstawić, najlepiej wyjaśnić jedną z ich podstawowych form – perceptron wielowarstwowy (MPL).
Perceptron wielowarstwowy
Mówiąc najprościej, MLP ma postać wykresu (sieci) wierzchołków (zwanych również neuronami) i krawędzi (reprezentowanych przez liczby zwane wagami). Neurony są ułożone warstwami, a neurony w kolejnych warstwach są ze sobą połączone. Dane przepływają przez sieć od warstwy wejściowej do warstwy wyjściowej. Dane są następnie przekształcane w neuronach i na krawędziach między nimi. Gdy punkt danych przechodzi przez całą sieć, warstwa wyjściowa zawiera przewidywane wartości w swoich neuronach.
Za każdym razem, gdy część danych treningowych przechodzi przez sieć, porównujemy przewidywania z odpowiadającymi im prawdziwymi wartościami. To pozwala nam dostosować parametry (wagi) modelu, aby lepiej przewidywać. Możemy to zrobić za pomocą algorytmu zwanego propagacją wsteczną. Po kilku iteracjach, jeśli struktura modelu jest dobrze zaprojektowana, aby rozwiązać problem z uczeniem maszynowym.
Uzyskanie modelu o wysokiej dokładności
Po wielokrotnym przejściu wystarczającej ilości danych przez sieć uzyskujemy model o wysokiej dokładności. W praktyce istnieje wiele transformacji, które można zastosować w neuronach. To sprawia, że SSN są bardzo elastyczne i wydajne. Siła SSN ma jednak swoją cenę. Zwykle im bardziej skomplikowana struktura modelu, tym więcej danych i czasu potrzeba na nauczenie go z dużą dokładnością.
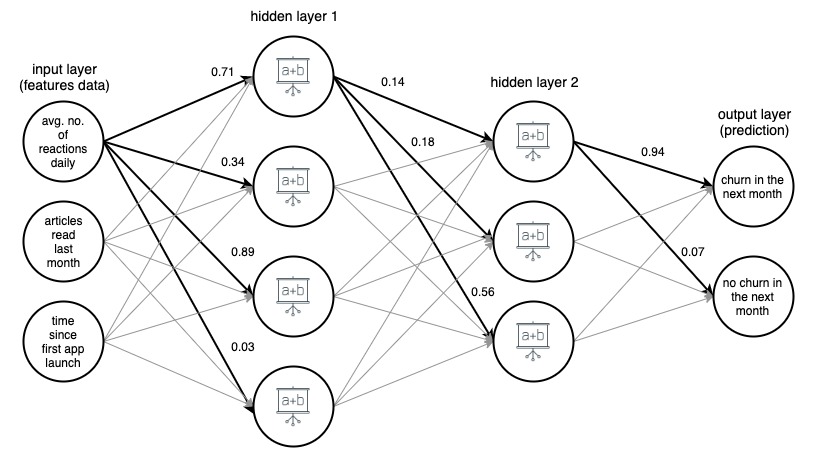
Rysunek 1. (draw.io) Struktura 4-warstwowej sztucznej sieci neuronowej, przewidująca, czy użytkownik aplikacji informacyjnej odejdzie w przyszłym miesiącu, oparta na trzech prostych funkcjach.
Dla jasności wagi zostały zaznaczone tylko dla wybranych (pogrubionych) krawędzi, ale każda krawędź ma swoją wagę. Dane przepływają z warstwy wejściowej do warstwy wyjściowej, przechodząc przez 2 ukryte warstwy pośrodku. Na każdej krawędzi wartość wejściowa jest mnożona przez wagę krawędzi, a wynikowy iloczyn trafia do węzła, w którym kończy się krawędź. Następnie w każdym z węzłów w warstwach ukrytych sygnały przychodzące z krawędzi są sumowane, a następnie przekształcane jakąś funkcją. Wynik tych przekształceń jest następnie traktowany jako dane wejściowe do następnej warstwy.
W warstwie wyjściowej przychodzące dane są ponownie sumowane i przekształcane, dając wynik w postaci dwóch liczb – prawdopodobieństwo, że użytkownik zrezygnuje z aplikacji w następnym miesiącu oraz prawdopodobieństwo, że tego nie zrobi.
Zaawansowane typy sieci neuronowych
W sieciach neuronowych bardziej zaawansowanych typów warstwy mają znacznie bardziej złożoną strukturę. Składają się one nie tylko z prostych, gęstych warstw z jednooperacyjnymi neuronami znanymi z MLP, ale także z dużo bardziej skomplikowanych, wielooperacyjnych warstw, takich jak warstwy splotowe i rekurencyjne.
Warstwy splotowe i rekurencyjne
Warstwy splotowe są najczęściej używane w aplikacjach widzenia komputerowego . Składają się z małych tablic liczb, które przesuwają się po pikselowej reprezentacji obrazu. Wartości pikseli są mnożone przez te liczby, a następnie agregowane, dając nową, skondensowaną reprezentację obrazu.
Warstwy rekurencyjne służą do modelowania uporządkowanych danych sekwencyjnych, takich jak szeregi czasowe lub tekst . Stosują bardzo skomplikowane przekształcenia wieloargumentowe do przychodzących danych, próbując ustalić zależności między elementami sekwencji. Niemniej jednak, bez względu na rodzaj i strukturę sieci, zawsze istnieją pewne (jedną lub więcej) warstwy wejściowa i wyjściowa oraz ściśle określone ścieżki i kierunki przepływu danych przez sieć.
Ogólnie rzecz biorąc, głębokie sieci neuronowe to sieci ANN z wieloma warstwami. Obrazy 1, 2 i 3 poniżej przedstawiają architektury wybranych głębokich sztucznych sieci neuronowych. Wszystkie zostały opracowane i przeszkolone w Google oraz udostępnione publicznie. Dają wyobrażenie o tym, jak skomplikowane są obecnie stosowane głębokie sztuczne sieci o wysokiej dokładności.
Te sieci mają ogromne rozmiary. Na przykład częściowo pokazany na obrazku 3 InceptionResNetV2 ma 572 warstwy i łącznie ponad 55 milionów parametrów! Wszystkie zostały opracowane jako modele klasyfikacji obrazów (przypisują danemu obrazowi etykietę, np. 'samochód') i zostały przeszkolone na obrazach z zestawu ImageNet, składającego się z ponad 14 milionów obrazków z etykietami.

Rysunek 2. Struktura NASNetMobile (pakiet keras)

Rysunek 3. Struktura XCeption (pakiet Keras)

Rysunek 4. Struktura części (około 25%) InceptionResNetV2 (pakiet Keras)
W ostatnich latach obserwujemy wielki rozwój w Deep Learningu i jego zastosowaniach. Owocem tego postępu jest wiele „inteligentnych” funkcji naszych smartfonów i aplikacji. Chociaż idea SSN nie jest nowa, ten niedawny boom jest wynikiem spełnienia kilku warunków. Przede wszystkim odkryliśmy potencjał obliczeń GPU. Architektura jednostek przetwarzania graficznego jest świetna do obliczeń równoległych, bardzo pomocna w wydajnym uczeniu głębokim.
Co więcej, rozwój usług przetwarzania w chmurze sprawił, że dostęp do wysokowydajnego sprzętu stał się znacznie łatwiejszy, tańszy i możliwy na znacznie większą skalę. Wreszcie, moc obliczeniowa najnowszych urządzeń mobilnych jest wystarczająco duża, aby zastosować modele Deep Learning, tworząc ogromny rynek potencjalnych użytkowników funkcji opartych na DNN.
Zastosowania modeli Deep Learning
Modele Deep Learning są zwykle stosowane do problemów, które dotyczą danych, które nie mają prostej struktury wierszowo-kolumnowej, takiej jak klasyfikacja obrazów lub tłumaczenie języka, ponieważ świetnie sprawdzają się w operowaniu na danych nieustrukturyzowanych i złożonych, które te zadania obsługują — obrazy, tekst , i dźwięk. Istnieją problemy z obsługą danych tego typu i rozmiarów za pomocą klasycznych algorytmów uczenia maszynowego, a tworzenie i stosowanie pewnych głębokich sieci neuronowych do tych problemów spowodowało ogromne postępy w dziedzinie rozpoznawania obrazów, rozpoznawania mowy, klasyfikacji tekstu i tłumaczenia języka w ostatnie kilka lat.
Zastosowanie Deep Learning do tych problemów było możliwe dzięki temu, że DNN akceptują wielowymiarowe tablice liczb, zwane tensorami, zarówno jako dane wejściowe, jak i wyjściowe, oraz mogą śledzić przestrzenne i czasowe relacje między ich elementami. Na przykład, możemy przedstawić obraz jako trójwymiarowy tensor, gdzie wymiar jeden i drugi reprezentują rozdzielczość obrazu cyfrowego (tak samo jak rozmiary odpowiednio szerokości i wysokości obrazu), a trzeci wymiar reprezentuje kolor RGB kodowanie każdego z pikseli (więc trzeci wymiar ma rozmiar 3).
Pozwala to nie tylko na reprezentowanie wszystkich informacji o obrazie w tensorze, ale także na zachowanie relacji przestrzennych między pikselami, co okazuje się kluczowe w zastosowaniu tzw. warstw splotowych, kluczowych w skutecznej klasyfikacji obrazów i sieciach rozpoznawania.
Elastyczność sieci neuronowych w strukturach wejściowych i wyjściowych pomaga również w innych zadaniach, takich jak tłumaczenie języka . W przypadku danych tekstowych zasilamy głębokie sieci neuronowe reprezentacjami liczbowymi słów, uporządkowanymi według ich wyglądu w tekście. Każde słowo jest reprezentowane przez wektor składający się ze stu lub kilkuset liczb, obliczany (zwykle przy użyciu innej sieci neuronowej) tak, aby relacje między wektorami odpowiadającymi różnym słowom naśladowały relacje samych słów. Te reprezentacje języka wektorowego, zwane osadzaniami, po przeszkoleniu mogą być ponownie używane w wielu architekturach i stanowią centralny blok konstrukcyjny modeli językowych sieci neuronowych.
Przykłady wykorzystania modeli Deep Learning
Tabela 3. zawiera przykłady zastosowania modeli Deep Learning do rzeczywistych problemów. Jak widać, problemy rozwiązywane i rozwiązywane przez algorytmy Deep Learning są znacznie bardziej złożone niż zadania rozwiązywane standardowymi technikami uczenia maszynowego, jak te przedstawione w tabeli 1.
Niemniej jednak należy pamiętać, że wiele przypadków użycia uczenia maszynowego może pomóc w dzisiejszych firmach, które nie wymagają tak wyrafinowanych metod i można je skuteczniej (i z większą dokładnością) rozwiązać za pomocą standardowych modeli. Tabela 3. daje również wyobrażenie o tym, ile jest różnych rodzajów warstw sztucznych sieci neuronowych i ile różnych użytecznych architektur można za ich pomocą zbudować.
| Przypadek użycia | Dane | Cel/wynik modelu | Użyty algorytm/model |
| Klasyfikacja obrazu | Obrazy | Etykieta przypisana do obrazu | Konwolucyjna sieć neuronowa (CNN) |
| Wykrywanie obrazu przez samojezdne samochody | Obrazy | Etykiety i obwiedni wokół obiektów zidentyfikowanych na obrazach | Szybki R-CNN |
| Sentyment Analiza komentarze w sklepie internetowym | Tekst komentarzy online | Etykieta sentymentu (np. pozytywna, neutralna, negatywna) przypisana do każdego komentarza | Dwukierunkowa sieć pamięci długoterminowej (LSTM) |
| Harmonizacja melodii | Plik MIDI z melodią | Plik MIDI z tą melodią zharmonizowaną | Sieć generatywnych przeciwników |
| Przewidywanie następnego słowa w an online redaktor | Bardzo duży fragment tekstu (np. zrzut wszystkich artykułów Wikipedii w języku angielskim) | Słowo, które jako następne pasuje do tekstu napisanego do tej pory | Rekurencyjna sieć neuronowa (RNN) z warstwą osadzania |
| Tłumaczenie tekstu na inny język | Tekst w języku polskim | Ten sam tekst przetłumaczony na język angielski | Enkoder – Dekoder Sieć zbudowana z rekurencyjnych warstw sieci neuronowych (RNN) |
| Przeniesienie stylu Moneta na dowolny obraz | Zestaw obrazów obrazów Moneta i zestaw innych obrazów | Obrazy zmodyfikowane tak, aby wyglądały jak namalowane przez Monet | Sieć generatywnych przeciwników |
Tabela 3. Przykłady przypadków użycia Deep Learning
Zalety modeli Deep Learning
Sieci generatywnych przeciwników
Jedno z najbardziej imponujących zastosowań głębokich sieci neuronowych pojawiło się wraz z pojawieniem się generatywnych sieci przeciwstawnych (GAN). Zostały wprowadzone w 2014 roku przez Iana Goodfellowa, a jego pomysł został od tego czasu włączony do wielu narzędzi, niektóre z zaskakującymi rezultatami.
GANy są odpowiedzialne za istnienie aplikacji, które sprawiają, że wyglądamy starzej na zdjęciach, przekształcają obrazy tak, by wyglądały jak namalowane przez van Gogha, a nawet harmonizują melodie dla wielu zespołów instrumentów. Podczas uczenia GAN konkurują ze sobą dwie sieci neuronowe. Sieć generatorów generuje dane wyjściowe z losowych danych wejściowych, podczas gdy dyskryminator próbuje odróżnić wygenerowane instancje od rzeczywistych. Podczas treningu generator uczy się, jak skutecznie „oszukiwać” dyskryminator i ostatecznie jest w stanie wytworzyć dane wyjściowe, które wyglądają, jakby były prawdziwe.
Potężne głębokie sieci neuronowe w aplikacjach mobilnych
Należy zauważyć, że chociaż uczenie głębokiej sieci neuronowej jest bardzo kosztownym obliczeniowo zadaniem i może zająć dużo czasu, zastosowanie wytrenowanej sieci do wykonania określonego zadania nie musi tak być, zwłaszcza jeśli jest stosowane do jednego lub kilka przypadków na raz. Właściwie dzisiaj jesteśmy w stanie uruchomić potężne głębokie sieci neuronowe w aplikacjach mobilnych na naszych smartfonach.
Istnieje nawet kilka architektur sieciowych zaprojektowanych specjalnie z myślą o wydajności w zastosowaniach na urządzeniach mobilnych (np. NASNetMobile przedstawiony na Rysunku 1). Mimo że są one znacznie mniejsze w porównaniu do najnowocześniejszych sieci, nadal są w stanie uzyskać wysoką dokładność predykcji.
Transfer nauki
Kolejną bardzo potężną cechą sztucznych sieci neuronowych, umożliwiającą szerokie wykorzystanie modeli Deep Learning, jest uczenie transferowe . Kiedy już mamy model wytrenowany na niektórych danych (stworzonych przez nas lub pobranych z publicznego repozytorium), możemy zbudować na jego całości lub części, aby uzyskać model, który rozwiązuje nasz konkretny przypadek użycia. Na przykład możemy użyć wstępnie wytrenowanego modelu NASNetLarge, wytrenowanego na ogromnym zestawie danych ImageNet, który przypisuje etykietę do obrazu, wprowadza drobne modyfikacje na górze jego struktury, trenuje go dalej za pomocą nowego zestawu oznaczonych obrazów i użyj go do oznaczenia określonego typu obiektów (np. gatunku drzewa na podstawie obrazu jego liścia).
Korzyści z uczenia transferowego
Uczenie transferowe jest bardzo przydatne, ponieważ zwykle uczenie głębokiej sieci neuronowej, która wykona pewne praktyczne, użyteczne zadania, wymaga ogromnych ilości danych i ogromnej mocy obliczeniowej. Może to często oznaczać miliony oznaczonych instancji danych i setki procesorów graficznych (GPU) działających tygodniami.
Nie każdy może sobie pozwolić lub ma dostęp do takich zasobów, co może bardzo utrudnić zbudowanie od podstaw niestandardowego rozwiązania o wysokiej dokładności do, powiedzmy, klasyfikacji obrazów. Na szczęście niektóre wstępnie wytrenowane modele (zwłaszcza sieci do klasyfikacji obrazów i wstępnie wytrenowane macierze osadzania dla modeli językowych) zostały udostępnione za darmo i są dostępne za darmo w łatwej do zastosowania formie (np. jako instancja modelu w Keras, sieciowe API).
Jak wybrać i zbudować odpowiedni model uczenia maszynowego dla swojej aplikacji?
Jeśli chcesz zastosować uczenie maszynowe do rozwiązania problemu biznesowego, prawdopodobnie nie musisz od razu decydować o typie modelu. Zazwyczaj można przetestować kilka podejść. Często kusi, aby zacząć od najbardziej skomplikowanych modeli, ale warto zacząć od prostych i stopniowo zwiększać złożoność stosowanych modeli. Prostsze modele są zwykle tańsze pod względem konfiguracji, czasu obliczeń i zasobów. Co więcej, ich wyniki są doskonałym punktem odniesienia do oceny bardziej zaawansowanych podejść.
Posiadanie takich punktów odniesienia może pomóc analitykom danych ocenić, czy kierunek, w którym rozwijają swoje modele, jest właściwy. Kolejną zaletą jest możliwość ponownego wykorzystania niektórych wcześniej zbudowanych modeli i łączenia ich z nowszymi, tworząc tzw. model zespołowy. Mieszanie modeli różnych typów często daje wyższe metryki wydajności niż każdy z połączonych modeli osobno. Sprawdź również, czy istnieją wstępnie wytrenowane modele, które można wykorzystać i dostosować do Twojego przypadku biznesowego poprzez uczenie transferu.
Więcej praktycznych wskazówek
Przede wszystkim, niezależnie od używanego modelu, upewnij się, że dane są obsługiwane prawidłowo. Pamiętaj o zasadzie „śmieci wchodzą, śmieci wychodzą”. Jeśli dane szkoleniowe dostarczone do modelu są niskiej jakości lub nie zostały odpowiednio oznaczone i wyczyszczone, jest bardzo prawdopodobne, że wynikowy model również będzie działał słabo. Upewnij się również, że model – niezależnie od jego złożoności – został gruntownie zweryfikowany w fazie modelowania, a na koniec przetestowany, czy dobrze uogólnia się na niewidoczne dane.
Z bardziej praktycznego punktu widzenia upewnij się, że stworzone rozwiązanie można wdrożyć produkcyjnie na dostępnej infrastrukturze. A jeśli Twoja firma może zebrać więcej danych, które można wykorzystać do ulepszenia modelu w przyszłości, należy przygotować potok ponownego szkolenia, aby zapewnić jego łatwą aktualizację. Taki potok można nawet skonfigurować tak, aby automatycznie ponownie trenował model z określoną częstotliwością czasową.
Końcowe przemyślenia
Nie zapomnij śledzić wydajności i użyteczności modelu po jego wdrożeniu do produkcji, ponieważ środowisko biznesowe jest bardzo dynamiczne. Niektóre relacje w Twoich danych mogą z czasem ulec zmianie i mogą pojawić się nowe zjawiska. Mogą zatem zmienić wydajność Twojego modelu i powinny być odpowiednio traktowane. Dodatkowo można wymyślić nowe, potężne typy modeli. Z jednej strony mogą sprawić, że Twoje rozwiązanie będzie stosunkowo słabe, z drugiej jednak dadzą Ci możliwość dalszego doskonalenia biznesu i korzystania z najnowszych technologii.
Co więcej, modele Machine i Deep Learning mogą pomóc w tworzeniu zaawansowanych narzędzi dla Twojej firmy i aplikacji oraz zapewnić Twoim klientom wyjątkowe wrażenia . Chociaż tworzenie tych „inteligentnych” funkcji wymaga znacznego wysiłku, ale potencjalne korzyści są tego warte. Upewnij się tylko, że Ty i Twój zespół Data Science wypróbujecie odpowiednie modele i postępujecie zgodnie z dobrymi praktykami, a będziecie na dobrej drodze, aby wzmocnić swoją firmę i aplikacje dzięki najnowocześniejszym rozwiązaniom z zakresu uczenia maszynowego.
Źródła:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/aplikacje/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-wprowadzenie-do-sekwencji-do-sekwencji-nauka-w-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/aplikacje/
- https://arxiv.org/pdf/1707.07012.pdf