
Aprendizaje profundo frente a aprendizaje automático: ¿cómo notar la diferencia?
Publicado: 2020-03-10En los últimos años, el aprendizaje automático, el aprendizaje profundo y la inteligencia artificial se han convertido en palabras de moda. Como resultado, puede encontrarlos en todos los materiales de marketing y anuncios de más y más empresas.
Pero, ¿qué son el aprendizaje automático y el aprendizaje profundo? Además, ¿cuáles son las diferencias entre ellos? En este artículo, intentaré responder a estas preguntas y mostrarte algunos casos de aplicaciones de Deep y Machine Learning.
¿Qué es el aprendizaje automático?
El aprendizaje automático es una parte de las ciencias de la computación que se ocupa de representar eventos u objetos del mundo real con modelos matemáticos, basados en datos. Estos modelos se construyen con algoritmos especiales que adaptan la estructura general del modelo para que se ajuste a los datos de entrenamiento. Dependiendo del tipo de problema a resolver, definimos algoritmos de Machine Learning y Machine Learning supervisados y no supervisados.
Aprendizaje automático supervisado frente a no supervisado
El aprendizaje automático supervisado se centra en la creación de modelos que podrían transferir el conocimiento que ya tenemos sobre los datos disponibles a nuevos datos. El algoritmo de creación de modelos (entrenamiento) no ve los nuevos datos durante la fase de entrenamiento. Proporcionamos un algoritmo con los datos de las características junto con los valores correspondientes que el algoritmo debe aprender a inferir de ellos (la llamada variable objetivo).
En el aprendizaje automático no supervisado, solo proporcionamos características al algoritmo. Eso le permite descubrir su estructura y/o dependencias por sí mismo. No se ha especificado una variable objetivo clara. La noción de aprendizaje no supervisado puede ser difícil de comprender al principio, pero echar un vistazo a los ejemplos proporcionados en los cuatro gráficos a continuación debería aclarar esta idea.
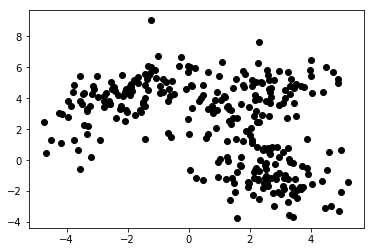
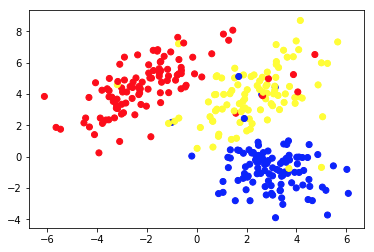
El gráfico 1a presenta algunos datos descritos con 2 características en los ejes x e y . El marcado como 1b muestra los mismos datos coloreados. Usamos el algoritmo de agrupamiento de K- means para agrupar estos puntos en 3 grupos y los coloreamos en consecuencia. Este es un ejemplo de algoritmo de aprendizaje automático no supervisado . Al algoritmo solo se le dieron las características y las etiquetas (números de grupo) debían resolverse.
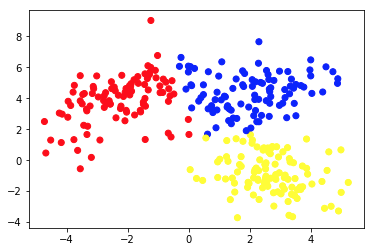
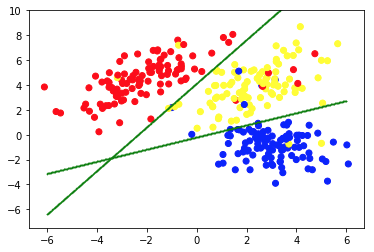
La segunda imagen muestra el Gráfico 2a, que presenta un conjunto diferente de datos etiquetados (y coloreados en consecuencia). Conocemos a priori los grupos a los que pertenecen cada uno de los puntos de datos. Usamos un algoritmo SVM para encontrar 2 líneas rectas que nos mostrarían cómo dividir los puntos de datos para que se ajusten mejor a estos grupos. Esta división no es perfecta, pero es lo mejor que se puede hacer con líneas rectas. Si queremos asignar un grupo a un nuevo punto de datos sin etiquetar, solo debemos verificar dónde se encuentra en el plano. Este es un ejemplo de una aplicación de aprendizaje automático supervisado .
Aplicaciones de los modelos de Machine Learning
Los algoritmos estándar de aprendizaje automático se crean para manejar datos en forma tabular. Esto significa que para usarlos necesitamos algún tipo de tabla. En tal tabla, las filas pueden considerarse instancias del objeto modelado (p. ej., un préstamo). Al mismo tiempo, las columnas deben verse como rasgos (características) de esta instancia en particular (por ejemplo, pago mensual del préstamo, ingreso mensual del prestatario).

¿Tiene curiosidad por el desarrollo de Machine Learning?
Aprende másLa Tabla 1 es un ejemplo muy breve de tales datos. Por supuesto, esto no significa que los datos puros en sí tengan que ser tabulados y estructurados. Pero si queremos aplicar un algoritmo estándar de Machine Learning en algún conjunto de datos, normalmente tenemos que limpiarlo, mezclarlo y transformarlo en una tabla. En el aprendizaje supervisado, también hay una columna especial que contiene el valor objetivo (p. ej., información si el préstamo ha incumplido).
El algoritmo de entrenamiento intenta encajar la estructura general del modelo en estos datos. Dicho algoritmo hace eso ajustando los parámetros del modelo. Eso da como resultado un modelo que describe la relación entre los datos dados y la variable objetivo con la mayor precisión posible.
Es importante que el modelo no solo se ajuste bien a los datos de entrenamiento dados, sino que también pueda generalizar. La generalización significa que podemos usar el modelo para inferir el destino de las instancias que no se usaron durante el entrenamiento. También es una característica crucial de un modelo útil. Construir un modelo bien generalizado no es una tarea fácil. A menudo requiere técnicas de validación sofisticadas y pruebas exhaustivas de modelos.
| préstamo_id | prestatario_edad | ingresos_mensuales | monto del préstamo | mensualidad | defecto |
| 1 | 34 | 10,000 | 100,000 | 1200 | 0 |
| 2 | 43 | 5,700 | 25,000 | 800 | 0 |
| 3 | 25 | 2,500 | 24,000 | 400 | 0 |
| 4 | 67 | 4,600 | 40.000 | 2,000 | 1 |
| 5 | 38 | 35,000 | 2,500,000 | 10,000 | 0 |
Tabla 1. Datos de préstamos en forma tabular
Las personas usan algoritmos de aprendizaje automático en una variedad de aplicaciones. La Tabla 2 presenta algunos casos de uso comercial que permiten el uso de algoritmos y modelos de aprendizaje automático no profundos. También hay descripciones breves de los datos potenciales, las variables objetivo y los algoritmos aplicables seleccionados.
| caso de uso | Ejemplos de datos | Valor objetivo (modelado) | Algoritmo/modelo utilizado |
| Recomendaciones de artículos en un sitio de blog | ID de los artículos leídos por los usuarios, tiempo dedicado a cada uno de ellos | Preferencias de los usuarios hacia los artículos | Filtrado colaborativo con mínimos cuadrados alternos |
| Scoring crediticio de hipotecas | Historial transaccional y crediticio, datos de ingresos de un prestatario potencial | Valor binario que muestra si un préstamo se pagará en su totalidad o si se incumplirá | LuzGBM |
| Predicción de abandono de usuarios premium de un juego móvil | Tiempo dedicado a jugar diariamente, tiempo desde el primer lanzamiento, progreso en el juego | Valor binario que muestra si un usuario cancelará la suscripción el próximo mes | XGBoost |
| Detección de fraude con tarjetas de crédito | Datos históricos de transacciones de tarjetas de crédito: monto, lugar, fecha y hora | Valor binario que muestra si una transacción con tarjeta de crédito es fraudulenta | Bosque aleatorio |
| Segmentación de clientes de una tienda de internet | Historial de compras de los miembros del programa de fidelización | Número de segmento asignado a cada cliente | K-medias |
| Mantenimiento predictivo de un parque de máquinas | Datos de sensores de rendimiento, temperatura, humedad, etc. | Una de las siguientes clases: 'bien', 'observar', 'requiere mantenimiento' | Árbol de decisión |
Tabla 2. Ejemplos de casos de uso de Machine Learning
Aprendizaje profundo y redes neuronales profundas
Deep Learning es parte del Machine Learning en el que utilizamos modelos de un tipo específico, llamado redes neuronales artificiales profundas (ANN). Desde su introducción, las redes neuronales artificiales han pasado por un extenso proceso de evolución. Eso condujo a una serie de subtipos, algunos de los cuales son muy complicados. Pero para presentarlos, es mejor explicar una de sus formas básicas: un perceptrón multicapa (MPL).
perceptrón multicapa
En pocas palabras, un MLP tiene la forma de un gráfico (red) de vértices (también llamados neuronas) y bordes (representados por números llamados pesos). Las neuronas están dispuestas en capas y las neuronas en capas consecutivas están conectadas entre sí. Los datos fluyen a través de la red desde la capa de entrada a la de salida. Luego, los datos se transforman en las neuronas y los bordes entre ellas. Una vez que un punto de datos pasa por toda la red, la capa de salida contiene los valores predichos en sus neuronas.
Cada vez que una parte de los datos de entrenamiento pasa a través de la red, comparamos las predicciones con los valores reales correspondientes. Eso nos permite adaptar los parámetros (pesos) del modelo para hacer mejores predicciones. Podemos hacerlo con un algoritmo llamado backpropagation. Después de algunas iteraciones, si la estructura del modelo está bien diseñada específicamente para abordar el problema de Machine Learning en cuestión.
Obtención de un modelo de alta precisión
Una vez que suficientes datos han pasado a través de la red varias veces, obtenemos un modelo de alta precisión. En la práctica, hay muchas transformaciones que se pueden aplicar en las neuronas. Eso hace que las ANN sean muy flexibles y poderosas. Sin embargo, el poder de las ANN tiene un precio. Por lo general, cuanto más complicada es la estructura del modelo, más datos y tiempo se requieren para entrenarlo con alta precisión.
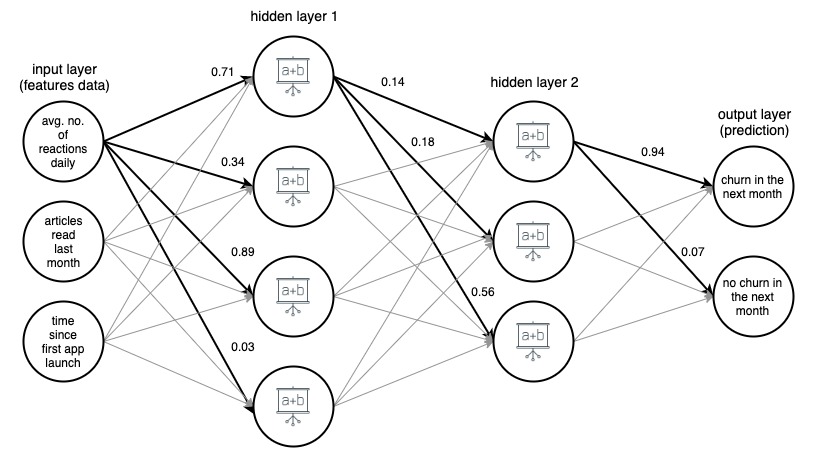
Imagen 1. (draw.io) Estructura de una red neuronal artificial de 4 capas, que predice si un usuario de una aplicación de noticias abandonará el próximo mes, según tres características simples.
Para mayor claridad, los pesos se han marcado solo para los bordes seleccionados (en negrita), pero cada borde tiene su propio peso. Los datos fluyen desde la capa de entrada a la capa de salida, pasando por 2 capas ocultas en el medio. En cada borde, un valor de entrada se multiplica por el peso del borde y el producto resultante va al nodo en el que termina el borde. Luego, en cada uno de los nodos de las capas ocultas, las señales entrantes de los bordes se resumen y luego se transforman con alguna función. Luego, el resultado de estas transformaciones se trata como una entrada para la siguiente capa.
En la capa de salida, los datos entrantes se resumen y transforman nuevamente, dando el resultado en forma de dos números: la probabilidad de que un usuario abandone la aplicación en el próximo mes y la probabilidad de que no lo haga.
Tipos avanzados de redes neuronales
En redes neuronales de tipos más avanzados, las capas tienen una estructura mucho más compleja. Consisten no solo en capas densas simples con neuronas de una operación conocidas de MLP, sino también en capas mucho más complicadas y de múltiples operaciones, como capas convolucionales y recurrentes.
Capas convolucionales y recurrentes
Las capas convolucionales se utilizan principalmente en aplicaciones de visión artificial . Consisten en pequeños conjuntos de números que se deslizan sobre la representación de píxeles de la imagen. Los valores de los píxeles se multiplican por estos números y luego se agregan, lo que produce una representación nueva y condensada de la imagen.
Las capas recurrentes se utilizan para modelar datos secuenciales ordenados, como series temporales o texto . Aplican transformaciones de argumentos múltiples mucho más complicadas a los datos entrantes, tratando de descubrir las dependencias entre los elementos de la secuencia. Sin embargo, sin importar el tipo y la estructura de la red, siempre hay algunas (una o más) capas de entrada y salida, y rutas y direcciones estrictamente definidas en las que los datos fluyen a través de la red.
En general, las Redes Neuronales Profundas son ANN con múltiples capas. Las imágenes 1, 2 y 3 a continuación muestran arquitecturas de redes neuronales artificiales profundas seleccionadas. Todos fueron desarrollados y entrenados en Google, y puestos a disposición del público. Dan una idea de cuán complejas son las redes artificiales profundas de alta precisión que se usan hoy en día.
Estas redes tienen tamaños enormes. Por ejemplo, parcialmente mostrado en la Imagen 3, InceptionResNetV2 tiene 572 capas y más de 55 millones de parámetros en total. Todos se han desarrollado como modelos de clasificación de imágenes (asignan una etiqueta, por ejemplo, 'coche' a una imagen determinada) y se han entrenado con imágenes del conjunto ImageNet, que consta de más de 14 millones de imágenes etiquetadas.
Imagen 2. Estructura de NASNetMobile (paquete keras)


Imagen 3. Estructura de XCeption (paquete keras)

Imagen 4. Estructura de una parte (alrededor del 25%) de InceptionResNetV2 (paquete keras)
En los últimos años hemos observado un gran desarrollo en Deep Learning y sus aplicaciones. Muchas de las características 'inteligentes' de nuestros teléfonos inteligentes y aplicaciones son fruto de este progreso. Aunque la idea de las ANN no es nueva, este auge reciente es el resultado de cumplir algunas condiciones. En primer lugar, hemos descubierto el potencial de la computación GPU. La arquitectura de las unidades de procesamiento gráfico es excelente para el cómputo paralelo, muy útil para un aprendizaje profundo eficiente.
Además, el auge de los servicios de computación en la nube ha hecho que el acceso a hardware de alta eficiencia sea mucho más fácil, económico y posible a una escala mucho mayor. Finalmente, el poder computacional de los dispositivos móviles más nuevos es lo suficientemente grande como para aplicar modelos de aprendizaje profundo, lo que crea un enorme mercado de usuarios potenciales de funciones impulsadas por DNN.
Aplicaciones de los modelos de Deep Learning
Los modelos de aprendizaje profundo generalmente se aplican a problemas que tratan con datos que no tienen una estructura simple de filas y columnas, como la clasificación de imágenes o la traducción de idiomas, ya que son excelentes para operar en datos no estructurados y de estructura compleja que manejan estas tareas: imágenes, texto , y sonido. Hay problemas con el manejo de datos de estos tipos y tamaños con los algoritmos clásicos de aprendizaje automático, y la creación y aplicación de algunas redes neuronales profundas a estos problemas ha causado un gran desarrollo en los campos de reconocimiento de imágenes, reconocimiento de voz, clasificación de texto y traducción de idiomas en el los últimos años.
La aplicación de Deep Learning a estos problemas fue posible debido al hecho de que las DNN aceptan tablas de números multidimensionales, llamadas tensores, como entrada y salida, y pueden rastrear las relaciones espaciales y temporales entre sus elementos. Por ejemplo, podemos presentar una imagen como un tensor tridimensional, donde la dimensión uno y dos representan la resolución de la imagen digital (así como los tamaños de ancho y alto de la imagen, respectivamente), y la tercera dimensión representa el color RGB. codificación de cada uno de los píxeles (por lo que la tercera dimensión es de tamaño 3).
Esto nos permite no solo representar toda la información sobre la imagen en un tensor, sino también mantener las relaciones espaciales entre los píxeles, lo que resulta crucial en la aplicación de las llamadas capas convolucionales, cruciales en el éxito de las redes de clasificación y reconocimiento de imágenes.
La flexibilidad de la red neuronal en las estructuras de entrada y salida ayuda también en otras tareas, como la traducción de idiomas . Cuando tratamos con datos de texto, alimentamos las redes neuronales profundas con representaciones numéricas de las palabras, ordenadas según su aparición en el texto. Cada palabra está representada por un vector de cien o unos pocos cientos de números, calculados (generalmente usando una red neuronal diferente) de modo que las relaciones entre los vectores correspondientes a diferentes palabras imiten las relaciones de las propias palabras. Estas representaciones de lenguaje vectorial, llamadas incrustaciones, una vez entrenadas, se pueden reutilizar en muchas arquitecturas y son un componente central de los modelos de lenguaje de redes neuronales.
Ejemplos de uso de modelos de Deep Learning
La Tabla 3 contiene ejemplos de la aplicación de modelos de aprendizaje profundo a problemas de la vida real. Como puede ver, los problemas que abordan y resuelven los algoritmos de Deep Learning son mucho más complejos que las tareas que resuelven las técnicas estándar de Machine Learning, como las que se presentan en la Tabla 1.
Sin embargo, es importante recordar que muchos de los casos de uso que Machine Learning puede ayudar a las empresas hoy en día no requieren métodos tan sofisticados y pueden resolverse de manera más eficiente (y con mayor precisión) mediante modelos estándar. La Tabla 3 también da una idea de cuántos tipos diferentes de capas de redes neuronales artificiales hay y cuántas arquitecturas útiles diferentes se pueden construir con ellas.
| caso de uso | Datos | Objetivo/resultado del modelo | Algoritmo/modelo utilizado |
| Clasificación de imágenes | Imágenes | Etiqueta asignada a una imagen | Red neuronal convolucional (CNN) |
| Detección de imágenes por vehículos autónomos | Imágenes | Etiquetas y cuadros delimitadores alrededor de objetos identificados en imágenes | R-CNN rápido |
| Sentimiento análisis de comentarios en una tienda online | Texto de comentarios en línea | Etiqueta de opinión (p. ej., positivo, neutral, negativo) asignada a cada comentario | Red bidireccional de memoria a largo y corto plazo (LSTM) |
| Armonización de una melodía. | Archivo MIDI con una melodía | Archivo MIDI con esta melodía armonizada | Red adversaria generativa |
| Predicción de la siguiente palabra en un en línea editor | Fragmento de texto muy grande (p. ej., volcado de todos los artículos de Wikipedia en inglés) | Una palabra que encaje como la siguiente en el texto escrito hasta ahora | Red neuronal recurrente (RNN) con una capa de incrustación |
| Traducción de texto a otro idioma | Texto en polaco | El mismo texto traducido al inglés. | Codificador – Decodificador Red construida con capas de red neuronal recurrente (RNN) |
| Transferencia del estilo de Monet a cualquier imagen | Conjunto de imágenes de las pinturas de Monet y un conjunto de otras imágenes. | Imágenes modificadas para que parezcan pintadas por Monet | Red adversaria generativa |
Tabla 3. Ejemplos de casos de uso de Deep Learning
Ventajas de los modelos de Deep Learning
Redes adversarias generativas
Una de las aplicaciones más impresionantes de las redes neuronales profundas se produjo con el surgimiento de las redes adversarias generativas (GAN). Fueron presentados en 2014 por Ian Goodfellow, y desde entonces su idea se ha incorporado en muchas herramientas, algunas con resultados sorprendentes.
Las GAN son las responsables de la existencia de aplicaciones que nos hacen parecer mayores en las fotos, transforman imágenes para que parezcan pintadas por van Gogh o incluso armonizan melodías para múltiples bandas de instrumentos. Durante el entrenamiento de una GAN, dos redes neuronales compiten. Una red generadora genera una salida a partir de una entrada aleatoria, mientras que el discriminador trata de diferenciar las instancias generadas de las reales. Durante el entrenamiento, el generador aprende cómo "engañar" con éxito al discriminador y, finalmente, puede crear una salida que parece real.
Potentes redes neuronales profundas en aplicaciones móviles
Es importante tener en cuenta que aunque entrenar una red neuronal profunda es una tarea muy costosa desde el punto de vista computacional y puede llevar mucho tiempo, aplicar una red entrenada para realizar una tarea específica no tiene por qué serlo, especialmente si se aplica a uno o varios. pocos casos a la vez. De hecho, hoy podemos ejecutar poderosas redes neuronales profundas en aplicaciones móviles en nuestros teléfonos inteligentes.
Incluso hay algunas arquitecturas de red diseñadas específicamente para ser eficientes cuando se aplican en dispositivos móviles (p. ej., NASNetMobile presentado en la Imagen 1). A pesar de que son mucho más pequeños en tamaño en comparación con las redes más modernas, aún pueden obtener un rendimiento de predicción de alta precisión.
Transferencia de aprendizaje
Otra característica muy poderosa de las redes neuronales artificiales, que permite un amplio uso de los modelos de aprendizaje profundo, es el aprendizaje por transferencia . Una vez que tenemos un modelo entrenado en algunos datos (ya sea creado por nosotros mismos o descargado de un repositorio público), podemos construir sobre todo o parte de él para obtener un modelo que resuelva nuestro caso de uso particular. Por ejemplo, podríamos usar un modelo NASNetLarge previamente entrenado, entrenado en el enorme conjunto de datos de ImageNet, que asigna una etiqueta a una imagen, realiza algunas modificaciones pequeñas en la parte superior de su estructura, lo entrena aún más con un nuevo conjunto de imágenes etiquetadas y utilícelo para etiquetar algún tipo específico de objetos (por ejemplo, especies de un árbol en función de la imagen de su hoja).
Ventajas del aprendizaje por transferencia
El aprendizaje por transferencia es muy útil, ya que, por lo general, entrenar una red neuronal profunda que realizará algunas tareas prácticas y útiles requiere grandes cantidades de datos y una gran potencia computacional. Esto a menudo puede significar millones de instancias de datos etiquetados y cientos de unidades de procesamiento de gráficos (GPU) funcionando durante semanas.
No todos pueden pagar o tienen acceso a dichos activos, lo que puede dificultar mucho la creación de una solución personalizada de alta precisión desde cero para, digamos, la clasificación de imágenes. Afortunadamente, algunos modelos preentrenados (especialmente redes para clasificación de imágenes y matrices de incrustación preentrenadas para modelos de lenguaje) han sido de código abierto y están disponibles de forma gratuita en una forma fácilmente aplicable (por ejemplo, como una instancia de modelo en Keras, un sistema neuronal API de redes).
Cómo elegir y construir el modelo de Machine Learning adecuado para su aplicación
Cuando desee aplicar Machine Learning para resolver un problema comercial, probablemente no necesite decidir el tipo de modelo de inmediato. Por lo general, hay algunos enfoques que podrían probarse. A menudo es tentador comenzar con los modelos más complicados al principio, pero vale la pena comenzar de manera simple y aumentar gradualmente la complejidad de los modelos aplicados. Los modelos más simples suelen ser más baratos en términos de configuración, tiempo de cálculo y recursos. Además, sus resultados son un gran punto de referencia para evaluar enfoques más avanzados.
Tener tales puntos de referencia puede ayudar a los científicos de datos a evaluar si la dirección en la que desarrollan sus modelos es la correcta. Otra ventaja es la posibilidad de reutilizar algunos de los modelos creados anteriormente y fusionarlos con otros más nuevos, creando el llamado modelo de conjunto. La combinación de modelos de diferentes tipos a menudo produce métricas de rendimiento más altas que las que tendría cada uno de los modelos combinados por sí solo. Además, verifique si hay algunos modelos pre-entrenados que podrían usarse y adaptarse a su caso de negocios a través del aprendizaje por transferencia.
Más consejos prácticos
En primer lugar, independientemente del modelo que utilice, asegúrese de que los datos se manejen correctamente. Tenga en cuenta la regla de "basura que entra, basura que sale". Si los datos de entrenamiento proporcionados al modelo son de baja calidad o no se han etiquetado y limpiado correctamente, es muy probable que el modelo resultante también tenga un rendimiento deficiente. Asegúrese también de que el modelo, sea cual sea su complejidad, haya sido ampliamente validado durante la fase de modelado y, al final, probado si se generaliza bien a datos no vistos.
En una nota más práctica, asegúrese de que la solución creada se pueda implementar en producción en la infraestructura disponible. Y si su empresa puede recopilar más datos que podrían usarse para mejorar su modelo en el futuro, se debe preparar una canalización de capacitación para garantizar su fácil actualización. Tal tubería puede incluso configurarse para volver a entrenar automáticamente el modelo con una frecuencia de tiempo predefinida.
Pensamientos finales
No olvide realizar un seguimiento del rendimiento y la usabilidad del modelo después de su implementación en producción, ya que el entorno empresarial es muy dinámico. Algunas relaciones dentro de sus datos pueden cambiar con el tiempo y pueden surgir nuevos fenómenos. Por lo tanto, pueden cambiar la eficiencia de su modelo y deben tratarse adecuadamente. Además, se pueden inventar tipos de modelos nuevos y potentes. Por un lado, pueden hacer que su solución sea relativamente débil, pero por otro lado, le brindan la oportunidad de mejorar aún más su negocio y aprovechar la tecnología más nueva.
Además, los modelos de Machine y Deep Learning pueden ayudarlo a crear herramientas poderosas para su negocio y aplicaciones y brindarles a sus clientes una experiencia excepcional . Aunque la creación de estas características 'inteligentes' requiere un esfuerzo considerable, los beneficios potenciales valen la pena. Solo asegúrese de que usted y su equipo de ciencia de datos prueben los modelos apropiados y sigan las buenas prácticas, y estarán en el camino correcto para potenciar su negocio y sus aplicaciones con soluciones de aprendizaje automático de vanguardia.
Fuentes:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/aprendizaje profundo
- https://keras.io/aplicaciones/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidireccional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/aplicaciones/
- https://arxiv.org/pdf/1707.07012.pdf