
Deep Learning vs Machine Learning – comment faire la différence ?
Publié: 2020-03-10Ces dernières années, Machine Learning, Deep Learning et Intelligence Artificielle sont devenus des mots à la mode. En conséquence, vous pouvez les trouver partout dans les supports marketing et les publicités de plus en plus d'entreprises.
Mais que sont le Machine Learning et le Deep Learning ? Aussi, quelles sont les différences entre eux? Dans cet article, je vais essayer de répondre à ces questions, et vous montrer quelques cas d'applications de Deep et Machine Learning.
Qu'est-ce que l'apprentissage automatique ?
L'apprentissage automatique est une partie de l'informatique qui traite de la représentation d'événements ou d'objets du monde réel avec des modèles mathématiques, basés sur des données. Ces modèles sont construits avec des algorithmes spéciaux qui adaptent la structure générale du modèle afin qu'il corresponde aux données d'apprentissage. En fonction du type de problème à résoudre, nous définissons des algorithmes de Machine Learning et de Machine Learning supervisés et non supervisés.
Apprentissage automatique supervisé ou non supervisé
L'apprentissage automatique supervisé se concentre sur la création de modèles capables de transférer les connaissances que nous avons déjà sur les données disponibles vers de nouvelles données. Les nouvelles données ne sont pas vues par l'algorithme de construction de modèle (apprentissage) pendant la phase d'apprentissage. Nous fournissons un algorithme avec les données des caractéristiques ainsi que les valeurs correspondantes que l'algorithme doit apprendre à en déduire (ce que l'on appelle la variable cible).
Dans le Machine Learning non supervisé, nous ne fournissons que des fonctionnalités à l'algorithme. Cela lui permet de comprendre lui-même leur structure et/ou leurs dépendances. Aucune variable cible claire n'est spécifiée. La notion d'apprentissage non supervisé peut être difficile à saisir au début, mais un coup d'œil aux exemples fournis dans les quatre tableaux ci-dessous devrait clarifier cette idée.
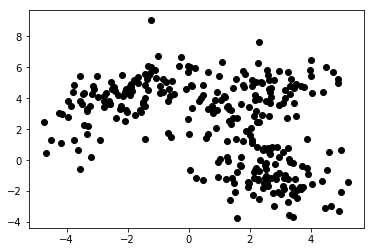
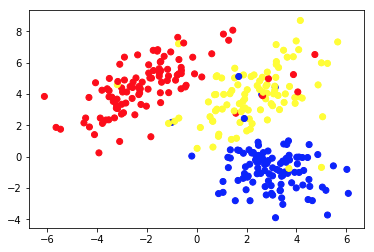
Le graphique 1a présente quelques données décrites avec 2 caractéristiques sur les axes x et y . Celui marqué comme 1b montre les mêmes données colorées. Nous avons utilisé l'algorithme de clustering K- means pour regrouper ces points en 3 clusters et les colorer en conséquence. Ceci est un exemple d'algorithme d'apprentissage automatique non supervisé . L'algorithme ne recevait que les caractéristiques et les étiquettes (numéros de cluster) devaient être déterminées.
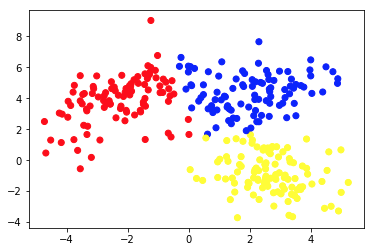
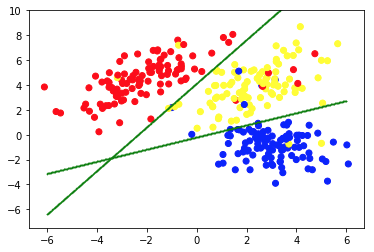
La deuxième image montre le graphique 2a, qui présente un ensemble différent de données étiquetées (et colorées en conséquence). Nous connaissons a priori les groupes auxquels chacun des points de données appartient. Nous utilisons un algorithme SVM pour trouver 2 lignes droites qui nous montreraient comment diviser les points de données pour s'adapter au mieux à ces groupes. Cette division n'est pas parfaite, mais c'est le mieux que l'on puisse faire avec des lignes droites. Si nous voulons affecter un groupe à un nouveau point de données non étiqueté, il nous suffit de vérifier où il se trouve sur le plan. Ceci est un exemple d'application d'apprentissage automatique supervisé .
Applications des modèles d'apprentissage automatique
Des algorithmes d'apprentissage automatique standard sont créés pour gérer les données sous forme de tableau. Cela signifie que pour les utiliser, nous avons besoin d'une sorte de table. Dans de tels tableaux, les rangées peuvent être considérées comme des instances de l'objet modélisé (par exemple, un prêt). Dans le même temps, les colonnes doivent être considérées comme des caractéristiques (caractéristiques) de ce cas particulier (par exemple, paiement mensuel du prêt, revenu mensuel de l'emprunteur).

Intéressé par le développement de l'apprentissage automatique ?
Apprendre encore plusLe tableau 1. est un très court exemple de telles données. Bien sûr, cela ne signifie pas que les données pures elles-mêmes doivent être tabulaires et structurées. Mais si nous voulons appliquer un algorithme d'apprentissage automatique standard sur un ensemble de données, nous devons généralement le nettoyer, le mélanger et le transformer en table. Dans l'apprentissage supervisé, il y a aussi une colonne spéciale qui contient la valeur cible (par exemple, des informations si le prêt est en défaut).
L'algorithme d'apprentissage essaie d'adapter la structure générale du modèle à ces données. Ledit algorithme le fait en ajustant les paramètres du modèle. Cela se traduit par un modèle qui décrit la relation entre les données données et la variable cible aussi précisément que possible.
Il est important que le modèle non seulement s'adapte bien aux données d'entraînement données, mais qu'il soit également capable de généraliser. La généralisation signifie que nous pouvons utiliser le modèle pour déduire la cible pour les instances non utilisées pendant la formation. C'est aussi une caractéristique cruciale d'un modèle utile. Construire un modèle bien généralisant n'est pas une tâche facile. Cela nécessite souvent des techniques de validation sophistiquées et des tests de modèle approfondis.
| id_prêt | age_emprunteur | revenu_mensuel | montant du prêt | paiement mensuel | défaut |
| 1 | 34 | 10 000 | 100 000 | 1 200 | 0 |
| 2 | 43 | 5 700 | 25 000 | 800 | 0 |
| 3 | 25 | 2 500 | 24 000 | 400 | 0 |
| 4 | 67 | 4 600 | 40 000 | 2 000 | 1 |
| 5 | 38 | 35 000 | 2 500 000 | 10 000 | 0 |
Tableau 1. Données sur les prêts sous forme de tableau
Les gens utilisent des algorithmes d'apprentissage automatique dans une variété d'applications. Le tableau 2. présente quelques cas d'utilisation métier permettant l'appliance d'algorithmes et de modèles d'apprentissage automatique non profond. Il existe également de brèves descriptions des données potentielles, des variables cibles et des algorithmes applicables sélectionnés.
| Cas d'utilisation | Exemples de données | Valeur cible (modélisée) | Algorithme/modèle utilisé |
| Recommandations d'articles sur un site de blog | ID des articles lus par les utilisateurs, temps passé sur chacun d'eux | Préférences des utilisateurs envers les articles | Filtrage collaboratif avec moindres carrés alternés |
| Pointage de crédit des prêts hypothécaires | Historique des transactions et des crédits, données sur les revenus d'un emprunteur potentiel | Valeur binaire indiquant si un prêt sera remboursé intégralement ou s'il sera défaillant | LightGBM |
| Prédire l'attrition des utilisateurs premium d'un jeu mobile | Temps passé à jouer quotidiennement, temps depuis le premier lancement, progression dans le jeu | Valeur binaire indiquant si un utilisateur va annuler son abonnement le mois prochain | XGBoost |
| Détection de fraude à la carte de crédit | Données historiques sur les transactions par carte de crédit – montant, lieu, date et heure | Valeur binaire indiquant si une transaction par carte de crédit est frauduleuse | Forêt aléatoire |
| Segmentation des clients d'une boutique en ligne | Historique des achats des membres du programme de fidélité | Numéro de segment attribué à chaque client | K-signifie |
| Maintenance prédictive d'un parc machine | Données des capteurs de performance, de température, d'humidité, etc. | L'une des classes suivantes - 'bien', 'à observer', 'nécessite un entretien' | Arbre de décision |
Tableau 2. Exemples de cas d'utilisation de Machine Learning
Apprentissage profond et réseaux de neurones profonds
L'apprentissage profond fait partie de l'apprentissage automatique dans lequel nous utilisons des modèles d'un type spécifique, appelés réseaux de neurones artificiels profonds (ANN). Depuis leur introduction, les réseaux de neurones artificiels ont traversé un vaste processus d'évolution. Cela a conduit à un certain nombre de sous-types, dont certains sont très compliqués. Mais pour les présenter, il est préférable d'expliquer l'une de leurs formes de base - un perceptron multicouche (MPL).
Perceptron multicouche
En termes simples, un MLP a la forme d'un graphe (réseau) de sommets (également appelés neurones) et d'arêtes (représentées par des nombres appelés poids). Les neurones sont disposés en couches et les neurones des couches consécutives sont connectés les uns aux autres. Les données circulent sur le réseau de la couche d'entrée à la couche de sortie. Les données sont ensuite transformées au niveau des neurones et des bords entre eux. Une fois qu'un point de données traverse l'ensemble du réseau, la couche de sortie contient les valeurs prédites dans ses neurones.
Chaque fois qu'une partie des données d'apprentissage passe par le réseau, nous comparons les prédictions avec les vraies valeurs correspondantes. Cela nous permet d'adapter les paramètres (pondérations) du modèle pour faire de meilleures prédictions. Nous pouvons le faire avec un algorithme appelé rétropropagation. Après un certain nombre d'itérations, si la structure du modèle est bien conçue spécifiquement pour résoudre le problème d'apprentissage automatique en question.
Obtenir un modèle de haute précision
Une fois que suffisamment de données ont traversé le réseau plusieurs fois, nous obtenons un modèle de haute précision. En pratique, de nombreuses transformations peuvent être appliquées aux neurones. Cela rend les ANN très flexibles et puissants. La puissance des ANN a cependant un prix. Habituellement, plus la structure du modèle est compliquée, plus il faut de données et de temps pour l'entraîner avec une grande précision.
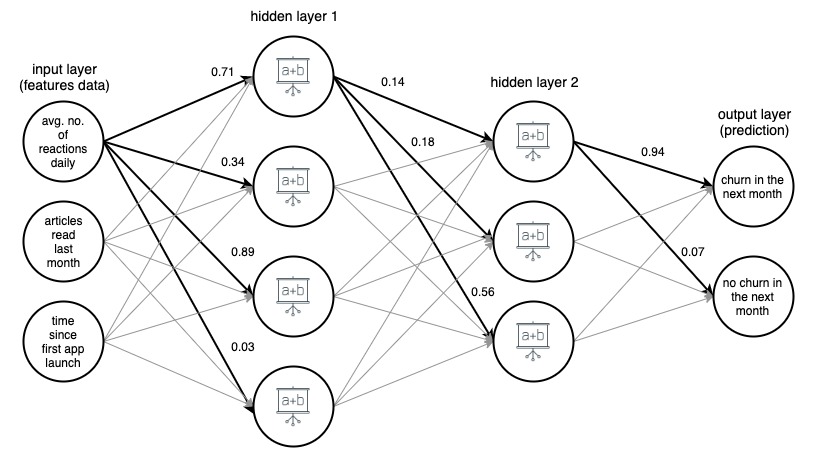
Image 1. (draw.io) Structure d'un réseau de neurones artificiels à 4 couches, prédisant si un utilisateur d'une application d'actualités se désabonnera le mois prochain, sur la base de trois fonctionnalités simples.
Pour plus de clarté, les poids ont été marqués uniquement pour les bords sélectionnés (en gras), mais chaque bord a son propre poids. Les données circulent de la couche d'entrée à la couche de sortie, en passant par 2 couches cachées au milieu. Sur chaque arête, une valeur d'entrée est multipliée par le poids de l'arête, et le produit résultant va au nœud auquel l'arête se termine. Ensuite, dans chacun des nœuds des couches cachées, les signaux entrants des bords sont additionnés puis transformés avec une fonction. Le résultat de ces transformations est ensuite traité comme une entrée pour la couche suivante.
Dans la couche de sortie, les données entrantes sont à nouveau additionnées et transformées, donnant le résultat sous la forme de deux nombres - la probabilité qu'un utilisateur quitte l'application le mois prochain et la probabilité qu'il ne le fasse pas.
Types avancés de réseaux de neurones
Dans les réseaux de neurones de types plus avancés, les couches ont une structure beaucoup plus complexe. Ils se composent non seulement de couches denses simples avec des neurones à une opération connus des MLP, mais aussi de couches multi-opérations beaucoup plus compliquées comme les couches convolutionnelles et récurrentes.
Couches convolutives et récurrentes
Les couches convolutives sont principalement utilisées dans les applications de vision par ordinateur . Ils consistent en de petits tableaux de nombres qui glissent sur la représentation en pixels de l'image. Les valeurs de pixel sont multipliées par ces nombres, puis agrégées, ce qui donne une nouvelle représentation condensée de l'image.
Les couches récurrentes sont utilisées pour modéliser des données séquentielles ordonnées telles que des séries chronologiques ou du texte . Ils appliquent des transformations multi-arguments très compliquées aux données entrantes, en essayant de comprendre les dépendances entre les éléments de séquence. Néanmoins, quels que soient le type et la structure du réseau, il existe toujours des (une ou plusieurs) couches d'entrée et de sortie, ainsi que des chemins et des directions strictement définis dans lesquels les données circulent à travers le réseau.
En général, les réseaux de neurones profonds sont des ANN à plusieurs couches. Les images 1, 2 et 3 ci-dessous montrent des architectures de réseaux de neurones artificiels profonds sélectionnés. Ils ont tous été développés et formés chez Google, et mis à la disposition du public. Ils donnent une idée de la complexité des réseaux artificiels profonds de haute précision utilisés aujourd'hui.
Ces réseaux ont des tailles énormes. Par exemple, partiellement montré dans l'image 3, InceptionResNetV2 a 572 couches et plus de 55 millions de paramètres au total ! Ils ont tous été développés en tant que modèles de classification d'images (ils attribuent une étiquette, par exemple «voiture» à une image donnée), et ont été entraînés sur des images de l'ensemble ImageNet, composé de plus de 14 millions d'images étiquetées.
Image 2. Structure de NASNetMobile (paquet keras)


Image 3. Structure de XCeption (package keras)

Image 4. Structure d'une partie (environ 25%) d'InceptionResNetV2 (package keras)
Ces dernières années, nous avons observé un grand développement du Deep Learning et de ses applications. De nombreuses fonctionnalités « intelligentes » de nos smartphones et applications sont le fruit de ces progrès. Bien que l'idée des RNA ne soit pas nouvelle, ce récent boom résulte de la réunion de quelques conditions. Tout d'abord, nous avons découvert le potentiel du calcul GPU. L'architecture des unités de traitement graphique est idéale pour le calcul parallèle, très utile pour un apprentissage en profondeur efficace.
De plus, l'essor des services de cloud computing a rendu l'accès à du matériel à haut rendement beaucoup plus facile, moins cher et possible à une échelle beaucoup plus grande. Enfin, la puissance de calcul des appareils mobiles les plus récents est suffisamment importante pour appliquer des modèles de Deep Learning, créant ainsi un énorme marché d'utilisateurs potentiels de fonctionnalités basées sur DNN.
Applications des modèles de Deep Learning
Les modèles d'apprentissage en profondeur sont généralement appliqués à des problèmes qui traitent de données qui n'ont pas une simple structure de ligne-colonne, comme la classification d'images ou la traduction de langue, car ils sont excellents pour fonctionner sur des données non structurées et à structure complexe que ces tâches gèrent - images, texte , Et le son. Il y a des problèmes avec la gestion de données de ces types et tailles avec des algorithmes d'apprentissage automatique classiques, et la création et l'application de certains réseaux de neurones profonds à ces problèmes ont provoqué d'énormes développements dans les domaines de la reconnaissance d'images, de la reconnaissance vocale, de la classification de texte et de la traduction linguistique dans le monde. dernières années.
L'application de Deep Learning à ces problèmes a été possible du fait que les DNN acceptent des tables de nombres multidimensionnelles, appelées tenseurs, à la fois en entrée et en sortie, et peuvent suivre les relations spatiales et temporelles entre leurs éléments. Par exemple, nous pouvons présenter une image sous la forme d'un tenseur tridimensionnel, où les dimensions un et deux représentent la résolution de l'image numérique (ainsi que les tailles de la largeur et de la hauteur de l'image, respectivement), et la troisième dimension représente la couleur RVB codage de chacun des pixels (donc la troisième dimension est de taille 3).
Cela nous permet non seulement de représenter toutes les informations sur l'image dans un tenseur mais également de conserver les relations spatiales entre les pixels, ce qui s'avère crucial dans l'application des couches dites convolutives, cruciales dans la réussite des réseaux de classification et de reconnaissance d'images.
La flexibilité du réseau neuronal dans les structures d'entrée et de sortie aide également dans d'autres tâches, comme la traduction de la langue . Lorsque nous traitons des données textuelles, nous alimentons les réseaux de neurones profonds avec des représentations numériques des mots, ordonnées en fonction de leur apparition dans le texte. Chaque mot est représenté par un vecteur d'une centaine ou de quelques centaines de nombres, calculé (généralement à l'aide d'un réseau neuronal différent) de sorte que les relations entre les vecteurs correspondant à différents mots imitent les relations des mots eux-mêmes. Ces représentations de langage vectoriel, appelées intégrations, une fois formées, peuvent être réutilisées dans de nombreuses architectures et constituent un élément central des modèles de langage de réseau neuronal.
Exemples d'utilisation de modèles de Deep Learning
Le tableau 3. contient des exemples d'application de modèles d'apprentissage en profondeur à des problèmes réels. Comme vous pouvez le voir, les problèmes abordés et résolus par les algorithmes de Deep Learning sont beaucoup plus complexes que les tâches résolues par les techniques standard de Machine Learning, comme celles présentées dans le tableau 1.
Néanmoins, il est important de se rappeler que de nombreux cas d'utilisation de l'apprentissage automatique peuvent aider les entreprises aujourd'hui ne nécessitent pas de méthodes aussi sophistiquées et peuvent être résolus plus efficacement (et avec une plus grande précision) par des modèles standard. Le tableau 3. donne également une idée du nombre de types différents de couches de réseaux de neurones artificiels et du nombre d'architectures utiles différentes qui peuvent être construites avec elles.
| Cas d'utilisation | Données | Cible/résultat du modèle | Algorithme/modèle utilisé |
| Classement des images | Images | Libellé attribué à une image | Réseau neuronal convolutif (CNN) |
| Détection d'image par les voitures autonomes | Images | Étiquettes et cadres de délimitation autour des objets identifiés sur les images | R-CNN rapide |
| Sentiment analyse de commentaires dans une boutique en ligne | Texte des commentaires en ligne | Libellé de sentiment (par exemple, positif, neutre, négatif) attribué à chaque commentaire | Réseau bidirectionnel de mémoire à long et court terme (LSTM) |
| Harmonisation d'une mélodie | Fichier MIDI avec une mélodie | Fichier MIDI avec cette mélodie harmonisée | Réseau antagoniste génératif |
| Prédiction du mot suivant dans un en ligne éditeur | Très gros morceau de texte (par exemple, vidage de tous les articles de Wikipédia en anglais) | Un mot qui correspond comme le suivant au texte écrit jusqu'à présent | Réseau neuronal récurrent (RNN) avec une couche d'intégration |
| Traduction de texte dans une autre langue | Texte en polonais | Le même texte traduit en anglais | Encodeur - Réseau de décodeurs construit avec des couches de réseau neuronal récurrent (RNN) |
| Transfert du style de Monet à n'importe quelle image | Ensemble d'images des peintures de Monet, et un ensemble d'autres images | Images modifiées pour ressembler à peintes par Monet | Réseau antagoniste génératif |
Tableau 3. Exemples de cas d'utilisation du Deep Learning
Avantages des modèles de Deep Learning
Réseaux antagonistes génératifs
L'une des applications les plus impressionnantes des réseaux de neurones profonds est venue avec la montée en puissance des réseaux antagonistes génératifs (GAN). Ils ont été introduits en 2014 par Ian Goodfellow, et son idée a depuis été intégrée dans de nombreux outils, certains avec des résultats étonnants.
Les GAN sont responsables de l'existence d'applications qui nous font paraître plus vieux sur les photos, transforment les images pour qu'elles aient l'air d'avoir été peintes par van Gogh, ou même harmonisent les mélodies pour plusieurs groupes d'instruments. Lors de l'apprentissage d'un GAN, deux réseaux de neurones s'affrontent. Un réseau générateur génère une sortie à partir d'une entrée aléatoire, tandis que le discriminateur essaie de distinguer les instances générées des instances réelles. Pendant la formation, le générateur apprend à « tromper » avec succès le discriminateur et est finalement capable de créer une sortie qui semble réelle.
Puissants réseaux de neurones profonds dans les applications mobiles
Il est important de noter que même si la formation d'un réseau de neurones profonds est une tâche très coûteuse en calcul et peut prendre beaucoup de temps, l'application d'un réseau formé pour effectuer une tâche spécifique n'a pas à l'être, surtout si elle est appliquée à un ou un quelques cas à la fois. En fait, aujourd'hui, nous sommes capables d'exécuter de puissants réseaux de neurones profonds dans des applications mobiles sur nos smartphones.
Il existe même des architectures de réseau spécialement conçues pour être efficaces lorsqu'elles sont appliquées sur des appareils mobiles (par exemple, NASNetMobile présenté dans l'image 1). Même s'ils sont beaucoup plus petits en taille par rapport aux réseaux de pointe, ils sont toujours capables d'obtenir une performance de prédiction de haute précision.
Apprentissage par transfert
Une autre fonctionnalité très puissante des réseaux de neurones artificiels, permettant une large utilisation des modèles de Deep Learning, est l'apprentissage par transfert . Une fois que nous avons un modèle formé sur certaines données (créées par nous-mêmes ou téléchargées à partir d'un référentiel public), nous pouvons nous appuyer sur tout ou partie de celui-ci pour obtenir un modèle qui résout notre cas d'utilisation particulier. Par exemple, nous pourrions utiliser un modèle NASNetLarge pré-formé, formé sur l'énorme ensemble de données ImageNet, qui attribue une étiquette à une image, apporter quelques petites modifications au sommet de sa structure, l'entraîner davantage avec un nouvel ensemble d'images étiquetées, et utilisez-le pour étiqueter certains types d'objets spécifiques (par exemple, les espèces d'un arbre en fonction de l'image de sa feuille).
Avantages de l'apprentissage par transfert
L'apprentissage par transfert est très utile, car la formation d'un réseau neuronal profond qui effectuera des tâches pratiques et utiles nécessite généralement de grandes quantités de données et une énorme puissance de calcul. Cela peut souvent signifier des millions d'instances de données étiquetées et des centaines d'unités de traitement graphique (GPU) fonctionnant pendant des semaines.
Tout le monde ne peut pas se permettre ou n'a pas accès à de tels actifs, ce qui peut rendre très difficile la création d'une solution personnalisée de haute précision à partir de zéro pour, disons, la classification des images. Heureusement, certains modèles pré-formés (en particulier les réseaux pour la classification des images et les matrices d'intégration pré-formées pour les modèles de langage) ont été open-source et sont disponibles gratuitement sous une forme facilement applicable (par exemple, en tant qu'instance de modèle dans Keras, un API réseaux).
Comment choisir et construire le bon modèle d'apprentissage automatique pour votre application
Lorsque vous souhaitez appliquer l'apprentissage automatique pour résoudre un problème métier, vous n'avez probablement pas besoin de décider immédiatement du type de modèle. Il existe généralement quelques approches qui pourraient être testées. Il est souvent tentant de commencer par les modèles les plus compliqués au départ, mais cela vaut la peine de commencer simple, et d'augmenter progressivement la complexité des modèles appliqués. Les modèles plus simples sont généralement moins chers en termes de configuration, de temps de calcul et de ressources. De plus, leurs résultats sont une excellente référence pour évaluer des approches plus avancées.
Avoir de tels repères peut aider les data scientists à évaluer si la direction dans laquelle ils développent leurs modèles est la bonne. Un autre avantage est la possibilité de réutiliser certains des modèles précédemment construits et de les fusionner avec des modèles plus récents, créant ainsi un modèle dit d'ensemble. Le mélange de modèles de différents types donne souvent des métriques de performance plus élevées que chacun des modèles combinés seuls. Vérifiez également s'il existe des modèles préformés qui pourraient être utilisés et adaptés à votre analyse de rentabilisation via l'apprentissage par transfert.
Plus de conseils pratiques
Tout d'abord, quel que soit le modèle que vous utilisez, assurez-vous que les données sont correctement gérées. Gardez à l'esprit la règle « ordures à l'intérieur, ordures à la sortie ». Si les données d'apprentissage fournies au modèle sont de mauvaise qualité ou n'ont pas été correctement étiquetées et nettoyées, il est très probable que le modèle résultant fonctionnera également mal. Assurez-vous également que le modèle – quelle que soit sa complexité – a été largement validé pendant la phase de modélisation, et au final testé s'il se généralise bien à des données inédites.
Sur une note plus pratique, assurez-vous que la solution créée peut être implémentée en production sur l'infrastructure disponible. Et si votre entreprise peut collecter plus de données qui pourraient être utilisées pour améliorer votre modèle à l'avenir, un pipeline de recyclage doit être préparé pour assurer sa mise à jour facile. Un tel pipeline peut même être configuré pour recycler automatiquement le modèle avec une fréquence de temps prédéfinie.
Dernières pensées
N'oubliez pas de suivre les performances et la convivialité du modèle après son déploiement en production, car l'environnement commercial est très dynamique. Certaines relations au sein de vos données peuvent changer au fil du temps et de nouveaux phénomènes peuvent survenir. Ils peuvent donc modifier l'efficacité de votre modèle et doivent être traités correctement. De plus, de nouveaux types de modèles puissants peuvent être inventés. D'une part, ils peuvent rendre votre solution relativement faible, mais d'autre part, vous donner la possibilité d'améliorer encore votre entreprise et de tirer parti des technologies les plus récentes.
De plus, les modèles Machine et Deep Learning peuvent vous aider à créer des outils puissants pour votre entreprise et vos applications et à offrir à vos clients une expérience exceptionnelle . Bien que la création de ces fonctionnalités « intelligentes » nécessite des efforts considérables, les avantages potentiels en valent la peine. Assurez-vous simplement que vous et votre équipe de science des données essayez les modèles appropriés et suivez les bonnes pratiques, et vous serez sur la bonne voie pour doter votre entreprise et vos applications de solutions d'apprentissage automatique de pointe.
Sources:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf