
Deep Learning vs. Machine Learning – จะแยกความแตกต่างได้อย่างไร?
เผยแพร่แล้ว: 2020-03-10ในช่วงไม่กี่ปีที่ผ่านมา Machine Learning, Deep Learning และ Artificial Intelligence ได้กลายเป็นคำพูดที่ได้รับความนิยม ด้วยเหตุนี้ คุณจะพบได้ทั่วทั้งสื่อการตลาดและโฆษณาของบริษัทต่างๆ มากขึ้นเรื่อยๆ
แต่ Machine Learning และ Deep Learning คืออะไร? นอกจากนี้ อะไรคือความแตกต่างระหว่างพวกเขา? ในบทความนี้ ฉันจะพยายามตอบคำถามเหล่านี้ และแสดงบางกรณีของแอปพลิเคชัน Deep และ Machine Learning
แมชชีนเลิร์นนิงคืออะไร?
การเรียนรู้ของเครื่อง เป็นส่วนหนึ่งของวิทยาการคอมพิวเตอร์ที่เกี่ยวข้องกับการแสดงเหตุการณ์หรือวัตถุในโลกแห่งความเป็นจริงด้วยแบบจำลองทางคณิตศาสตร์โดยอิงจากข้อมูล โมเดลเหล่านี้สร้างขึ้นด้วยอัลกอริธึมพิเศษที่ปรับโครงสร้างทั่วไปของโมเดลเพื่อให้เหมาะสมกับข้อมูลการฝึก ขึ้นอยู่กับประเภทของปัญหาที่กำลังแก้ไข เรากำหนดอัลกอริธึมการเรียนรู้ของเครื่องและการเรียนรู้ของเครื่องภายใต้การดูแลและไม่ได้รับการดูแล
แมชชีนเลิร์นนิงภายใต้การดูแล vs. แมชชีนเลิร์นนิง
Supervised Machine Learning มุ่งเน้นไปที่การสร้างแบบจำลองที่สามารถถ่ายโอนความรู้ที่เรามีอยู่แล้วเกี่ยวกับข้อมูลที่มีอยู่แล้วไปยังข้อมูลใหม่ ข้อมูลใหม่นี้มองไม่เห็นโดยอัลกอริธึมการสร้างแบบจำลอง (การฝึกอบรม) ในระหว่างขั้นตอนการฝึกอบรม เราจัดเตรียมข้อมูลของคุณสมบัติอัลกอริธึมพร้อมกับค่าที่เกี่ยวข้องที่อัลกอริทึมควรเรียนรู้ที่จะอนุมานจากสิ่งเหล่านี้ (เรียกว่าตัวแปรเป้าหมาย)
ในแมชชีนเลิร์นนิงแบบไม่มีผู้ดูแล เราจัดเตรียมอัลกอริทึมพร้อมฟีเจอร์เท่านั้น ซึ่งช่วยให้สามารถเข้าใจโครงสร้างและ/หรือการพึ่งพาได้ด้วยตนเอง ไม่ได้ระบุตัวแปรเป้าหมายที่ชัดเจน แนวคิดเรื่องการเรียนรู้โดยไม่ได้รับการดูแลในตอนแรกอาจเข้าใจได้ยาก แต่การดูตัวอย่างที่ให้ไว้ในแผนภูมิทั้งสี่ด้านล่างควรทำให้แนวคิดนี้ชัดเจน
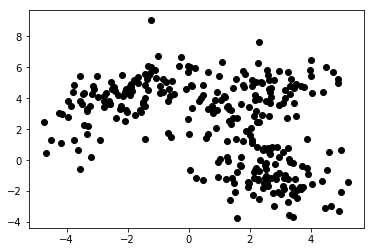
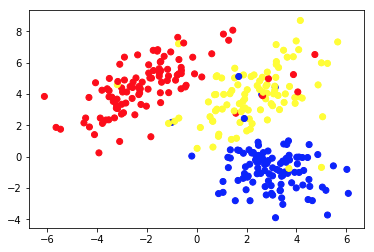
แผนภูมิ 1a แสดงข้อมูลบางส่วนที่อธิบายด้วย 2 คุณลักษณะบนแกน x และ y อันที่ทำเครื่องหมายเป็น 1b แสดงข้อมูลสีเดียวกัน เราใช้อัลกอริธึมการจัดกลุ่ม K- mean เพื่อจัดกลุ่มจุดเหล่านี้เป็น 3 คลัสเตอร์ และกำหนดสีตามนั้น นี่คือตัวอย่างของอัลกอริ ธึ ม Machine Learning ที่ไม่มีผู้ดูแล อัลกอริธึมได้รับเฉพาะคุณสมบัติเท่านั้น และต้องค้นหาป้ายกำกับ (หมายเลขคลัสเตอร์)
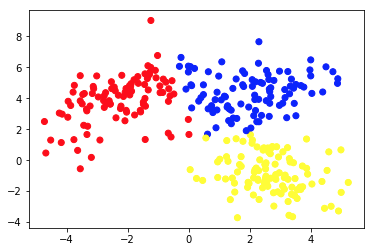
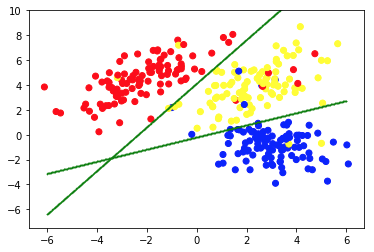
รูปภาพที่สองแสดงแผนภูมิ 2a ซึ่งแสดงชุดข้อมูลที่มีป้ายกำกับ (และระบายสีตามนั้น) ที่แตกต่างกัน เรารู้ว่ากลุ่มแต่ละจุดข้อมูลเป็นของ ระดับความ สำคัญ เราใช้อัลกอริธึม SVM เพื่อค้นหาเส้นตรง 2 เส้น ซึ่งจะแสดงให้เราเห็นว่าจะแบ่งจุดข้อมูลอย่างไรเพื่อให้เหมาะสมกับกลุ่มเหล่านี้มากที่สุด การแยกนี้ไม่สมบูรณ์แบบ แต่นี่เป็นสิ่งที่ดีที่สุดที่สามารถทำได้ด้วยเส้นตรง หากเราต้องการกำหนดกลุ่มให้กับจุดข้อมูลใหม่ที่ไม่มีป้ายกำกับ เราเพียงแค่ต้องตรวจสอบว่ามันอยู่ที่ใดบนเครื่องบิน นี่คือตัวอย่างแอปพลิเคชัน Machine Learning ที่มีการ ควบคุมดูแล
การประยุกต์ใช้โมเดลแมชชีนเลิร์นนิง
อัลกอริธึมการเรียนรู้ของเครื่องมาตรฐานถูกสร้างขึ้นสำหรับการจัดการข้อมูลในรูปแบบตาราง ซึ่งหมายความว่าเพื่อที่จะใช้พวกเขา เราจำเป็นต้องมีโต๊ะบางประเภท ในตารางดังกล่าว แถวของตารางสามารถคิดได้ว่าเป็นตัวอย่างของวัตถุจำลอง (เช่น เงินกู้) ในเวลาเดียวกัน คอลัมน์ควรถูกมองว่าเป็นคุณลักษณะ (ลักษณะ) ของกรณีนี้โดยเฉพาะ (เช่น การชำระเงินกู้รายเดือน รายได้ต่อเดือนของผู้กู้)

อยากรู้เกี่ยวกับการพัฒนาแมชชีนเลิร์นนิง?
เรียนรู้เพิ่มเติมตารางที่ 1 เป็นตัวอย่างสั้นๆ ของข้อมูลดังกล่าว แน่นอนว่าไม่ได้หมายความว่าข้อมูลที่บริสุทธิ์จะต้องเป็นแบบตารางและมีโครงสร้าง แต่ถ้าเราต้องการใช้อัลกอริธึม Machine Learning มาตรฐานกับชุดข้อมูลบางชุด เรามักจะต้องล้าง ผสม และแปลงเป็นตาราง ในการเรียนรู้ภายใต้การดูแล ยังมีคอลัมน์พิเศษหนึ่งคอลัมน์ที่มีค่าเป้าหมาย (เช่น ข้อมูลหากเงินกู้ผิดนัด)
อัลกอริธึมการฝึกอบรมพยายามปรับโครงสร้างทั่วไปของโมเดลให้เข้ากับข้อมูลเหล่านี้ อัลกอริธึมดังกล่าวทำได้โดยการปรับพารามิเตอร์ของโมเดล ซึ่งส่งผลให้โมเดลที่อธิบายความสัมพันธ์ระหว่างข้อมูลที่กำหนดและตัวแปรเป้าหมายได้อย่างแม่นยำที่สุด
สิ่งสำคัญคือโมเดลนี้ไม่เพียงแต่จะพอดีกับข้อมูลการฝึกที่ให้มาเท่านั้น แต่ยังสามารถสรุปได้ด้วย ลักษณะทั่วไปหมายความว่าเราสามารถใช้แบบจำลองเพื่อสรุปเป้าหมายสำหรับอินสแตนซ์ที่ไม่ได้ใช้ระหว่างการฝึก นอกจากนี้ยังเป็นคุณลักษณะที่สำคัญของแบบจำลองที่มีประโยชน์อีกด้วย การสร้างแบบจำลองทั่วไปที่ดีไม่ใช่เรื่องง่าย มักต้องใช้เทคนิคการตรวจสอบที่ซับซ้อนและการทดสอบแบบจำลองอย่างละเอียด
| เงินกู้_id | ผู้ยืม_อายุ | รายได้_รายเดือน | เงินกู้_amount | month_payment | ค่าเริ่มต้น |
| 1 | 34 | 10,000 | 100,000 | 1,200 | 0 |
| 2 | 43 | 5,700 | 25,000 | 800 | 0 |
| 3 | 25 | 2,500 | 24,000 | 400 | 0 |
| 4 | 67 | 4,600 | 40,000 | 2,000 | 1 |
| 5 | 38 | 35,000 | 2,500,000 | 10,000 | 0 |
ตารางที่ 1. ข้อมูลเงินกู้ในรูปแบบตาราง
ผู้คนใช้อัลกอริธึมการเรียนรู้ของเครื่องในแอปพลิเคชันต่างๆ ตารางที่ 2 แสดงกรณีการใช้งานทางธุรกิจบางอย่างที่อนุญาตให้ใช้อัลกอริธึมการเรียนรู้ของเครื่องและโมเดลที่ไม่ใช่เชิงลึก นอกจากนี้ยังมีคำอธิบายสั้นๆ เกี่ยวกับข้อมูลที่เป็นไปได้ ตัวแปรเป้าหมาย และอัลกอริธึมที่เลือกได้
| ใช้กรณี | ตัวอย่างข้อมูล | มูลค่าเป้าหมาย (แบบจำลอง) | อัลกอริทึม/รุ่นที่ใช้ |
| คำแนะนำของบทความบนเว็บไซต์บล็อก | ID ของบทความที่ผู้ใช้อ่าน เวลาที่ใช้กับแต่ละรายการ | การตั้งค่าของผู้ใช้ที่มีต่อบทความ | การกรองการทำงานร่วมกันด้วยการสลับช่องสี่เหลี่ยมน้อยที่สุด |
| คะแนนเครดิตของการจำนอง | ประวัติการทำธุรกรรมและเครดิต ข้อมูลรายได้ของผู้กู้ที่มีศักยภาพ | ค่าไบนารีแสดงว่าเงินกู้จะได้รับการชำระคืนเต็มจำนวนหรือผิดนัด | LightGBM |
| การคาดคะเนผู้ใช้ระดับพรีเมียมของเกมมือถือ | เวลาที่ใช้เล่นทุกวัน เวลาตั้งแต่เปิดตัวครั้งแรก ความคืบหน้าในเกม | ค่าไบนารีแสดงว่าผู้ใช้กำลังจะยกเลิกการสมัครในเดือนหน้า | XGBoost |
| การตรวจจับการฉ้อโกงบัตรเครดิต | ข้อมูลการทำธุรกรรมบัตรเครดิตในอดีต – จำนวน สถานที่ วันที่ และเวลา | ค่าไบนารีแสดงว่าธุรกรรมบัตรเครดิตเป็นการฉ้อโกงหรือไม่ | ป่าสุ่ม |
| การแบ่งกลุ่มลูกค้าร้านอินเตอร์เน็ต | ประวัติการซื้อของสมาชิกโปรแกรมสะสมคะแนน | หมายเลขเซ็กเมนต์ที่กำหนดให้กับลูกค้าทุกราย | K หมายถึง |
| การบำรุงรักษาเชิงพยากรณ์ของที่จอดรถเครื่องจักร | ข้อมูลจากเซ็นเซอร์ประสิทธิภาพ อุณหภูมิ ความชื้น ฯลฯ | หนึ่งในคลาสต่อไปนี้ - 'ดี', 'สังเกต', 'ต้องการการบำรุงรักษา' | ต้นไม้แห่งการตัดสินใจ |
ตารางที่ 2. ตัวอย่างกรณีการใช้งาน Machine Learning
การเรียนรู้เชิงลึกและโครงข่ายประสาทลึก
Deep Learning เป็นส่วนหนึ่งของ Machine Learning ซึ่งเราใช้โมเดลเฉพาะประเภทที่เรียกว่า Deep Artificial Neural Network (ANN) นับตั้งแต่เปิดตัว โครงข่ายประสาทเทียมได้ผ่านกระบวนการวิวัฒนาการอย่างกว้างขวาง ซึ่งนำไปสู่ประเภทย่อยจำนวนหนึ่ง ซึ่งบางประเภทก็ซับซ้อนมาก แต่เพื่อแนะนำพวกเขา เป็นการดีที่สุดที่จะอธิบายรูปแบบพื้นฐานอย่างใดอย่างหนึ่ง - multilayer perceptron (MPL)
การรับรู้หลายชั้น
พูดง่ายๆ ก็คือ MLP มีรูปแบบของกราฟ (เครือข่าย) ของจุดยอด (เรียกอีกอย่างว่าเซลล์ประสาท) และขอบ (แสดงด้วยตัวเลขที่เรียกว่าน้ำหนัก) เซลล์ประสาทถูกจัดเรียงเป็นชั้น ๆ และเซลล์ประสาทในชั้นที่ต่อเนื่องกันจะเชื่อมต่อกัน ข้อมูลไหลผ่านเครือข่ายจากอินพุตไปยังเลเยอร์เอาต์พุต ข้อมูลจะถูกแปลงที่เซลล์ประสาทและขอบระหว่างพวกเขา เมื่อจุดข้อมูลผ่านเครือข่ายทั้งหมด เลเยอร์เอาต์พุตจะรวมค่าที่คาดการณ์ไว้ในเซลล์ประสาท
ทุกครั้งที่ข้อมูลการฝึกอบรมบางส่วนผ่านเครือข่าย เราจะเปรียบเทียบการคาดคะเนกับค่าจริงที่สอดคล้องกัน ซึ่งช่วยให้เราปรับพารามิเตอร์ (น้ำหนัก) ของแบบจำลองเพื่อให้การคาดการณ์ดีขึ้น เราสามารถทำได้ด้วยอัลกอริธึมที่เรียกว่า backpropagation หลังจากการทำซ้ำหลายครั้ง หากโครงสร้างของแบบจำลองได้รับการออกแบบมาอย่างดีโดยเฉพาะเพื่อจัดการกับปัญหาการเรียนรู้ของเครื่อง
ได้โมเดลที่มีความแม่นยำสูง
เมื่อข้อมูลผ่านเครือข่ายหลายครั้งเพียงพอแล้ว เราจะได้โมเดลที่มีความแม่นยำสูง ในทางปฏิบัติ มีการเปลี่ยนแปลงมากมายที่สามารถนำไปใช้กับเซลล์ประสาทได้ นั่นทำให้ ANN มีความยืดหยุ่นและทรงพลังมาก แม้ว่าพลังของ ANN จะมาพร้อมกับราคาก็ตาม โดยปกติ ยิ่งโครงสร้างของแบบจำลองซับซ้อนมากขึ้นเท่าใด ก็ยิ่งต้องใช้ข้อมูลและเวลามากขึ้นเท่านั้นในการฝึกอบรมให้มีความเที่ยงตรงสูง
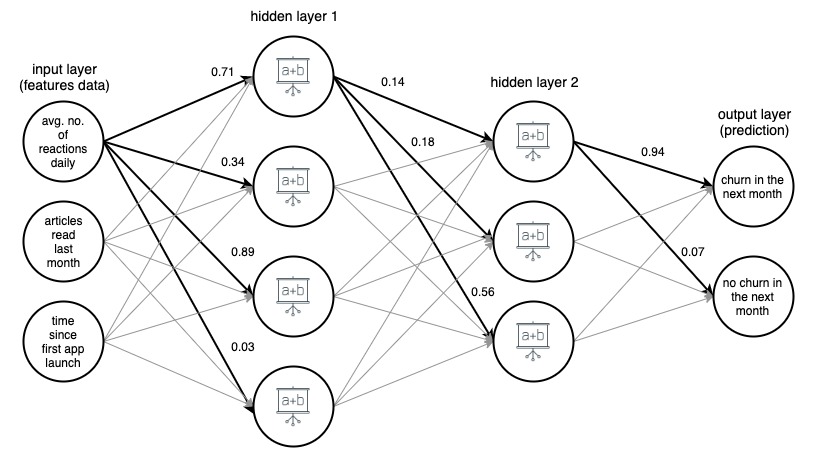
ภาพที่ 1 (draw.io) โครงสร้างของโครงข่ายประสาทเทียมแบบ 4 ชั้น โดยคาดการณ์ว่าผู้ใช้แอปข่าวจะเลิกใช้งานในเดือนหน้าหรือไม่ โดยอิงจากคุณสมบัติง่ายๆ สามประการ
เพื่อความชัดเจน มีการทำเครื่องหมายน้ำหนักสำหรับขอบที่เลือกเท่านั้น (ตัวหนา) แต่ทุกขอบมีน้ำหนักของตัวเอง ข้อมูลไหลจากเลเยอร์อินพุตไปยังเลเยอร์เอาต์พุต ผ่านเลเยอร์ที่ซ่อนอยู่ 2 ชั้นที่อยู่ตรงกลาง ในแต่ละขอบ ค่าอินพุตจะถูกคูณด้วยน้ำหนักของขอบ และผลิตภัณฑ์ที่ได้จะไปที่โหนดที่ขอบสิ้นสุด จากนั้น ในแต่ละโหนดในเลเยอร์ที่ซ่อนอยู่ สัญญาณขาเข้าจากขอบจะถูกสรุปแล้วแปลงด้วยฟังก์ชันบางอย่าง ผลลัพธ์ของการแปลงเหล่านี้จะถือว่าเป็นอินพุตไปยังเลเยอร์ถัดไป
ในเลเยอร์เอาต์พุต ข้อมูลที่เข้ามาจะถูกสรุปและแปลงอีกครั้ง โดยให้ผลลัพธ์เป็นตัวเลขสองตัว – ความน่าจะเป็นที่ผู้ใช้จะเลิกใช้แอปในเดือนถัดไป และความน่าจะเป็นที่ผู้ใช้จะไม่ทำ
โครงข่ายประสาทเทียมขั้นสูง
ในโครงข่ายประสาทเทียมประเภทขั้นสูง เลเยอร์มีโครงสร้างที่ซับซ้อนกว่ามาก พวกมันไม่เพียงแต่ประกอบด้วยชั้นหนาแน่นธรรมดาๆ ที่มีเซลล์ประสาทปฏิบัติการเดียวที่รู้จักจาก MLP แต่ยังรวมถึงเลเยอร์ที่มีการดำเนินการหลายขั้นตอนที่ซับซ้อนกว่ามาก เช่น ชั้น Convolutional และชั้นที่เกิดซ้ำ
ชั้น Convolutional และกำเริบ
เลเยอร์ Convolutional ส่วนใหญ่จะใช้ใน แอปพลิเคชันการ มองเห็นด้วยคอมพิวเตอร์ ประกอบด้วยอาร์เรย์ขนาดเล็กของตัวเลขที่เลื่อนผ่านการแสดงพิกเซลของภาพ ค่าพิกเซลจะถูกคูณด้วยตัวเลขเหล่านี้ จากนั้นจึงรวมเข้าด้วยกัน ทำให้เกิดการแสดงภาพใหม่ ย่อ และย่อ
เลเยอร์ที่เกิดซ้ำจะ ใช้เพื่อสร้างแบบจำลองข้อมูลตามลำดับ เช่น อนุกรมเวลาหรือข้อความ พวกเขาใช้การแปลงหลายอาร์กิวเมนต์ที่ซับซ้อนมากกับข้อมูลขาเข้า พยายามหาการพึ่งพาระหว่างรายการลำดับ อย่างไรก็ตาม ไม่ว่าประเภทและโครงสร้างของเครือข่ายจะเป็นแบบใด ก็มักจะมีชั้นอินพุตและเอาท์พุต (อย่างน้อยหนึ่งชั้น) และเส้นทางและทิศทางที่กำหนดไว้อย่างเคร่งครัดซึ่งข้อมูลไหลผ่านเครือข่าย
โดยทั่วไป Deep Neural Networks คือ ANN ที่มีหลายเลเยอร์ ภาพที่ 1, 2 และ 3 ด้านล่างแสดงสถาปัตยกรรมของโครงข่ายประสาทเทียมแบบลึกที่เลือก พวกเขาทั้งหมดได้รับการพัฒนาและฝึกอบรมที่ Google และเผยแพร่ต่อสาธารณะ พวกเขาให้แนวคิดเกี่ยวกับความซับซ้อนของเครือข่ายประดิษฐ์ที่มีความแม่นยำสูงในปัจจุบันที่ซับซ้อนเพียงใด
เครือข่ายเหล่านี้มีขนาดมหึมา ตัวอย่างเช่น บางส่วนที่แสดงใน Image 3 InceptionResNetV2 มี 572 เลเยอร์ และพารามิเตอร์ทั้งหมดมากกว่า 55 ล้านรายการ! พวกเขาทั้งหมดได้รับการพัฒนาให้เป็นแบบจำลองการจำแนกรูปภาพ (พวกเขากำหนดป้ายกำกับเช่น 'รถยนต์' ให้กับรูปภาพที่กำหนด) และได้รับการฝึกอบรมเกี่ยวกับรูปภาพจากชุด ImageNet ซึ่งประกอบด้วยรูปภาพที่มีป้ายกำกับมากกว่า 14 ล้านภาพ

ภาพที่ 2 โครงสร้างของ NASNetMobile (แพ็คเกจ keras)

ภาพที่ 3 โครงสร้างของ XCeption (แพ็คเกจ keras)

ภาพที่ 4 โครงสร้างของชิ้นส่วน (ประมาณ 25%) ของ InceptionResNetV2 (แพ็คเกจ keras)
ในช่วงไม่กี่ปีที่ผ่านมา เราสังเกตเห็นการพัฒนาที่ยอดเยี่ยมในการเรียนรู้เชิงลึกและการใช้งาน ฟีเจอร์ 'อัจฉริยะ' หลายอย่างของสมาร์ทโฟนและแอปพลิเคชันของเราเป็นผลมาจากความก้าวหน้านี้ แม้ว่าแนวคิดของ ANN จะไม่ใช่เรื่องใหม่ แต่ความเจริญเมื่อเร็วๆ นี้เป็นผลมาจากการปฏิบัติตามเงื่อนไขบางประการ ก่อนอื่น เราได้ค้นพบศักยภาพของการประมวลผลด้วย GPU สถาปัตยกรรมของหน่วยประมวลผลกราฟิกนั้นยอดเยี่ยมสำหรับการคำนวณแบบคู่ขนาน ซึ่งมีประโยชน์มากในการเรียนรู้เชิงลึกอย่างมีประสิทธิภาพ
นอกจากนี้ การเพิ่มขึ้นของบริการคลาวด์คอมพิวติ้งทำให้การเข้าถึงฮาร์ดแวร์ประสิทธิภาพสูงง่ายขึ้น ถูกกว่า และเป็นไปได้ในระดับที่ใหญ่กว่ามาก สุดท้าย พลังในการคำนวณของอุปกรณ์มือถือรุ่นใหม่ล่าสุดนั้นใหญ่พอที่จะใช้โมเดล Deep Learning ได้ ซึ่งสร้างตลาดขนาดใหญ่ที่มีผู้ใช้ที่มีศักยภาพของฟีเจอร์ที่ขับเคลื่อนด้วย DNN
การประยุกต์ใช้โมเดลการเรียนรู้เชิงลึก
โมเดล Deep Learning มักใช้กับปัญหาที่เกี่ยวข้องกับข้อมูลที่ไม่มีโครงสร้างแถว-คอลัมน์อย่างง่าย เช่น การจำแนกรูปภาพหรือการแปลภาษา เนื่องจากใช้งานได้ดีกับข้อมูลที่ไม่มีโครงสร้างและซับซ้อน งานเหล่านี้จัดการได้ เช่น รูปภาพ ข้อความ และเสียง มีปัญหาในการจัดการข้อมูลประเภทและขนาดเหล่านี้ด้วยอัลกอริธึม Machine Learning แบบคลาสสิก และการสร้างและนำโครงข่ายประสาทเทียมเชิงลึกมาใช้กับปัญหาเหล่านี้ได้ก่อให้เกิดการพัฒนาอย่างมากในด้านของการจดจำภาพ การรู้จำคำพูด การจำแนกข้อความ และการแปลภาษาใน ไม่กี่ปีที่ผ่านมา
การประยุกต์ใช้ Deep Learning กับปัญหาเหล่านี้เป็นไปได้เนื่องจาก DNN ยอมรับตารางตัวเลขหลายมิติ เรียกว่า เทนเซอร์ เป็นทั้งอินพุตและเอาต์พุต และสามารถติดตามความสัมพันธ์เชิงพื้นที่และเวลาระหว่างองค์ประกอบต่างๆ ได้ ตัวอย่างเช่น เราสามารถนำเสนอภาพเป็นเมตริกซ์ 3 มิติ โดยที่มิติที่หนึ่งและสองแทนความละเอียดของภาพดิจิทัล (มีขนาดความกว้างและความสูงของภาพตามลำดับ) และมิติที่สามแสดงถึงสี RGB การเข้ารหัสของแต่ละพิกเซล (ดังนั้นมิติที่สามคือขนาด 3)
สิ่งนี้ช่วยให้เราไม่เพียงแต่แสดงข้อมูลทั้งหมดเกี่ยวกับภาพในเทนเซอร์เท่านั้น แต่ยังรักษาความสัมพันธ์เชิงพื้นที่ระหว่างพิกเซล ซึ่งกลายเป็นสิ่งสำคัญในการประยุกต์ใช้เลเยอร์ที่เรียกว่า Convolutional Layers ซึ่งมีความสำคัญอย่างยิ่งต่อการจัดหมวดหมู่ภาพที่ประสบความสำเร็จและเครือข่ายการจดจำ
ความยืดหยุ่นของโครงข่ายประสาทเทียมในโครงสร้างอินพุตและเอาต์พุตยังช่วยในงานอื่นๆ เช่น การแปลภาษา เมื่อต้องจัดการกับข้อมูลข้อความ เราป้อนเครือข่ายประสาทเทียมระดับลึกด้วยการแสดงตัวเลขของคำ เรียงลำดับตามลักษณะที่ปรากฏของข้อความ แต่ละคำจะแสดงด้วยเวกเตอร์ของตัวเลขหนึ่งร้อยหรือสองสามร้อยตัว คำนวณ (มักใช้โครงข่ายประสาทเทียมที่ต่างกัน) เพื่อให้ความสัมพันธ์ระหว่างเวกเตอร์ที่สอดคล้องกับคำต่างๆ เลียนแบบความสัมพันธ์ของคำเอง การแสดงภาษาเวกเตอร์เหล่านี้ เรียกว่า embeddings เมื่อผ่านการฝึกอบรมมาแล้ว สามารถใช้ซ้ำได้ในหลายสถาปัตยกรรม และเป็นส่วนประกอบสำคัญของแบบจำลองภาษาเครือข่ายประสาทเทียม
ตัวอย่างของโมเดลการเรียนรู้เชิงลึกที่ใช้
ตารางที่ 3 มีตัวอย่างการนำโมเดล Deep Learning ไปใช้กับปัญหาในชีวิตจริง อย่างที่คุณเห็น ปัญหาที่จัดการและแก้ไขโดยอัลกอริธึม Deep Learning นั้นซับซ้อนกว่างานที่แก้ไขด้วยเทคนิค Machine Learning มาตรฐาน เช่นเดียวกับที่แสดงในตารางที่ 1
อย่างไรก็ตาม สิ่งสำคัญที่ต้องจำไว้คือกรณีการใช้งานจำนวนมากที่แมชชีนเลิร์นนิงสามารถช่วยให้ธุรกิจในปัจจุบันไม่จำเป็นต้องใช้วิธีการที่ซับซ้อนเช่นนี้ และสามารถแก้ไขได้อย่างมีประสิทธิภาพมากขึ้น (และมีความแม่นยำสูงขึ้น) ด้วยโมเดลมาตรฐาน ตารางที่ 3 ยังให้แนวคิดเกี่ยวกับจำนวนชั้นของโครงข่ายประสาทเทียมชนิดต่างๆ ที่มีอยู่ และจำนวนสถาปัตยกรรมที่มีประโยชน์ต่างๆ ที่สามารถสร้างได้ด้วย
| ใช้กรณี | ข้อมูล | เป้าหมาย/ผลลัพธ์ของรุ่น | อัลกอริทึม/รุ่นที่ใช้ |
| การจำแนกรูปภาพ | รูปภาพ | ป้ายกำกับที่กำหนดให้กับรูปภาพ | โครงข่ายประสาทเทียม (CNN) |
| การตรวจจับภาพโดยรถยนต์ที่ขับเอง | รูปภาพ | ป้ายและกรอบล้อมรอบวัตถุที่ระบุบนภาพ | R-CNN . เร็ว |
| ความรู้สึก การวิเคราะห์ ความคิดเห็นในร้านค้าออนไลน์ | ข้อความแสดงความคิดเห็นออนไลน์ | ป้ายกำกับความรู้สึก (เช่น บวก เป็นกลาง เชิงลบ) กำหนดให้กับแต่ละความคิดเห็น | เครือข่ายหน่วยความจำระยะสั้นระยะยาวแบบสองทิศทาง (LSTM) |
| การประสานกันของท่วงทำนอง | ไฟล์ MIDI พร้อมทำนอง | ไฟล์ MIDI ที่มีทำนองนี้ประสานกัน | เครือข่ายปฏิปักษ์ทั่วไป |
| คำทำนายถัดไป ใน ออนไลน์ อีเมล บรรณาธิการ | ข้อความขนาดใหญ่มาก (เช่น การถ่ายโอนข้อมูลบทความ Wikipedia ทั้งหมดเป็นภาษาอังกฤษ) | คำที่เข้ากับคำต่อไปของข้อความที่เขียนจนถึงตอนนี้ | Recurrent Neural Network (RNN) พร้อม Embedding layer |
| การแปลข้อความเป็นภาษาอื่น | ข้อความในภาษาโปแลนด์ | ข้อความเดียวกันที่แปลเป็นภาษาอังกฤษ | ตัวเข้ารหัส - เครือข่ายตัวถอดรหัสที่สร้างด้วยเลเยอร์เครือข่ายประสาทเทียมแบบเกิดซ้ำ (RNN) |
| โอนสไตล์ของ Monet ไปยังรูปภาพใด ๆ | ชุดภาพเขียนของโมเนต์ และชุดภาพอื่นๆ | รูปภาพที่ดัดแปลงให้ดูเหมือนวาดโดย Monet | เครือข่ายปฏิปักษ์ทั่วไป |
ตารางที่ 3 ตัวอย่างกรณีการใช้งาน Deep Learning
ข้อดีของโมเดลการเรียนรู้เชิงลึก
เครือข่ายปฏิปักษ์ทั่วไป
หนึ่งในแอปพลิเคชั่นที่น่าประทับใจที่สุดของ Deep Neural Networks นั้นมาพร้อมกับการเพิ่มขึ้นของ Generative Adversarial Networks (GANs) Ian Goodfellow เปิดตัวในปี 2014 และแนวคิดของเขาก็ได้รวมอยู่ในเครื่องมือต่างๆ มากมาย ซึ่งบางอันก็ได้ผลลัพธ์ที่น่าอัศจรรย์
GAN มีหน้าที่รับผิดชอบต่อการมีอยู่ของแอปพลิเคชันที่ทำให้เราดูแก่กว่าในภาพถ่าย แปลงรูปภาพเพื่อให้ดูเหมือนกับว่าถูกวาดโดย Van Gogh หรือแม้แต่ประสานท่วงทำนองสำหรับวงดนตรีหลายวง ในระหว่างการฝึกอบรม GAN โครงข่ายประสาทเทียมสองเครือข่ายจะแข่งขันกัน เครือข่ายตัวสร้างจะสร้างเอาต์พุตจากการป้อนข้อมูลแบบสุ่ม ในขณะที่ผู้แยกแยะจะพยายามบอกอินสแตนซ์ที่สร้างขึ้นจากอินสแตนซ์จริง ในระหว่างการฝึกอบรม นักสร้างจะเรียนรู้วิธี 'หลอก' ผู้แยกแยะให้สำเร็จ และในที่สุดก็สามารถสร้างผลลัพธ์ที่ดูเหมือนของจริงได้
เครือข่ายประสาทลึกที่ทรงพลังในแอพมือถือ
สิ่งสำคัญคือต้องสังเกตว่าแม้ว่าการฝึกโครงข่ายประสาทเทียมระดับลึกจะเป็นงานที่มีราคาแพงมากและอาจใช้เวลานาน แต่ไม่จำเป็นต้องใช้เครือข่ายที่ได้รับการฝึกอบรมมาเพื่อทำงานเฉพาะ โดยเฉพาะอย่างยิ่งถ้าใช้กับสิ่งใดสิ่งหนึ่งหรือ ไม่กี่กรณีในครั้งเดียว อันที่จริง วันนี้เราสามารถเรียกใช้ Deep Neural Network อันทรงพลังในแอปพลิเคชันมือถือบนสมาร์ทโฟนของเราได้
มีแม้กระทั่งสถาปัตยกรรมเครือข่ายบางตัวที่ออกแบบมาโดยเฉพาะให้มีประสิทธิภาพเมื่อใช้กับอุปกรณ์มือถือ (เช่น NASNetMobile ที่แสดงในภาพที่ 1) แม้ว่าจะมีขนาดเล็กกว่ามากเมื่อเทียบกับเครือข่ายที่ล้ำสมัย แต่ก็ยังสามารถได้รับประสิทธิภาพการทำนายที่มีความแม่นยำสูง
ถ่ายทอดการเรียนรู้
คุณลักษณะที่มีประสิทธิภาพอีกอย่างหนึ่งของโครงข่ายประสาทเทียม ทำให้สามารถใช้โมเดล Deep Learning ได้อย่างกว้างขวาง คือ ถ่ายโอนการเรียนรู้ เมื่อเรามีโมเดลที่ได้รับการฝึกอบรมเกี่ยวกับข้อมูลบางอย่างแล้ว (ไม่ว่าจะสร้างขึ้นด้วยตัวเองหรือดาวน์โหลดจากที่เก็บข้อมูลสาธารณะ) เราก็สามารถสร้างแบบจำลองทั้งหมดหรือบางส่วนเพื่อให้ได้โมเดลที่แก้ปัญหาการใช้งานเฉพาะของเราได้ ตัวอย่างเช่น เราสามารถใช้โมเดล NASNetLarge ที่ผ่านการฝึกอบรมล่วงหน้า ซึ่งฝึกฝนบนชุดข้อมูล ImageNet ขนาดใหญ่ ซึ่งกำหนดป้ายกำกับให้กับรูปภาพ ทำการปรับเปลี่ยนเล็กน้อยที่ด้านบนของโครงสร้าง ฝึกฝนเพิ่มเติมด้วยชุดรูปภาพที่มีป้ายกำกับชุดใหม่ และ ใช้เพื่อติดป้ายวัตถุบางประเภท (เช่น ชนิดของต้นไม้ตามภาพใบไม้)
ประโยชน์ของการเรียนรู้การโอนย้าย
การถ่ายโอนการเรียนรู้มีประโยชน์มาก เนื่องจากโดยปกติแล้วการฝึกอบรมโครงข่ายประสาทเทียมเชิงลึกที่จะทำงานที่เป็นประโยชน์และเป็นประโยชน์นั้นต้องใช้ข้อมูลจำนวนมหาศาลและพลังในการคำนวณมหาศาล ซึ่งมักจะหมายถึงอินสแตนซ์ข้อมูลที่มีป้ายกำกับหลายล้านรายการ และหน่วยประมวลผลกราฟิก (GPU) หลายร้อยรายการที่ทำงานเป็นเวลาหลายสัปดาห์
ไม่ใช่ทุกคนที่สามารถจ่ายหรือมีสิทธิ์เข้าถึงสินทรัพย์ดังกล่าว ซึ่งทำให้ยากต่อการสร้างโซลูชันแบบกำหนดเองที่มีความแม่นยำสูงตั้งแต่เริ่มต้น สมมติว่าเป็นการจัดประเภทรูปภาพ โชคดีที่โมเดลที่ได้รับการฝึกมาล่วงหน้าบางรุ่น (โดยเฉพาะเครือข่ายสำหรับการจำแนกรูปภาพและเมทริกซ์การฝังที่ฝึกไว้ล่วงหน้าสำหรับโมเดลภาษา) ได้รับการโอเพนซอร์สและมีให้ใช้งานฟรีในรูปแบบที่ใช้งานง่าย (เช่น อินสแตนซ์โมเดลใน Keras, ระบบประสาท เครือข่าย API)
วิธีเลือกและสร้างโมเดล Machine Learning ที่เหมาะสมสำหรับแอปพลิเคชันของคุณ
เมื่อคุณต้องการใช้แมชชีนเลิร์นนิงเพื่อแก้ปัญหาทางธุรกิจ คุณอาจไม่จำเป็นต้องตัดสินใจเกี่ยวกับประเภทของแบบจำลองทันที มักจะมีวิธีการบางอย่างที่สามารถทดสอบได้ มักจะเป็นการดึงดูดให้เริ่มต้นด้วยโมเดลที่ซับซ้อนที่สุดในตอนแรก แต่ก็คุ้มค่าที่จะเริ่มต้นง่ายๆ และค่อยๆ เพิ่มความซับซ้อนของโมเดลที่นำไปใช้ โมเดลที่เรียบง่ายมักจะมีราคาถูกกว่าในแง่ของการตั้งค่า เวลาในการคำนวณ และทรัพยากร นอกจากนี้ ผลลัพธ์ยังเป็นเกณฑ์มาตรฐานที่ดีในการประเมินแนวทางขั้นสูง
การมีเกณฑ์มาตรฐานดังกล่าวสามารถช่วยให้นักวิทยาศาสตร์ข้อมูลประเมินว่าทิศทางที่พวกเขาพัฒนาแบบจำลองนั้นถูกต้องหรือไม่ ข้อดีอีกประการหนึ่งคือความเป็นไปได้ของการนำโมเดลที่สร้างไว้ก่อนหน้านี้บางส่วนกลับมาใช้ใหม่ และรวมเข้ากับโมเดลที่ใหม่กว่า ทำให้เกิดโมเดลที่เรียกกันว่าวงดนตรี การผสมแบบจำลองประเภทต่างๆ มักจะให้ผลการวัดที่สูงกว่าแบบจำลองที่รวมกันแต่ละแบบเพียงอย่างเดียว นอกจากนี้ ให้ตรวจสอบว่ามีโมเดลที่ผ่านการฝึกอบรมมาแล้วบางส่วนที่สามารถใช้และปรับให้เข้ากับกรณีธุรกิจของคุณผ่านการเรียนรู้แบบโอนย้ายได้หรือไม่
เคล็ดลับการปฏิบัติเพิ่มเติม
ก่อนอื่น ไม่ว่าคุณจะใช้รุ่นใดก็ตาม ตรวจสอบให้แน่ใจว่าข้อมูลได้รับการจัดการอย่างเหมาะสม อย่าลืมกฎ 'ขยะเข้า ขยะออก' หากข้อมูลการฝึกที่มอบให้กับโมเดลมีคุณภาพต่ำหรือไม่ได้รับการติดฉลากและทำความสะอาดอย่างถูกต้อง มีความเป็นไปได้สูงที่แบบจำลองที่ได้จะมีประสิทธิภาพต่ำเช่นกัน ตรวจสอบให้แน่ใจด้วยว่าแบบจำลอง ไม่ว่าจะซับซ้อนเพียงใด ได้รับการตรวจสอบอย่างกว้างขวางในระหว่างขั้นตอนการสร้างแบบจำลอง และในท้ายที่สุด การทดสอบจะสรุปได้ว่าข้อมูลทั่วไปนั้นดีกับข้อมูลที่มองไม่เห็นหรือไม่
ในบันทึกที่เป็นประโยชน์มากขึ้น ตรวจสอบให้แน่ใจว่าโซลูชันที่สร้างขึ้นสามารถนำไปใช้จริงในการผลิตบนโครงสร้างพื้นฐานที่มีอยู่ และหากธุรกิจของคุณสามารถรวบรวมข้อมูลเพิ่มเติมที่สามารถนำมาใช้ในการปรับปรุงแบบจำลองของคุณในอนาคตได้ ก็ควรเตรียมไปป์ไลน์การฝึกอบรมขึ้นใหม่เพื่อให้แน่ใจว่าการอัปเดตนั้นง่าย ไปป์ไลน์ดังกล่าวสามารถตั้งค่าให้ฝึกโมเดลใหม่โดยอัตโนมัติด้วยความถี่ของเวลาที่กำหนดไว้ล่วงหน้า
ความคิดสุดท้าย
อย่าลืมติดตามประสิทธิภาพและความสามารถในการใช้งานของโมเดลหลังจากการปรับใช้กับการผลิต เนื่องจากสภาพแวดล้อมทางธุรกิจมีไดนามิกมาก ความสัมพันธ์บางอย่างภายในข้อมูลของคุณอาจเปลี่ยนแปลงเมื่อเวลาผ่านไป และปรากฏการณ์ใหม่ๆ อาจเกิดขึ้นได้ จึงสามารถเปลี่ยนแปลงประสิทธิภาพของแบบจำลองของคุณได้ และควรได้รับการดูแลอย่างเหมาะสม นอกจากนี้ ยังสามารถประดิษฐ์โมเดลประเภทใหม่ที่ทรงพลังได้ ในแง่หนึ่ง สิ่งเหล่านี้สามารถทำให้โซลูชันของคุณค่อนข้างอ่อนแอ แต่ในทางกลับกัน ให้โอกาสคุณในการปรับปรุงธุรกิจของคุณต่อไปและใช้ประโยชน์จากเทคโนโลยีใหม่ล่าสุด
ยิ่งไปกว่านั้น โมเดล Machine และ Deep Learning สามารถช่วยคุณสร้างเครื่องมือที่ทรงพลังสำหรับธุรกิจและแอปพลิเคชันของคุณ และมอบประสบการณ์ที่ยอดเยี่ยมให้กับลูกค้าของคุณ แม้ว่าการสร้างคุณลักษณะ 'อัจฉริยะ' เหล่านี้ต้องใช้ความพยายามอย่างมาก แต่ประโยชน์ที่เป็นไปได้นั้นคุ้มค่า เพียงตรวจสอบให้แน่ใจว่าคุณและทีม Data Science ของคุณลองใช้แบบจำลองที่เหมาะสมและปฏิบัติตามแนวทางปฏิบัติที่ดี แล้วคุณจะอยู่ในเส้นทางที่ถูกต้องเพื่อส่งเสริมธุรกิจและแอปพลิเคชันของคุณด้วยโซลูชันการเรียนรู้ของเครื่องที่ล้ำสมัย
ที่มา:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf