
Deep Learning vs. Machine Learning: come distinguere?
Pubblicato: 2020-03-10Negli ultimi anni Machine Learning, Deep Learning e Intelligenza Artificiale sono diventate parole d'ordine. Di conseguenza, puoi trovarli ovunque nei materiali di marketing e negli annunci pubblicitari di un numero sempre maggiore di aziende.
Ma cosa sono Machine Learning e Deep Learning? Inoltre, quali sono le differenze tra loro? In questo articolo cercherò di rispondere a queste domande e ti mostrerò alcuni casi di applicazioni di Deep e Machine Learning.
Che cos'è l'apprendimento automatico?
L' apprendimento automatico è una parte dell'informatica che si occupa della rappresentazione di eventi o oggetti del mondo reale con modelli matematici, basati su dati. Questi modelli sono costruiti con algoritmi speciali che adattano la struttura generale del modello in modo che si adatti ai dati di addestramento. A seconda del tipo di problema da risolvere, definiamo algoritmi di Machine Learning e Machine Learning supervisionati e non.
Apprendimento automatico supervisionato e non supervisionato
Il Supervised Machine Learning si concentra sulla creazione di modelli in grado di trasferire le conoscenze che già abbiamo sui dati a portata di mano a nuovi dati. I nuovi dati non sono visti dall'algoritmo di costruzione del modello (formazione) durante la fase di formazione. Forniamo un algoritmo con i dati delle caratteristiche insieme ai valori corrispondenti che l'algoritmo dovrebbe imparare a dedurre da essi (la cosiddetta variabile target).
In Machine Learning non supervisionato, forniamo solo funzionalità all'algoritmo. Ciò gli consente di capire da solo la loro struttura e/o le loro dipendenze. Non è stata specificata una variabile target chiara. La nozione di apprendimento non supervisionato può essere difficile da comprendere all'inizio, ma dare un'occhiata agli esempi forniti nei quattro grafici seguenti dovrebbe chiarire questa idea.
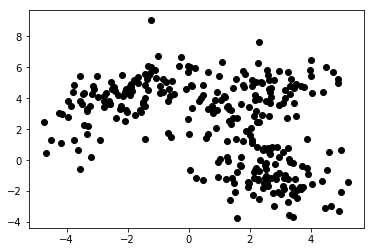
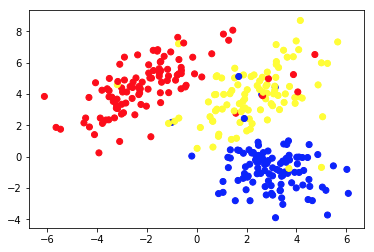
Il grafico 1a presenta alcuni dati descritti con 2 caratteristiche sugli assi xey . Quello contrassegnato come 1b mostra gli stessi dati colorati. Abbiamo utilizzato l'algoritmo di clustering K-means per raggruppare questi punti in 3 cluster e li abbiamo colorati di conseguenza. Questo è un esempio di algoritmo di Machine Learning non supervisionato . All'algoritmo venivano fornite solo le caratteristiche e le etichette (numeri del cluster) dovevano essere calcolate.
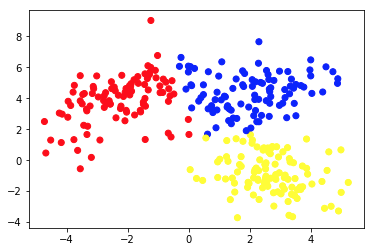
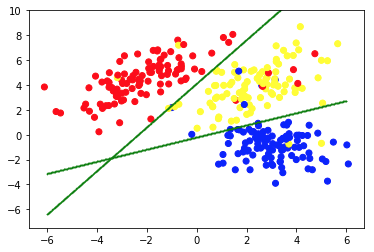
La seconda immagine mostra il grafico 2a, che presenta un diverso insieme di dati etichettati (e colorati di conseguenza). Sappiamo che i gruppi a cui ciascuno dei punti dati appartiene a priori . Usiamo un algoritmo SVM per trovare 2 linee rette che ci mostrerebbero come dividere i punti dati per adattarsi meglio a questi gruppi. Questa divisione non è perfetta, ma questo è il meglio che si può fare con le linee rette. Se vogliamo assegnare un gruppo a un nuovo punto dati senza etichetta, dobbiamo solo controllare dove si trova sull'aereo. Questo è un esempio di un'applicazione di Machine Learning supervisionata .
Applicazioni dei modelli di Machine Learning
Gli algoritmi di Machine Learning standard vengono creati per la gestione dei dati in forma tabellare. Ciò significa che per usarli abbiamo bisogno di una specie di tabella. In tale tabella le righe possono essere considerate come istanze dell'oggetto modellato (ad esempio, un prestito). Allo stesso tempo, le colonne dovrebbero essere viste come caratteristiche (caratteristiche) di questo caso particolare (ad esempio, pagamento mensile del prestito, reddito mensile del mutuatario).

Curioso sullo sviluppo del Machine Learning?
Scopri di piùLa tabella 1. è un esempio molto breve di tali dati. Naturalmente, ciò non significa che i dati puri stessi debbano essere tabulari e strutturati. Ma se vogliamo applicare un algoritmo di Machine Learning standard su un set di dati, di solito dobbiamo pulirlo, mescolarlo e trasformarlo in una tabella. Nell'apprendimento supervisionato, c'è anche una colonna speciale che contiene il valore target (ad esempio, informazioni se il prestito è inadempiente).
L'algoritmo di addestramento cerca di adattare la struttura generale del modello a questi dati. Detto algoritmo lo fa modificando i parametri del modello. Ciò si traduce in un modello che descrive la relazione tra i dati forniti e la variabile target nel modo più accurato possibile.
È importante che il modello non solo si adatti bene ai dati di addestramento forniti, ma sia anche in grado di generalizzare. La generalizzazione significa che possiamo utilizzare il modello per dedurre l'obiettivo per le istanze non utilizzate durante l'addestramento. È anche una caratteristica cruciale di un modello utile. Costruire un modello ben generalizzato non è un compito facile. Spesso richiede sofisticate tecniche di convalida e test approfonditi del modello.
| prestito_id | mutuatario_età | reddito_mensile | ammontare del prestito | pagamento mensile | predefinito |
| 1 | 34 | 10.000 | 100.000 | 1.200 | 0 |
| 2 | 43 | 5.700 | 25.000 | 800 | 0 |
| 3 | 25 | 2.500 | 24.000 | 400 | 0 |
| 4 | 67 | 4.600 | 40.000 | 2.000 | 1 |
| 5 | 38 | 35.000 | 2.500.000 | 10.000 | 0 |
Tabella 1. Dati del prestito in forma tabellare
Le persone usano algoritmi di Machine Learning in una varietà di applicazioni. La tabella 2. presenta alcuni casi d'uso aziendali che consentono algoritmi e modelli di Machine Learning non approfonditi. Ci sono anche brevi descrizioni dei dati potenziali, delle variabili target e degli algoritmi applicabili selezionati.
| Caso d'uso | Esempi di dati | Valore target (modellato). | Algoritmo/modello utilizzato |
| Raccomandazioni di articoli su un sito blog | ID degli articoli letti dagli utenti, tempo dedicato a ciascuno di essi | Preferenze degli utenti verso gli articoli | Filtraggio collaborativo con minimi quadrati alternati |
| Credit scoring dei mutui | Storia transazionale e creditizia, dati sul reddito di un potenziale mutuatario | Valore binario che mostra se un prestito verrà rimborsato per intero o andrà in default | LightGBM |
| Prevedere l'abbandono degli utenti premium di un gioco mobile | Tempo trascorso a giocare ogni giorno, tempo dal primo lancio, progressi nel gioco | Valore binario che mostra se un utente annullerà l'abbonamento il mese prossimo | XGBoost |
| Rilevamento frodi con carta di credito | Dati storici sulle transazioni con carta di credito: importo, luogo, data e ora | Valore binario che mostra se una transazione con carta di credito è fraudolenta | Foresta casuale |
| Segmentazione dei clienti di un negozio online | Cronologia degli acquisti dei membri del programma fedeltà | Numero di segmento assegnato a ogni cliente | K-mezzi |
| Manutenzione predittiva di un parco macchine | Dati da sensori di prestazioni, temperatura, umidità, ecc | Una delle seguenti classi: 'fine', 'da osservare', 'richiede manutenzione' | Albero decisionale |
Tabella 2. Esempi di casi d'uso di Machine Learning
Deep Learning e reti neurali profonde
Il Deep Learning fa parte del Machine Learning in cui utilizziamo modelli di un tipo specifico, chiamati reti neurali artificiali profonde (ANN). Dalla loro introduzione, le reti neurali artificiali hanno subito un ampio processo di evoluzione. Ciò ha portato a una serie di sottotipi, alcuni dei quali sono molto complicati. Ma per introdurli, è meglio spiegare una delle loro forme di base: un percettrone multistrato (MPL).
Percettrone multistrato
In poche parole, un MLP ha una forma di un grafo (rete) di vertici (chiamati anche neuroni) e bordi (rappresentati da numeri chiamati pesi). I neuroni sono disposti in strati e i neuroni in strati consecutivi sono collegati tra loro. I dati fluiscono attraverso la rete dall'input allo strato di output. I dati vengono quindi trasformati ai neuroni e ai bordi tra di loro. Una volta che un punto dati passa attraverso l'intera rete, il livello di output contiene i valori previsti nei suoi neuroni.
Ogni volta che una parte dei dati di addestramento passa attraverso la rete, confrontiamo le previsioni con i corrispondenti valori veri. Ciò ci consente di adattare i parametri (pesi) del modello per fare previsioni migliori. Possiamo farlo con un algoritmo chiamato backpropagation. Dopo un certo numero di iterazioni, se la struttura del modello è ben progettata specificamente per affrontare il problema di Machine Learning in questione.
Ottenere un modello ad alta precisione
Una volta che una quantità sufficiente di dati è passata attraverso la rete più volte, otteniamo un modello ad alta precisione. In pratica, ci sono molte trasformazioni che possono essere applicate ai neuroni. Ciò rende le RNA molto flessibili e potenti. Tuttavia, il potere delle ANN ha un prezzo. Di solito, più complicata è la struttura del modello, più dati e tempo sono necessari per addestrarlo a un'elevata precisione.
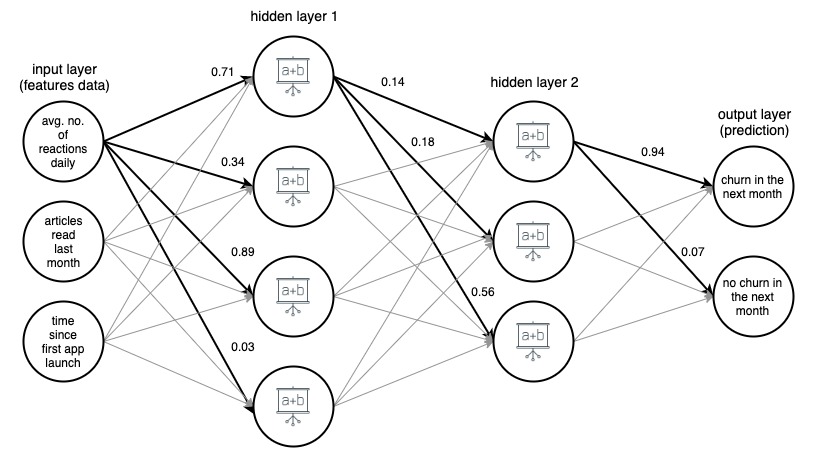
Immagine 1. (draw.io) Struttura di una rete neurale artificiale a 4 strati, che prevede se un utente di un'app di notizie cambierà il mese prossimo, sulla base di tre semplici funzionalità.
Per chiarezza, i pesi sono stati contrassegnati solo per i bordi selezionati (in grassetto), ma ogni bordo ha il proprio peso. I dati fluiscono dal livello di input al livello di output, passando attraverso 2 livelli nascosti nel mezzo. Su ciascun bordo, un valore di input viene moltiplicato per il peso del bordo e il prodotto risultante va al nodo in cui termina il bordo. Quindi, in ciascuno dei nodi negli strati nascosti, i segnali in arrivo dai bordi vengono sommati e quindi trasformati con qualche funzione. Il risultato di queste trasformazioni viene quindi trattato come input per il livello successivo.
Nel livello di output, i dati in entrata vengono nuovamente sommati e trasformati, ottenendo il risultato sotto forma di due numeri: la probabilità che un utente abbandoni l'app nel mese successivo e la probabilità che non lo faccia.
Tipi avanzati di reti neurali
Nelle reti neurali di tipo più avanzato, gli strati hanno una struttura molto più complessa. Sono costituiti non solo da semplici strati densi con neuroni a un'operazione noti dagli MLP, ma anche da strati molto più complicati e multi-operazione come strati convoluzionali e ricorrenti.
Strati convoluzionali e ricorrenti
Gli strati convoluzionali sono usati principalmente nelle applicazioni di visione artificiale. Sono costituiti da piccoli array di numeri che scorrono sulla rappresentazione in pixel dell'immagine. I valori dei pixel vengono moltiplicati per questi numeri e quindi aggregati, ottenendo una nuova rappresentazione condensata dell'immagine.
I livelli ricorrenti vengono utilizzati per modellare dati sequenziali ordinati come serie temporali o testo . Applicano trasformazioni multi-argomento molto complicate ai dati in entrata, cercando di capire le dipendenze tra gli elementi della sequenza. Tuttavia, indipendentemente dal tipo e dalla struttura della rete, ci sono sempre alcuni (uno o più) livelli di input e output e percorsi e direzioni rigorosamente definiti in cui i dati fluiscono attraverso la rete.
In generale, le reti neurali profonde sono ANN con più livelli. Le immagini 1, 2 e 3 di seguito mostrano le architetture di reti neurali artificiali profonde selezionate. Sono stati tutti sviluppati e formati presso Google e resi disponibili al pubblico. Danno un'idea di quanto siano complesse le reti artificiali profonde ad alta precisione utilizzate oggi.
Queste reti hanno dimensioni enormi. Ad esempio, parzialmente mostrato nell'immagine 3 InceptionResNetV2 ha 572 livelli e oltre 55 milioni di parametri in totale! Sono stati tutti sviluppati come modelli di classificazione delle immagini (assegnano un'etichetta, ad esempio 'auto' a una determinata immagine), e sono stati addestrati su immagini del set ImageNet, composto da oltre 14 milioni di immagini etichettate.
Immagine 2. Struttura di NASNetMobile (pacchetto keras)


Immagine 3. Struttura di XCeption (pacchetto keras)

Immagine 4. Struttura di una parte (circa il 25%) di InceptionResNetV2 (pacchetto keras)
Negli ultimi anni abbiamo osservato un grande sviluppo nel Deep Learning e nelle sue applicazioni. Molte delle funzionalità "intelligenti" dei nostri smartphone e delle nostre applicazioni sono il frutto di questo progresso. Sebbene l'idea delle RNA non sia nuova, questo recente boom è il risultato del soddisfacimento di alcune condizioni. Prima di tutto, abbiamo scoperto il potenziale del GPU Computing. L'architettura delle unità di elaborazione grafica è ottima per il calcolo parallelo, molto utile per un apprendimento profondo efficiente.
Inoltre, l'aumento dei servizi di cloud computing ha reso l'accesso a hardware ad alta efficienza molto più semplice, economico e possibile su scala molto più ampia. Infine, la potenza di calcolo dei dispositivi mobili più recenti è abbastanza grande da poter applicare modelli di Deep Learning, creando un enorme mercato di potenziali utenti di funzionalità basate su DNN.
Applicazioni dei modelli di Deep Learning
I modelli di deep learning vengono solitamente applicati a problemi che riguardano dati che non hanno una semplice struttura riga-colonna, come la classificazione delle immagini o la traduzione linguistica, poiché sono ottimi per operare su dati non strutturati e di struttura complessa gestiti da queste attività: immagini, testo e suono. Ci sono problemi con la gestione di dati di questi tipi e dimensioni con gli algoritmi di Machine Learning classici e la creazione e l'applicazione di alcune reti neurali profonde a questi problemi ha causato enormi sviluppi nei campi del riconoscimento delle immagini, del riconoscimento vocale, della classificazione del testo e della traduzione linguistica nel negli ultimi anni.
L'applicazione del Deep Learning a questi problemi è stata possibile grazie al fatto che i DNN accettano tabelle di numeri multidimensionali, chiamate tensori, sia come input che come output, e possono tracciare le relazioni spaziali e temporali tra i loro elementi. Ad esempio, possiamo presentare un'immagine come un tensore tridimensionale, dove la dimensione uno e due rappresentano la risoluzione dell'immagine digitale (quindi hanno le dimensioni della larghezza e dell'altezza dell'immagine, rispettivamente), e la terza dimensione rappresenta il colore RGB codifica di ciascuno dei pixel (quindi la terza dimensione è di dimensione 3).
Ciò ci consente non solo di rappresentare tutte le informazioni sull'immagine in un tensore, ma anche di mantenere le relazioni spaziali tra i pixel, che risultano essere cruciali nell'applicazione dei cosiddetti strati convoluzionali, cruciali per la classificazione delle immagini e le reti di riconoscimento di successo.
La flessibilità della rete neurale nelle strutture di input e output aiuta anche in altre attività, come la traduzione linguistica . Quando si tratta di dati testuali, alimentiamo le reti neurali profonde con rappresentazioni numeriche delle parole, ordinate in base alla loro comparsa nel testo. Ogni parola è rappresentata da un vettore di cento o poche centinaia di numeri, calcolato (di solito utilizzando una rete neurale diversa) in modo che le relazioni tra vettori corrispondenti a parole diverse imitino le relazioni delle parole stesse. Queste rappresentazioni del linguaggio vettoriale, chiamate embedding, una volta addestrate, possono essere riutilizzate in molte architetture e sono un elemento fondamentale dei modelli linguistici delle reti neurali.
Esempi di utilizzo di modelli di Deep Learning
La Tabella 3. contiene esempi di applicazione dei modelli di Deep Learning a problemi della vita reale. Come puoi vedere, i problemi affrontati e risolti dagli algoritmi di Deep Learning sono molto più complessi dei compiti risolti dalle tecniche di Machine Learning standard, come quelle presentate nella Tabella 1.
Tuttavia, è importante ricordare che molti dei casi d'uso che Machine Learning può aiutare con le aziende oggi non richiedono metodi così sofisticati e possono essere risolti in modo più efficiente (e con maggiore precisione) da modelli standard. La tabella 3. fornisce anche un'idea di quanti diversi tipi di strati di reti neurali artificiali esistono e quante diverse architetture utili possono essere costruite con essi.
| Caso d'uso | Dati | Obiettivo/risultato del modello | Algoritmo/modello utilizzato |
| Classificazione delle immagini | immagini | Etichetta assegnata a un'immagine | Rete neurale convoluzionale (CNN) |
| Rilevamento di immagini da parte di auto a guida autonoma | immagini | Etichette e riquadri di delimitazione attorno agli oggetti identificati nelle immagini | R-CNN veloce |
| Sentimento analisi di commenti in un negozio online | Testo dei commenti online | Etichetta del sentimento (ad es. positivo, neutro, negativo) assegnata a ciascun commento | Rete bidirezionale di memoria a lungo termine (LSTM). |
| Armonizzazione di una melodia | File MIDI con una melodia | File MIDI con questa melodia armonizzata | Rete generativa contraddittoria |
| Predizione della parola successiva in un in linea editore | Pezzo di testo molto grande (ad es. dump di tutti gli articoli di Wikipedia in inglese) | Una parola che si adatta come la prossima al testo scritto finora | Recurrent Neural Network (RNN) con un livello di incorporamento |
| Traduzione del testo in un'altra lingua | Testo in polacco | Lo stesso testo tradotto in inglese | Codificatore: rete di decodifica costruita con livelli di reti neurali ricorrenti (RNN). |
| Trasferimento dello stile di Monet su qualsiasi immagine | Insieme di immagini dei dipinti di Monet e un insieme di altre immagini | Immagini modificate per sembrare dipinte da Monet | Rete generativa contraddittoria |
Tabella 3. Esempi di casi d'uso di Deep Learning
Vantaggi dei modelli di Deep Learning
Reti generative contraddittorie
Una delle applicazioni più impressionanti delle reti neurali profonde è arrivata con l'ascesa delle reti generative contraddittorio (GAN). Sono stati introdotti nel 2014 da Ian Goodfellow e da allora la sua idea è stata incorporata in molti strumenti, alcuni con risultati sorprendenti.
I GAN sono responsabili dell'esistenza di applicazioni che ci fanno sembrare più vecchi nelle foto, trasformano le immagini in modo che sembrino dipinte da van Gogh o addirittura armonizzano le melodie per più bande di strumenti. Durante l'addestramento di un GAN, due reti neurali competono. Una rete di generatori genera un output da un input casuale, mentre il discriminatore cerca di distinguere le istanze generate da quelle reali. Durante l'addestramento, il generatore impara come "ingannare" con successo il discriminatore e alla fine è in grado di creare un output che sembra reale.
Potenti reti neurali profonde nelle app mobili
È importante notare che, anche se l'addestramento di una rete neurale profonda è un'attività molto dispendiosa dal punto di vista computazionale e può richiedere molto tempo, non è necessario applicare una rete addestrata per eseguire un'attività specifica, soprattutto se viene applicata a uno o a un pochi casi contemporaneamente. In realtà, oggi siamo in grado di eseguire potenti reti neurali profonde in applicazioni mobili sui nostri smartphone.
Esistono anche alcune architetture di rete specificamente progettate per essere efficienti quando applicate su dispositivi mobili (ad esempio, NASNetMobile presentato nell'immagine 1). Anche se sono di dimensioni molto più ridotte rispetto alle reti all'avanguardia, sono comunque in grado di ottenere prestazioni di previsione ad alta precisione.
Trasferisci l'apprendimento
Un'altra caratteristica molto potente delle reti neurali artificiali, che consente un ampio uso dei modelli di Deep Learning, è il transfer learning . Una volta che abbiamo un modello addestrato su alcuni dati (creati da noi stessi o scaricati da un repository pubblico), possiamo basarci su tutto o parte di esso per ottenere un modello che risolva il nostro caso d'uso particolare. Ad esempio, potremmo utilizzare un modello NASNetLarge pre-addestrato, addestrato sull'enorme set di dati ImageNet, che assegna un'etichetta a un'immagine, apporta alcune piccole modifiche sulla parte superiore della sua struttura, addestralo ulteriormente con un nuovo set di immagini etichettate e usalo per etichettare alcuni tipi specifici di oggetti (es. specie di un albero in base all'immagine della sua foglia).
Vantaggi del trasferimento di apprendimento
L'apprendimento del trasferimento è molto utile, poiché di solito l'addestramento di una rete neurale profonda che eseguirà alcune attività pratiche e utili richiede grandi quantità di dati e un'enorme potenza di calcolo. Ciò può spesso significare milioni di istanze di dati etichettate e centinaia di unità di elaborazione grafica (GPU) in esecuzione per settimane.
Non tutti possono permettersi o hanno accesso a tali risorse, il che può rendere molto difficile creare da zero una soluzione personalizzata ad alta precisione per, diciamo, la classificazione delle immagini. Fortunatamente, alcuni modelli pre-addestrati (in particolare le reti per la classificazione delle immagini e le matrici di incorporamento pre-addestrate per i modelli linguistici) sono stati open source e sono disponibili gratuitamente in una forma facilmente applicabile (ad es. come istanza di modello in Keras, un API di rete).
Come scegliere e creare il giusto modello di Machine Learning per la tua applicazione
Quando si desidera applicare il Machine Learning per risolvere un problema aziendale, probabilmente non è necessario decidere subito il tipo di modello. Di solito ci sono alcuni approcci che potrebbero essere testati. Spesso si è tentati di iniziare con i modelli più complicati all'inizio, ma vale la pena iniziare in modo semplice e aumentare gradualmente la complessità dei modelli applicati. I modelli più semplici sono generalmente più economici in termini di configurazione, tempo di calcolo e risorse. Inoltre, i loro risultati sono un ottimo punto di riferimento per valutare approcci più avanzati.
Avere tali benchmark può aiutare i data scientist a valutare se la direzione in cui sviluppano i loro modelli è quella giusta. Un altro vantaggio è la possibilità di riutilizzare alcuni dei modelli costruiti in precedenza e fonderli con quelli più recenti, creando un cosiddetto modello d'insieme. La combinazione di modelli di diversi tipi produce spesso metriche di prestazioni più elevate rispetto a ciascuna delle sole modelli combinati. Inoltre, controlla se ci sono alcuni modelli pre-addestrati che potrebbero essere utilizzati e adattati al tuo caso aziendale tramite l'apprendimento del trasferimento.
Suggerimenti più pratici
Innanzitutto, qualunque sia il modello utilizzato, assicurati che i dati siano gestiti correttamente. Tieni presente la regola "spazzatura dentro, spazzatura fuori". Se i dati di addestramento forniti al modello sono di bassa qualità o non sono stati adeguatamente etichettati e puliti, è molto probabile che anche il modello risultante funzioni male. Assicurati inoltre che il modello, qualunque sia la sua complessità, sia stato ampiamente convalidato durante la fase di modellazione e, alla fine, verificato se si generalizza bene a dati invisibili.
In una nota più pratica, assicurati che la soluzione creata possa essere implementata in produzione sull'infrastruttura disponibile. E se la tua azienda può raccogliere più dati che potrebbero essere utilizzati per migliorare il tuo modello in futuro, è necessario preparare una pipeline di riqualificazione per garantirne un facile aggiornamento. Tale pipeline può anche essere configurata per riqualificare automaticamente il modello con una frequenza temporale predefinita.
Pensieri finali
Non dimenticare di tenere traccia delle prestazioni e dell'usabilità del modello dopo la sua distribuzione alla produzione, poiché l'ambiente aziendale è molto dinamico. Alcune relazioni all'interno dei tuoi dati possono cambiare nel tempo e possono sorgere nuovi fenomeni. Possono, quindi, modificare l'efficienza del tuo modello e dovrebbero essere trattati correttamente. Inoltre, è possibile inventare nuovi e potenti tipi di modelli. Da un lato, possono rendere la tua soluzione relativamente debole, ma dall'altro, darti l'opportunità di migliorare ulteriormente il tuo business e sfruttare la tecnologia più recente.
Inoltre, i modelli Machine e Deep Learning possono aiutarti a creare potenti strumenti per la tua azienda e le tue applicazioni e offrire ai tuoi clienti un'esperienza eccezionale . Sebbene la creazione di queste funzionalità "intelligenti" richieda uno sforzo notevole, ne vale la pena per i potenziali vantaggi. Assicurati solo che tu e il tuo team di Data Science provi modelli appropriati e segui le buone pratiche e sarai sulla strada giusta per potenziare la tua azienda e le tue applicazioni con soluzioni di Machine Learning all'avanguardia.
Fonti:
- https://en.wikipedia.org/wiki/Unsupervised_learning
- https://keras.io/
- https://developer.nvidia.com/deep-learning
- https://keras.io/applications/
- https://arxiv.org/abs/1707.07012
- http://yifanhu.net/PUB/cf.pdf
- https://towardsdatascience.com/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9
- https://scikit-learn.org/stable/modules/tree.html
- https://aws.amazon.com/deepcomposer/
- https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html
- https://keras.io/examples/nlp/bidirezionale_lstm_imdb/
- https://towardsdatascience.com/how-do-self-driving-cars-see-13054aee2503
- https://towardsdatascience.com/r-cnn-fast-r-cnn-faster-r-cnn-yolo-object-detection-algorithms-36d53571365e
- https://towardsdatascience.com/building-a-next-word-predictor-in-tensorflow-e7e681d4f03f
- https://keras.io/applications/
- https://arxiv.org/pdf/1707.07012.pdf