
Deep Learning vs. Machine Learning – como saber a diferença?
Publicados: 2020-03-10Nos últimos anos, Machine Learning, Deep Learning e Inteligência Artificial tornaram-se palavras da moda. Como resultado, você pode encontrá-los em materiais de marketing e anúncios de mais e mais empresas.
Mas o que são Machine Learning e Deep Learning? Além disso, quais são as diferenças entre eles? Neste artigo, tentarei responder a essas perguntas e mostrar alguns casos de aplicações de Deep e Machine Learning.
O que é Aprendizado de Máquina?
Machine Learning é uma parte da Ciência da Computação que lida com a representação de eventos ou objetos do mundo real com modelos matemáticos, baseados em dados. Esses modelos são construídos com algoritmos especiais que adaptam a estrutura geral do modelo para que ele se ajuste aos dados de treinamento. Dependendo do tipo de problema a ser resolvido, definimos algoritmos de Machine Learning e Machine Learning supervisionados e não supervisionados.
Aprendizado de máquina supervisionado versus não supervisionado
O Aprendizado de Máquina Supervisionado se concentra na criação de modelos capazes de transferir o conhecimento que já temos sobre os dados disponíveis para novos dados. Os novos dados não são vistos pelo algoritmo de construção de modelo (treinamento) durante a fase de treinamento. Fornecemos um algoritmo com os dados dos recursos juntamente com os valores correspondentes que o algoritmo deve aprender a inferir deles (a chamada variável de destino).
No aprendizado de máquina não supervisionado, fornecemos apenas recursos ao algoritmo. Isso permite que ele descubra sua estrutura e/ou dependências por conta própria. Não há uma variável de destino clara especificada. A noção de aprendizagem não supervisionada pode ser difícil de entender no início, mas dar uma olhada nos exemplos fornecidos nos quatro gráficos abaixo deve deixar essa ideia clara.
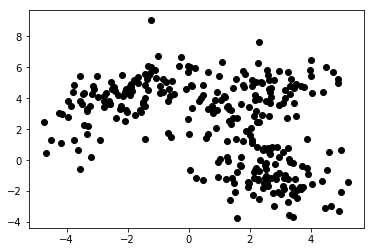
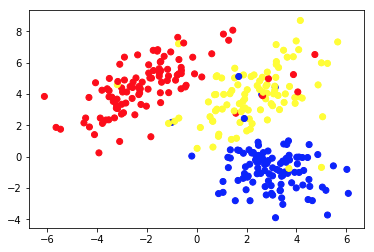
O gráfico 1a apresenta alguns dados descritos com 2 feições nos eixos xey . O marcado como 1b mostra os mesmos dados coloridos. Usamos o algoritmo de agrupamento K- means para agrupar esses pontos em 3 agrupamentos e colori-los de acordo. Este é um exemplo de algoritmo de aprendizado de máquina não supervisionado . O algoritmo recebeu apenas os recursos e os rótulos (números de cluster) deveriam ser descobertos.
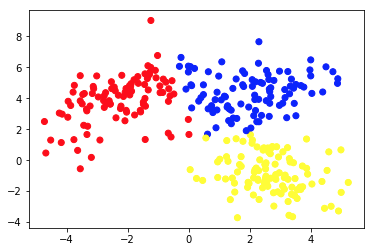
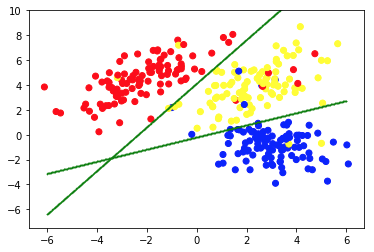
A segunda imagem mostra o Gráfico 2a, que apresenta um conjunto diferente de dados rotulados (e coloridos de acordo). Sabemos a priori a quais grupos cada um dos pontos de dados pertence. Usamos um algoritmo SVM para encontrar 2 linhas retas que nos mostrariam como dividir os pontos de dados para ajustar melhor esses grupos. Essa divisão não é perfeita, mas é o melhor que pode ser feito com linhas retas. Se quisermos atribuir um grupo a um novo ponto de dados não rotulado, precisamos apenas verificar onde ele se encontra no plano. Este é um exemplo de um aplicativo de aprendizado de máquina supervisionado .
Aplicações de modelos de aprendizado de máquina
Os algoritmos de Machine Learning padrão são criados para manipular dados em um formato tabular. Isso significa que, para usá-los, precisamos de algum tipo de tabela. Nessas tabelas, as linhas podem ser consideradas como instâncias do objeto modelado (por exemplo, um empréstimo). Ao mesmo tempo, as colunas devem ser vistas como características (características) dessa instância específica (por exemplo, pagamento mensal do empréstimo, renda mensal do mutuário).

Curioso sobre o desenvolvimento de Machine Learning?
Saber maisA Tabela 1 é um exemplo muito curto desses dados. Claro, isso não significa que os dados puros em si tenham que ser tabulares e estruturados. Mas se quisermos aplicar um algoritmo padrão de Machine Learning em algum conjunto de dados, geralmente temos que limpá-lo, misturá-lo e transformá-lo em uma tabela. No aprendizado supervisionado, há também uma coluna especial que contém o valor alvo (por exemplo, informações se o empréstimo está inadimplente).
O algoritmo de treinamento tenta encaixar a estrutura geral do modelo nesses dados. O referido algoritmo faz isso ajustando os parâmetros do modelo. Isso resulta em um modelo que descreve a relação entre os dados fornecidos e a variável de destino com a maior precisão possível.
É importante que o modelo não apenas se ajuste bem aos dados de treinamento fornecidos, mas também seja capaz de generalizar. Generalização significa que podemos usar o modelo para inferir o destino para instâncias não usadas durante o treinamento. É também uma característica crucial de um modelo útil. Construir um modelo bem generalizador não é uma tarefa fácil. Muitas vezes requer técnicas de validação sofisticadas e testes de modelo completos.
| id_empréstimo | mutuário_idade | renda_mensal | montante do empréstimo | pagamento mensal | predefinição |
| 1 | 34 | 10.000 | 100.000 | 1.200 | 0 |
| 2 | 43 | 5.700 | 25.000 | 800 | 0 |
| 3 | 25 | 2.500 | 24.000 | 400 | 0 |
| 4 | 67 | 4.600 | 40.000 | 2.000 | 1 |
| 5 | 38 | 35.000 | 2.500.000 | 10.000 | 0 |
Tabela 1. Dados de empréstimo em forma de tabela
As pessoas usam algoritmos de aprendizado de máquina em uma variedade de aplicativos. A Tabela 2. apresenta alguns casos de uso de negócios que permitem algoritmos e modelos de Machine Learning não profundos. Há também descrições curtas dos dados potenciais, variáveis de destino e algoritmos aplicáveis selecionados.
| Caso de uso | Exemplos de dados | Valor alvo (modelado) | Algoritmo/modelo usado |
| Recomendações de artigos em um site de blog | IDs de artigos lidos pelos usuários, tempo gasto em cada um deles | Preferências dos usuários em relação aos artigos | Filtragem Colaborativa com Mínimos Quadrados Alternados |
| Pontuação de crédito de hipotecas | Histórico transacional e de crédito, dados de renda de um mutuário em potencial | Valor binário mostrando se um empréstimo será reembolsado integralmente ou será inadimplente | Light GBM |
| Previsão de rotatividade de usuários premium de um jogo para celular | Tempo gasto jogando diariamente, tempo desde o primeiro lançamento, progresso no jogo | Valor binário mostrando se um usuário cancelará a assinatura no próximo mês | XGBoostName |
| Detecção de fraude de cartão de crédito | Dados históricos de transações de cartão de crédito – valor, local, data e hora | Valor binário mostrando se uma transação com cartão de crédito é fraudulenta | Floresta aleatória |
| Segmentação de clientes de uma loja na internet | Histórico de compras de membros do programa de fidelidade | Número do segmento atribuído a cada cliente | K-médias |
| Manutenção preditiva de um parque de máquinas | Dados de sensores de desempenho, temperatura, umidade, etc. | Uma das seguintes classes – 'bem', 'observar', 'requer manutenção' | Árvore de decisão |
Tabela 2. Exemplos de casos de uso de Machine Learning
Deep Learning e Redes Neurais Profundas
O Deep Learning faz parte do Machine Learning no qual usamos modelos de um tipo específico, chamados de redes neurais artificiais profundas (RNAs). Desde a sua introdução, as redes neurais artificiais passaram por um extenso processo de evolução. Isso levou a vários subtipos, alguns dos quais são muito complicados. Mas, para apresentá-los, é melhor explicar uma de suas formas básicas – um perceptron multicamada (MPL).
Perceptron multicamada
Simplificando, um MLP tem uma forma de grafo (rede) de vértices (também chamados de neurônios) e arestas (representadas por números chamados pesos). Os neurônios são organizados em camadas e os neurônios em camadas consecutivas são conectados uns aos outros. Os dados fluem através da rede da camada de entrada para a camada de saída. Os dados são então transformados nos neurônios e nas bordas entre eles. Uma vez que um ponto de dados passa por toda a rede, a camada de saída contém os valores previstos em seus neurônios.
Toda vez que um pedaço dos dados de treinamento passa pela rede, comparamos as previsões com os valores verdadeiros correspondentes. Isso nos permite adaptar os parâmetros (pesos) do modelo para fazer previsões melhores. Podemos fazer isso com um algoritmo chamado backpropagation. Após algumas iterações, se a estrutura do modelo for bem projetada especificamente para resolver o problema de Machine Learning em questão.
Obtenção de um modelo de alta precisão
Uma vez que dados suficientes tenham passado pela rede várias vezes, obtemos um modelo de alta precisão. Na prática, existem muitas transformações que podem ser aplicadas nos neurônios. Isso torna as RNAs muito flexíveis e poderosas. O poder das RNAs tem um preço, no entanto. Normalmente, quanto mais complicada a estrutura do modelo, mais dados e tempo são necessários para treiná-lo com alta precisão.
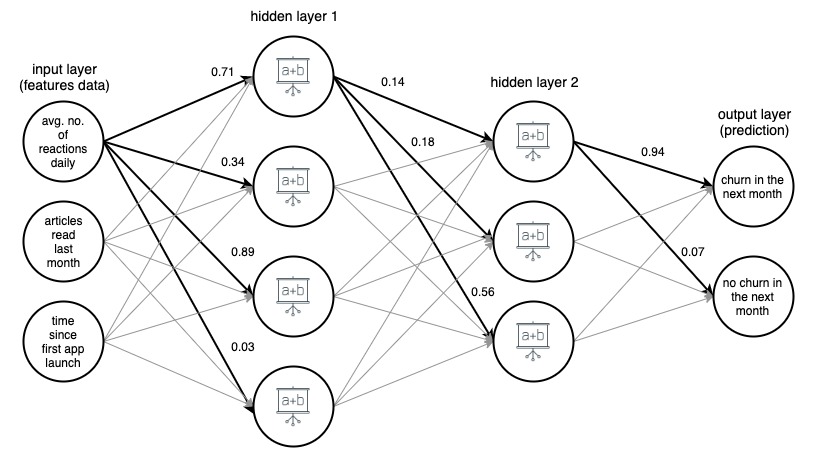
Imagem 1. (draw.io) Estrutura de uma rede neural artificial de 4 camadas, prevendo se um usuário de um aplicativo de notícias vai chutar no próximo mês, com base em três recursos simples.
Para maior clareza, os pesos foram marcados apenas para arestas selecionadas (em negrito), mas cada aresta tem seu próprio peso. Os dados fluem da camada de entrada para a camada de saída, passando por 2 camadas ocultas no meio. Em cada aresta, um valor de entrada é multiplicado pelo peso da aresta e o produto resultante vai para o nó em que a aresta termina. Então, em cada um dos nós das camadas ocultas, os sinais de entrada das arestas são somados e então transformados com alguma função. O resultado dessas transformações é então tratado como uma entrada para a próxima camada.
Na camada de saída, os dados recebidos são novamente somados e transformados, produzindo o resultado na forma de dois números – a probabilidade de um usuário sair do aplicativo no próximo mês e a probabilidade de que não.
Tipos avançados de redes neurais
Em redes neurais de tipos mais avançados, as camadas possuem uma estrutura muito mais complexa. Eles consistem não apenas em camadas densas simples com neurônios de uma operação conhecidos de MLPs, mas também em camadas muito mais complicadas de várias operações, como camadas convolucionais e recorrentes.
Camadas convolucionais e recorrentes
As camadas convolucionais são usadas principalmente em aplicativos de visão computacional . Eles consistem em pequenas matrizes de números que deslizam sobre a representação em pixels da imagem. Os valores de pixel são multiplicados por esses números e então agregados, produzindo uma nova representação condensada da imagem.
Camadas recorrentes são usadas para modelar dados sequenciais ordenados como séries temporais ou texto . Eles aplicam transformações multi-argumentos muito complicadas aos dados recebidos, tentando descobrir as dependências entre os itens da sequência. No entanto, não importa o tipo e a estrutura da rede, sempre há algumas (uma ou mais) camadas de entrada e saída, e caminhos e direções estritamente definidos nos quais os dados fluem pela rede.
Em geral, Deep Neural Networks são RNAs com múltiplas camadas. As imagens 1, 2 e 3 abaixo mostram arquiteturas de redes neurais artificiais profundas selecionadas. Todos eles foram desenvolvidos e treinados no Google e disponibilizados ao público. Eles dão uma ideia de quão complexas são as redes artificiais profundas de alta precisão usadas hoje.
Essas redes têm tamanhos enormes. Por exemplo, mostrado parcialmente na Imagem 3 InceptionResNetV2 tem 572 camadas e mais de 55 milhões de parâmetros no total! Todos eles foram desenvolvidos como modelos de classificação de imagens (eles atribuem um rótulo, por exemplo, 'carro' a uma determinada imagem), e foram treinados em imagens do conjunto ImageNet, que consiste em mais de 14 milhões de imagens rotuladas.

Imagem 2. Estrutura do NASNetMobile (pacote keras)

Imagem 3. Estrutura do XCeption (pacote keras)

Imagem 4. Estrutura de uma parte (cerca de 25%) do InceptionResNetV2 (pacote keras)
Nos últimos anos temos observado grande desenvolvimento em Deep Learning e suas aplicações. Muitos dos recursos 'inteligentes' de nossos smartphones e aplicativos são fruto desse progresso. Embora a ideia de RNAs não seja nova, esse boom recente é resultado do cumprimento de algumas condições. Em primeiro lugar, descobrimos o potencial da computação GPU. A arquitetura das unidades de processamento gráfico é ótima para computação paralela, muito útil em Deep Learning eficiente.
Além disso, o aumento dos serviços de computação em nuvem tornou o acesso a hardware de alta eficiência muito mais fácil, barato e possível em uma escala muito maior. Por fim, o poder computacional dos mais novos dispositivos móveis é grande o suficiente para aplicar modelos de Deep Learning, criando um enorme mercado de usuários potenciais de recursos orientados por DNN.
Aplicações de modelos de Deep Learning
Os modelos de Deep Learning são geralmente aplicados a problemas que lidam com dados que não possuem uma estrutura simples de linha-coluna, como classificação de imagem ou tradução de idioma, pois são ótimos para operar em dados não estruturados e de estrutura complexa que essas tarefas manipulam - imagens, texto , e som. Existem problemas com o manuseio de dados desses tipos e tamanhos com algoritmos clássicos de aprendizado de máquina, e a criação e aplicação de algumas redes neurais profundas para esses problemas causaram grandes desenvolvimentos nas áreas de reconhecimento de imagem, reconhecimento de fala, classificação de texto e tradução de idiomas no últimos anos.
A aplicação do Deep Learning a esses problemas foi possível devido ao fato de que as DNNs aceitam tabelas multidimensionais de números, chamadas tensores, como entrada e saída, e podem rastrear as relações espaciais e temporais entre seus elementos. Por exemplo, podemos apresentar uma imagem como um tensor tridimensional, onde as dimensões um e dois representam a resolução da imagem digital (assim como os tamanhos da largura e altura da imagem, respectivamente), e a terceira dimensão representa a cor RGB codificação de cada um dos pixels (portanto, a terceira dimensão é de tamanho 3).
Isso nos permite não apenas representar todas as informações sobre a imagem em um tensor, mas também manter as relações espaciais entre os pixels, o que acaba sendo crucial na aplicação das chamadas camadas convolucionais, cruciais para o sucesso da classificação de imagens e redes de reconhecimento.
A flexibilidade da rede neural nas estruturas de entrada e saída ajuda também em outras tarefas, como tradução de idiomas . Ao lidar com dados de texto, alimentamos as redes neurais profundas com representações numéricas das palavras, ordenadas de acordo com sua aparência no texto. Cada palavra é representada por um vetor de cem ou algumas centenas de números, computados (geralmente usando uma rede neural diferente) para que as relações entre os vetores correspondentes a diferentes palavras imitem as relações das próprias palavras. Essas representações de linguagem vetorial, chamadas de embeddings, uma vez treinadas, podem ser reutilizadas em muitas arquiteturas e são um bloco de construção central dos modelos de linguagem de rede neural.
Exemplos de uso de modelos de Deep Learning
A Tabela 3 contém exemplos de aplicação de modelos de Deep Learning a problemas da vida real. Como você pode ver, problemas enfrentados e resolvidos por algoritmos de Deep Learning são muito mais complexos do que tarefas resolvidas por técnicas padrão de Machine Learning, como as apresentadas na Tabela 1.
No entanto, é importante lembrar que muitos dos casos de uso que o Machine Learning pode ajudar nos negócios hoje não exigem métodos tão sofisticados e podem ser resolvidos de forma mais eficiente (e com maior precisão) por modelos padrão. A Tabela 3 também dá uma ideia de quantos tipos diferentes de camadas de redes neurais artificiais existem e quantas arquiteturas úteis diferentes podem ser construídas com elas.
| Caso de uso | Dados | Alvo/resultado do modelo | Algoritmo/modelo usado |
| Classificação de imagem | Imagens | Rótulo atribuído a uma imagem | Rede Neural Convolucional (CNN) |
| Detecção de imagem por carros autônomos | Imagens | Rótulos e caixas delimitadoras em torno de objetos identificados nas imagens | R-CNN rápido |
| Sentimento Análise de comentários em uma loja online | Texto de comentários online | Rótulo de sentimento (por exemplo, positivo, neutro, negativo) atribuído a cada comentário | Rede bidirecional de memória de longo prazo (LSTM) |
| Harmonização de uma melodia | Arquivo MIDI com uma melodia | Arquivo MIDI com esta melodia harmonizada | Rede Adversária Geradora |
| Previsão da próxima palavra em um conectados o email editor | Muito grande pedaço de texto (por exemplo, despejo de todos os artigos da Wikipédia em inglês) | Uma palavra que se encaixe como a próxima do texto escrito até agora | Rede Neural Recorrente (RNN) com uma camada de incorporação |
| Tradução de texto para outro idioma | Texto em polonês | O mesmo texto traduzido para o inglês | Encoder – Rede de decodificador construída com camadas de rede neural recorrente (RNN) |
| Transferência do estilo de Monet para qualquer imagem | Conjunto de imagens das pinturas de Monet e um conjunto de outras imagens | Imagens modificadas para parecerem pintadas por Monet | Rede Adversária Geradora |
Tabela 3. Exemplos de casos de uso de Deep Learning
Vantagens dos modelos de Deep Learning
Redes Adversárias Geradoras
Uma das aplicações mais impressionantes das Deep Neural Networks veio com o surgimento das Generative Adversarial Networks (GANs). Eles foram introduzidos em 2014 por Ian Goodfellow, e sua ideia foi incorporada em muitas ferramentas, algumas com resultados surpreendentes.
As GANs são responsáveis pela existência de aplicativos que nos fazem parecer mais velhos nas fotos, transformam imagens para que pareçam pintadas por van Gogh, ou ainda harmonizam melodias para várias bandas de instrumentos. Durante o treinamento de uma GAN, duas redes neurais competem. Uma rede geradora gera uma saída a partir de uma entrada aleatória, enquanto o discriminador tenta diferenciar as instâncias geradas das reais. Durante o treinamento, o gerador aprende como 'enganar' com sucesso o discriminador e, eventualmente, é capaz de criar uma saída que parece ser real.
Redes neurais profundas poderosas em aplicativos móveis
É importante notar que, embora o treinamento de uma rede neural profunda seja uma tarefa muito cara computacionalmente e possa levar muito tempo, aplicar uma rede treinada para realizar uma tarefa específica não precisa ser, especialmente se for aplicada a um ou a um poucos casos de uma só vez. Na verdade, hoje somos capazes de executar poderosas redes neurais profundas em aplicativos móveis em nossos smartphones.
Existem até algumas arquiteturas de rede projetadas especificamente para serem eficientes quando aplicadas em dispositivos móveis (por exemplo, NASNetMobile apresentado na Imagem 1). Embora sejam muito menores em tamanho em comparação com as redes de última geração, ainda são capazes de obter um desempenho de previsão de alta precisão.
Transferir aprendizado
Outro recurso muito poderoso das redes neurais artificiais, permitindo amplo uso dos modelos de Deep Learning, é o aprendizado de transferência . Uma vez que tenhamos um modelo treinado em alguns dados (criados por nós mesmos ou baixados de um repositório público), podemos construir todo ou parte dele para obter um modelo que resolva nosso caso de uso específico. Por exemplo, poderíamos usar um modelo NASNetLarge pré-treinado, treinado no enorme conjunto de dados ImageNet, que atribui um rótulo a uma imagem, faz algumas pequenas modificações na parte superior de sua estrutura, treiná-lo ainda mais com um novo conjunto de imagens rotuladas e use-o para rotular algum tipo específico de objetos (por exemplo, espécies de uma árvore com base na imagem de sua folha).
Vantagens do aprendizado de transferência
O aprendizado de transferência é muito útil, pois geralmente o treinamento de uma rede neural profunda que executará algumas tarefas práticas e úteis requer grandes quantidades de dados e enorme poder computacional. Isso geralmente pode significar milhões de instâncias de dados rotuladas e centenas de unidades de processamento gráfico (GPUs) em execução por semanas.
Nem todos podem pagar ou ter acesso a esses ativos, o que pode dificultar muito a criação de uma solução personalizada de alta precisão do zero para, digamos, classificação de imagens. Felizmente, alguns modelos pré-treinados (especialmente redes para classificação de imagens e matrizes de incorporação pré-treinadas para modelos de linguagem) foram de código aberto e estão disponíveis gratuitamente em uma forma facilmente aplicável (por exemplo, como uma instância de modelo em Keras, um sistema neural API de redes).
Como escolher e construir o modelo de Machine Learning certo para seu aplicativo
Quando você deseja aplicar o Machine Learning para resolver um problema de negócios, provavelmente não precisa decidir sobre o tipo de modelo imediatamente. Geralmente, existem algumas abordagens que podem ser testadas. Muitas vezes é tentador começar com os modelos mais complicados no início, mas vale a pena começar de forma simples e aumentar gradualmente a complexidade dos modelos aplicados. Modelos mais simples são geralmente mais baratos em termos de configuração, tempo de computação e recursos. Além disso, seus resultados são uma ótima referência para avaliar abordagens mais avançadas.
Ter esses benchmarks pode ajudar os cientistas de dados a avaliar se a direção em que desenvolvem seus modelos é a correta. Outra vantagem é a possibilidade de reaproveitar alguns dos modelos construídos anteriormente, e mesclá-los com outros mais novos, criando o chamado modelo ensemble. A mistura de modelos de diferentes tipos geralmente produz métricas de desempenho mais altas do que cada um dos modelos combinados sozinhos. Além disso, verifique se existem alguns modelos pré-treinados que podem ser usados e adaptados ao seu caso de negócios por meio do aprendizado de transferência.
Mais dicas práticas
Em primeiro lugar, seja qual for o modelo que você usa, certifique-se de que os dados sejam tratados adequadamente. Lembre-se da regra de 'entrar lixo, sair lixo'. Se os dados de treinamento fornecidos ao modelo forem de baixa qualidade ou não tiverem sido devidamente rotulados e limpos, é muito provável que o modelo resultante também tenha um desempenho insatisfatório. Certifique-se também de que o modelo – qualquer que seja sua complexidade – tenha sido amplamente validado durante a fase de modelagem e, no final, testado se generalizou bem para dados não vistos.
Em uma nota mais prática, certifique-se de que a solução criada pode ser implementada em produção na infraestrutura disponível. E se sua empresa puder coletar mais dados que possam ser usados para melhorar seu modelo no futuro, um pipeline de retreinamento deve ser preparado para garantir sua fácil atualização. Esse pipeline pode até ser configurado para retreinar automaticamente o modelo com uma frequência de tempo predefinida.
Pensamentos finais
Não se esqueça de acompanhar o desempenho e usabilidade do modelo após sua implantação para produção, pois o ambiente de negócios é muito dinâmico. Algumas relações dentro de seus dados podem mudar ao longo do tempo e novos fenômenos podem surgir. Eles podem, portanto, alterar a eficiência do seu modelo e devem ser tratados adequadamente. Além disso, novos e poderosos tipos de modelos podem ser inventados. Por um lado, eles podem tornar sua solução relativamente fraca, mas, por outro, dar a você a oportunidade de melhorar ainda mais seus negócios e aproveitar a tecnologia mais recente.
Além disso, os modelos de Machine e Deep Learning podem ajudá-lo a criar ferramentas poderosas para seus negócios e aplicativos e proporcionar aos seus clientes uma experiência excepcional . Embora a criação desses recursos 'inteligentes' exija um esforço substancial, os benefícios potenciais valem a pena. Apenas certifique-se de que você e sua equipe de Data Science experimentem modelos apropriados e sigam as boas práticas, e você estará no caminho certo para capacitar seus negócios e aplicativos com soluções de Machine Learning de ponta.
Fontes:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirectional_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf