
如何在工具箱中使用正則表達式
已發表: 2022-04-17- 什麼是正則表達式?
- 我們如何構建正則表達式?
- 帶有正則表達式的 SEO 示例
- 使用正則表達式過濾關鍵字
- 包括或排除品牌名稱
- 在品牌字詞中包含或排除錯誤
- 包括或排除以特定字詞結尾的關鍵字字詞
- 包含或排除以特定字詞開頭的關鍵字字詞
- 包括或排除與特定屬性相關的關鍵字詞
- 包含或排除包含英國城市名稱的關鍵字詞
- 使用正則表達式過濾 URL
- 包括或排除子域
- 包括或排除以 / 結尾或不結尾的 URL
- 包括或排除包含數字的 URL
- 包含或排除特定格式的 URL
- 包含或排除與錯誤市場相關的 URL
- 概括
什麼是正則表達式?
正則表達式用於檢查或驗證模式。 它們的主要應用是過濾元素和查找匹配項,例如,在以下場景中:
- 分析:您可以使用正則表達式來細分流量。
- Htaccess:您可以以更有效的方式重寫 URL。
- SISTRIX:您可以過濾我們包含 URL、片段或關鍵字的報告。
正則表達式 - 或 Regex - 可用於許多編程語言,但本教程將基於 Perl,因為它使用已可用的 SISTRIX Regex 功能所基於的標準。
我們如何構建正則表達式?
我們將通過使用字符、分組、量詞和類來做到這一點,因為這是我們將能夠構建表達式的語法。
| 人物 | 行為 | 例子 |
|---|---|---|
| ? | 查找前面的字符 1 次或 0 次。 | HTTPS? |
| * | 查找前面的字符 0 次或更多次。 | 30* |
| + | 查找前面的字符 1 次或多次。 | [0-9]+ |
| | | 尋找一個或另一個元素。 (或者) | (jpg|jpeg) |
| ^ | 表示模式的開始 | ^https |
| $ | 表示模式的結束 | html$ |
| · | 查找任何字符(通配符) | 4.. |
| \ | 不解釋特殊字符(跳過字符) | \/ |
| 分組 | 行為 | 例子 |
|---|---|---|
| () | 捕獲特定內容 | (西斯特里克斯) 匹配 sistrix |
| [] | 捕獲括號內的字符 | [0-9] 匹配任何數字字符 [阿茲] 匹配任何小寫字母 |
| {} | 指示迭代次數,最小值或最大值 | .{1,3} 匹配任何重複 1 到 3 次的字符。 |
在本教程中,我們不會使用量詞,但我們認為熟悉它們對您來說仍然很有趣,以防您在其他環境中使用它們。
| 量詞 | 行為 |
|---|---|
| \w | 查找單詞、數字或 _ 類型的字符 |
| \d | 尋找數字字符 |
| \s | 尋找空白字符 |
| \b | 匹配單詞的開頭或結尾 |
| \W | 查找不是單詞、數字或 _ 的字符 |
| \D | 查找不是數字的字符 |
| \S | 查找不是空格的字符。 |
帶有正則表達式的 SEO 示例
為了能夠使用建議的示例,您需要轉到“關鍵字”部分並使用關鍵字、URL、標題或描述過濾器。
使用正則表達式過濾關鍵字
要訪問此功能,您只需分析域1並轉到關鍵字2 ,然後轉到過濾器選擇3
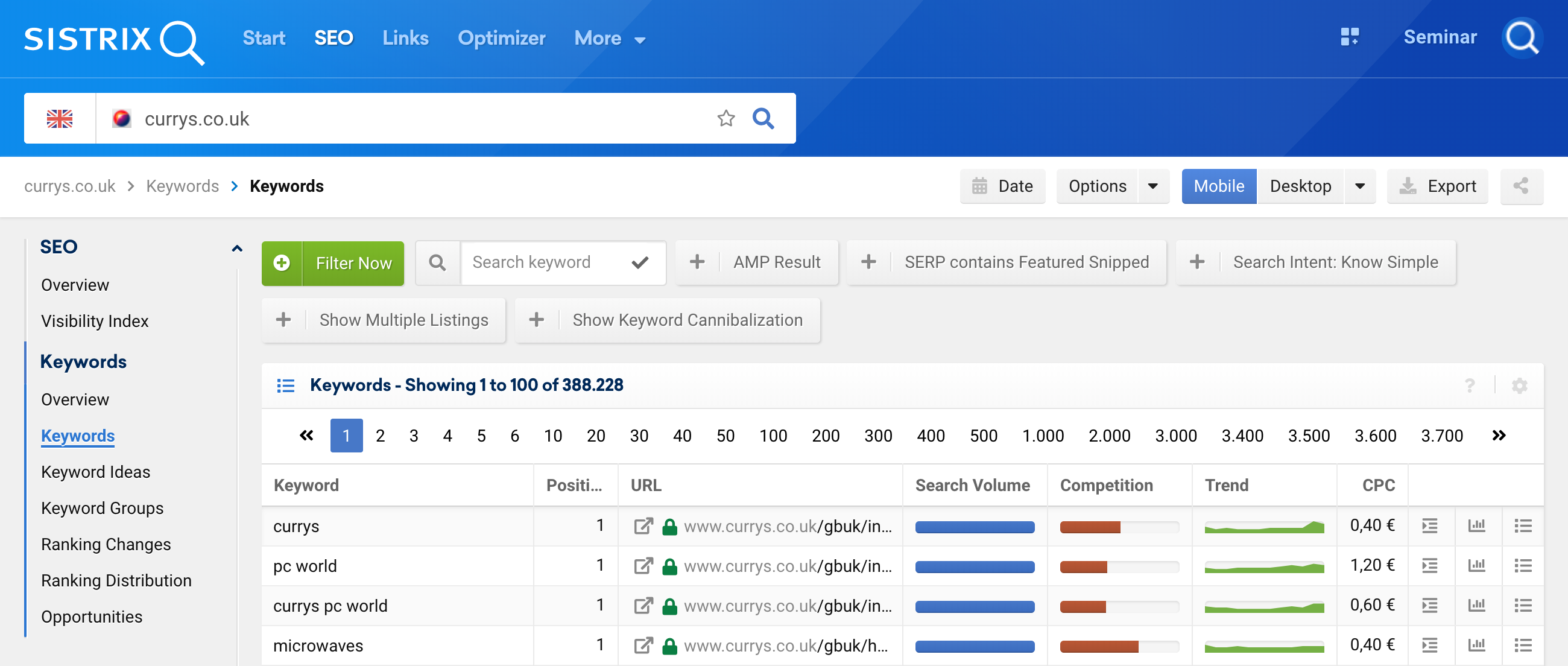
然後,將關鍵字過濾器與 Regex 4一起使用。
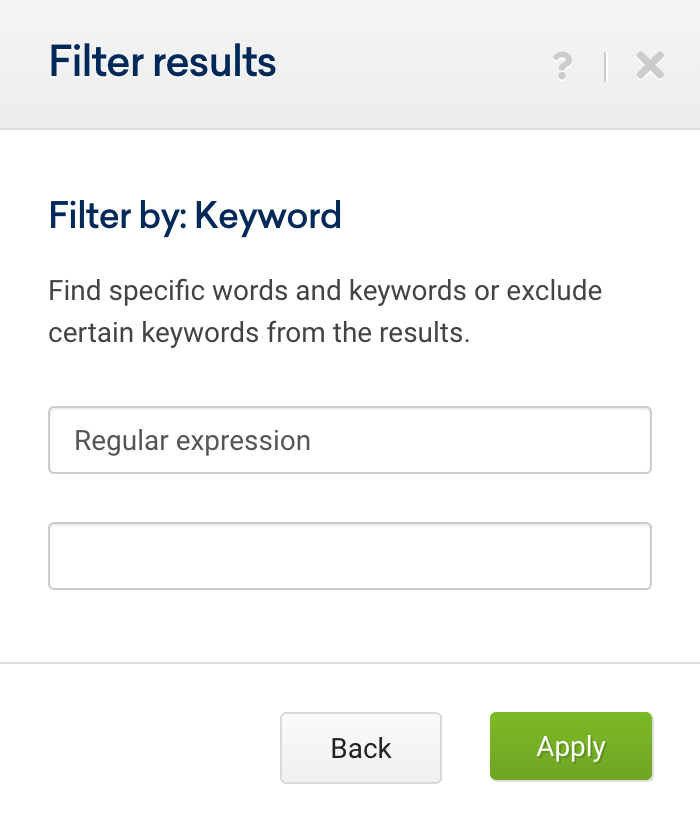
現在,我們想提出幾個用例,您可以在其中應用這些表達式,以充分利用項目的關鍵字分析,或者在分析競爭對手時。
包括或排除品牌名稱
想像一下,您有一個接受不同拼寫的品牌,或者有幾個不同的品牌名稱。 我們可以創建一個正則表達式來對我們認為是品牌術語的所有關鍵字進行分組。 例如,currys.co.uk 有各種品牌關鍵詞,即:
咖哩, 咖哩, 電腦世界
因此,我們將使用以下表達式:
(curry|currys|pc world).* 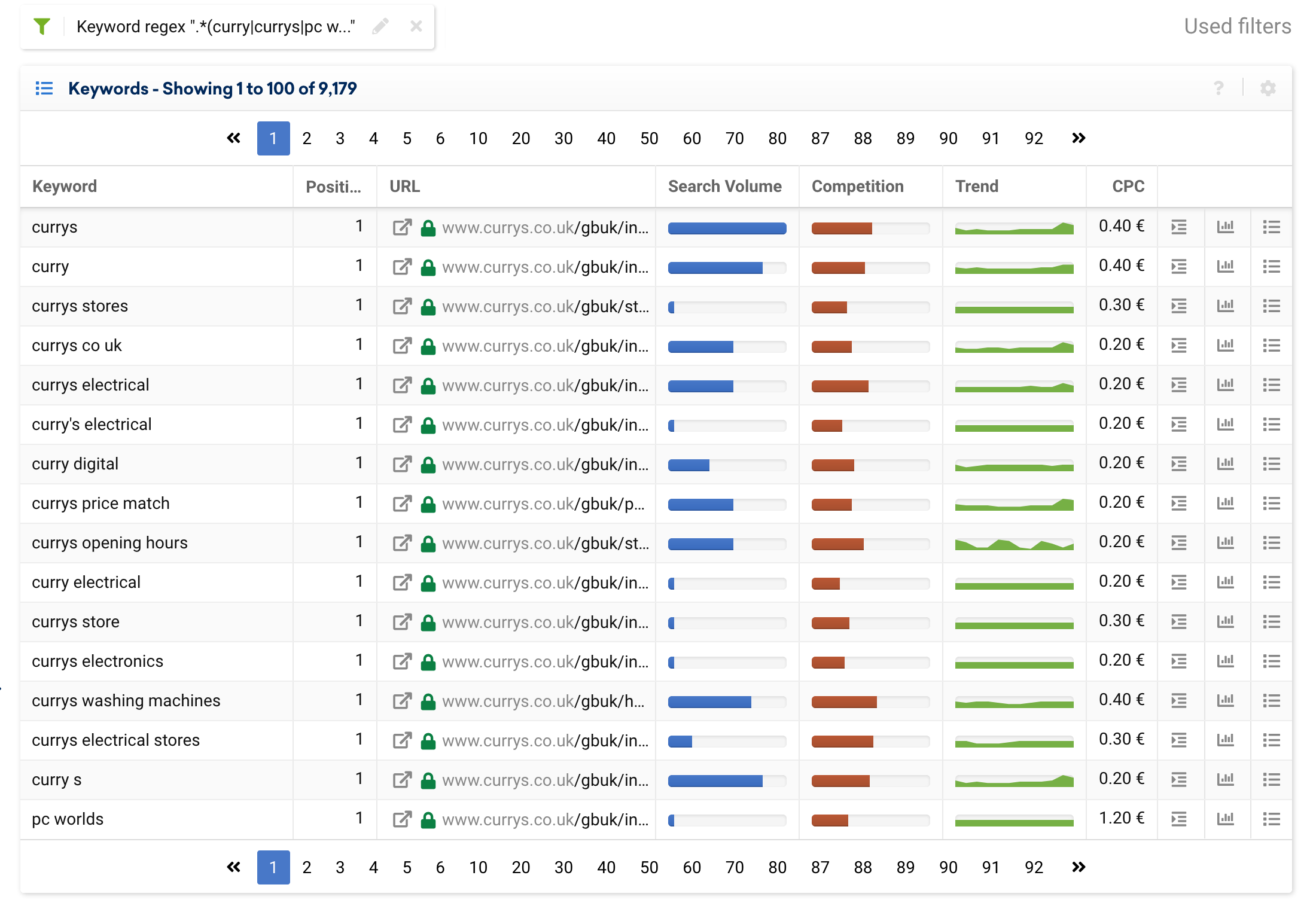
您可以在下面看到我們將得到的結果:
也可以使用以下表達式將過濾器設置為排除品牌關鍵字,它將僅顯示通用關鍵字:
^(?!.*(curry|currys|pc world).*?) 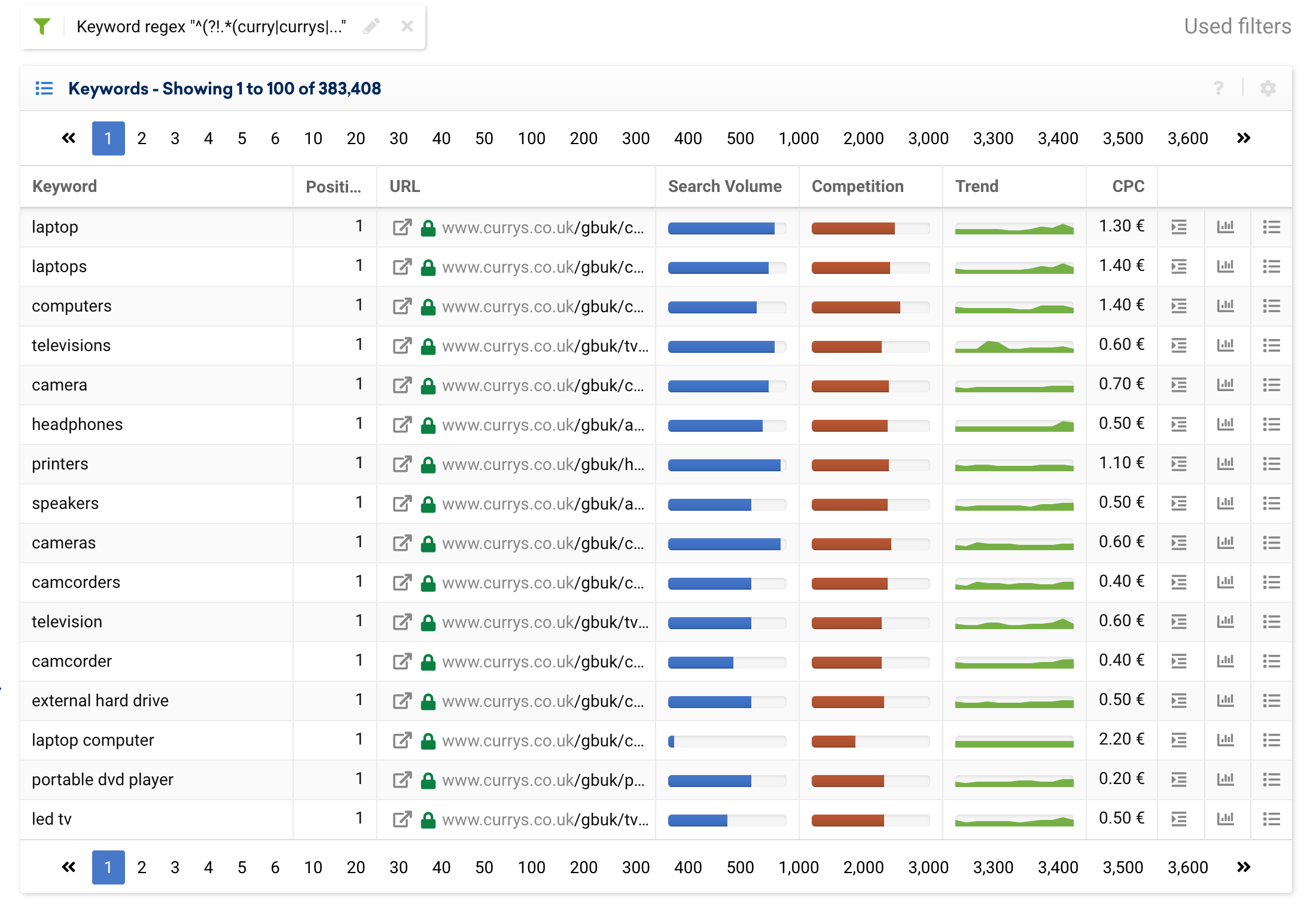
在品牌字詞中包含或排除錯誤
我們可能會遇到品牌,這些品牌經常拼寫錯誤或寫有錯誤,例如瑞安航空。
以下是用戶輸入以查找該航空公司的一些術語示例:
- 瑞安航空
- 雷亞納
- 瑞安艾爾
- 拉揚紅外線
- 瑞亞那艾爾
- 拉亞奈爾
- 拉揚阿里
- 雷亞爾空氣
我們已經確定了超過 35 個品牌名稱,我們只需使用一個正則表達式即可捕獲:
包括所有品牌變體:
(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)? ![ryanair.com 的 SISTRIX 工具箱中的關鍵字表,帶有正則表達式過濾器“.(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|行|)?(行|ir)?"應用。](/uploads/article/246/J4RlqK5XMR1iRPm6.png)
排除所有品牌變體:
^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$ ![ryanair.com 的 SISTRIX 工具箱中的關鍵字表,帶有正則表達式過濾器“^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air) ?(e|lines| )?(line|ir)?).)*$" 應用。](/uploads/article/246/x8B4lxmc6Vmja5ch.png)
當然,我們仍然可以將其他過濾器應用於此列表,例如“包含”、“不包含”、“結束於”或“開始於”。
包括或排除以特定字詞結尾的關鍵字字詞
要搜索一個唯一的關鍵字,一個簡單的過濾器就足夠了,但是如果我們想要執行多個條件的搜索,例如:所有以“buy”開頭並以“online”結尾的關鍵字,我們可以使用:
^buy.*online$這適用於像螺絲釘這樣的在線商店,將返回以下結果:
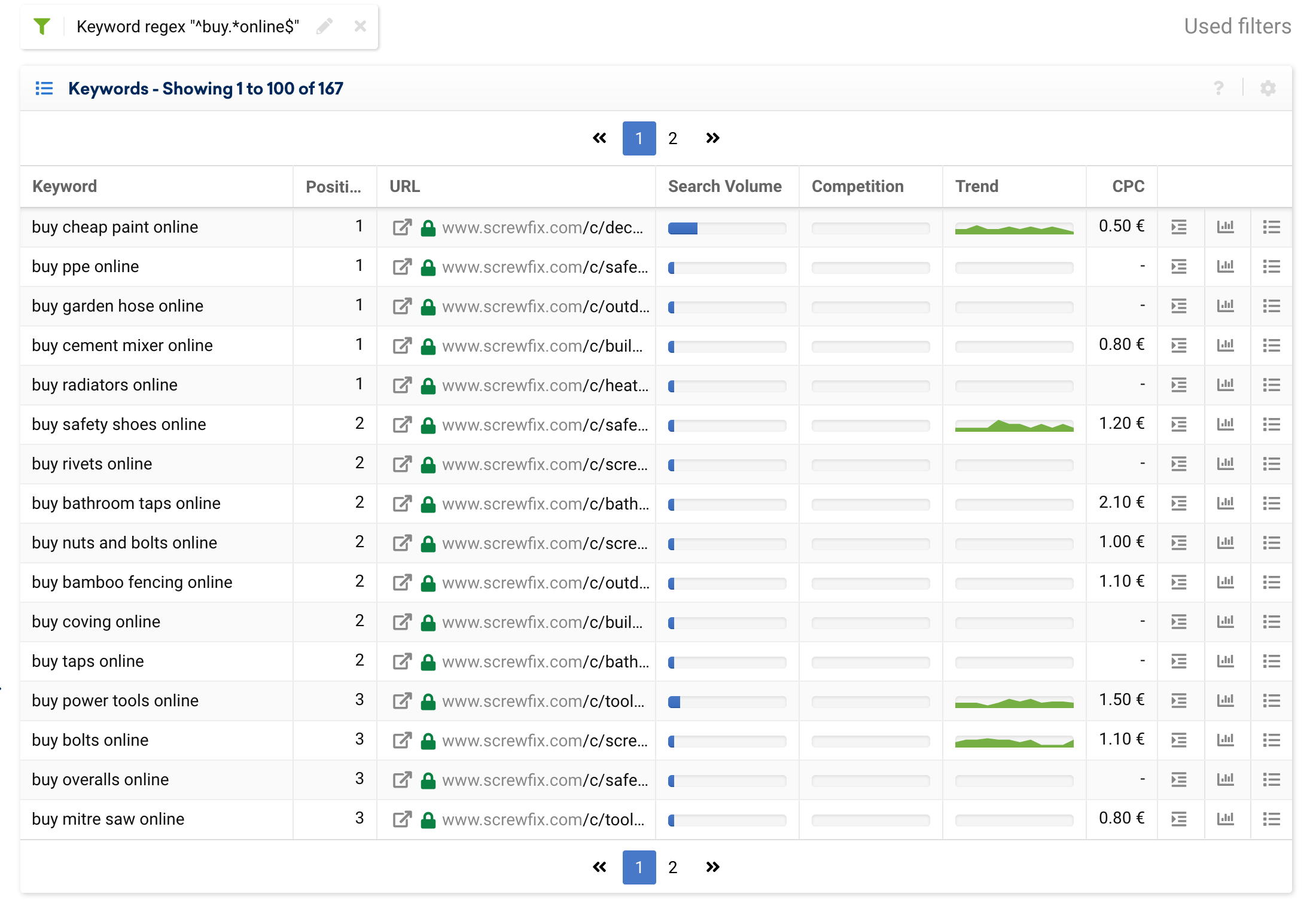
包含或排除以特定字詞開頭的關鍵字字詞
從比較工具的角度來看,能夠過濾包含各種品牌名稱的關鍵字可能會很有趣。
例如,我們可以創建一個正則表達式,它將根據我們想要的條件對術語進行分組,在這種情況下,任何以括號內包含的任何品牌名稱開頭的關鍵字術語:
^(sony|panasonic|philips|samsung).*同樣,我們可以使用它來排除它們:

^(?!(sony|panasonic|philips|samsung).*)包括或排除與特定屬性相關的關鍵字詞
讓我們用一個在許多項目中經常遇到的屬性的例子來試試這個:價格。
有許多暗示價格的搜索查詢,例如:“便宜”、“折扣”、“奧特萊斯”、“優惠券”、“報價”、“低成本”、“預算”等。
如果我們想從結果中排除它們,我們可以使用以下表達式:
.*(cheap|budget|offer|outlet|price).* 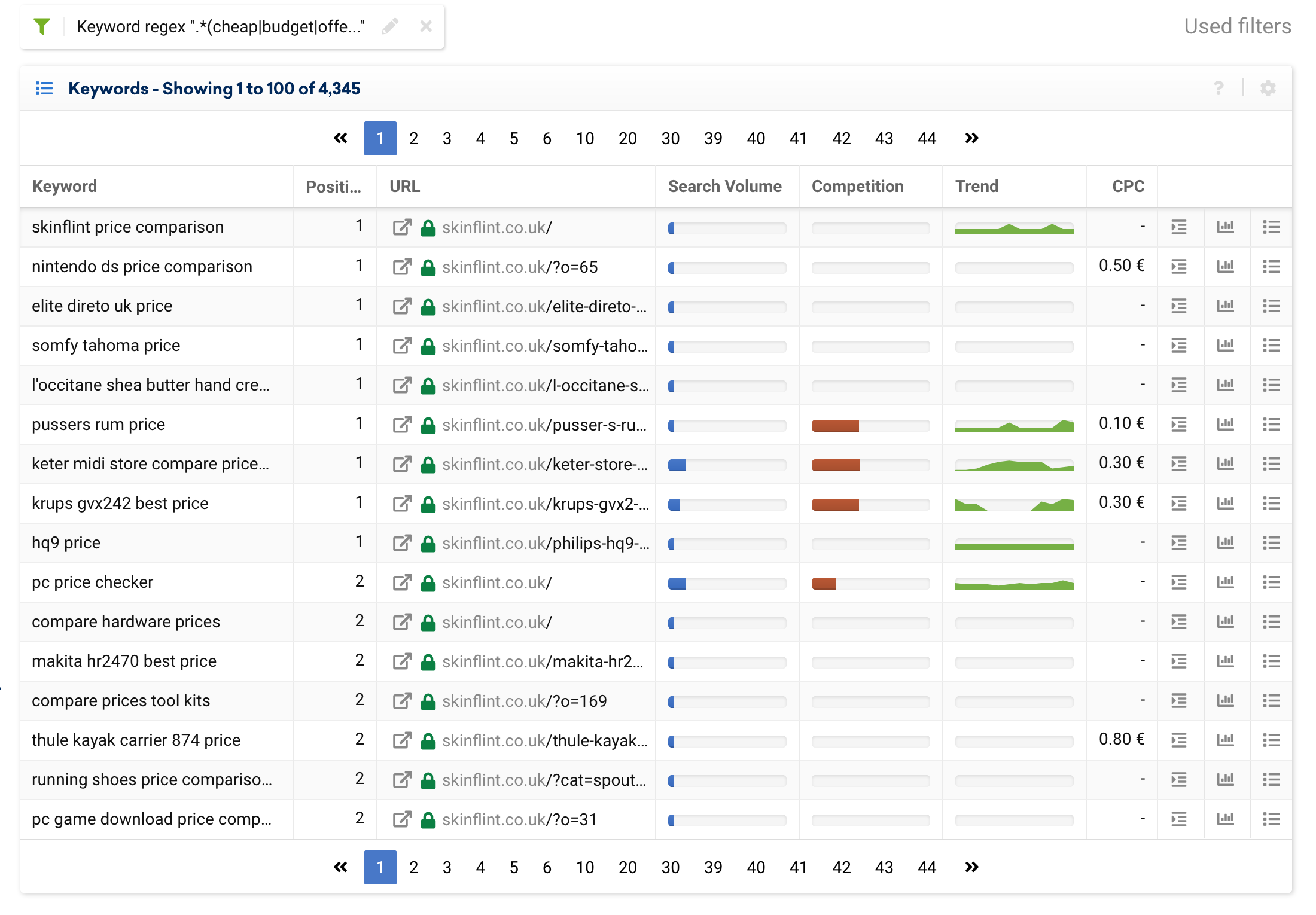
利用表格的動態列,我們可以按搜索量按降序組織數據,只需單擊列的標題即可。
在其他情況下,我們還可以使用其他屬性,如顏色、形狀、大小、目標等。
包含或排除包含英國城市名稱的關鍵字詞
許多項目需要本地存在跟踪。 為此,我們可以使用正則表達式對省、地區、城市、城鎮等進行分組。
在此示例中,我們將使用城市列表構建一個正則表達式,該表達式將過濾包含城市的關鍵字詞。
.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*任何有實體存在的電子商務企業或比較工具都可以使用此表達式來排除城市,甚至添加品牌關鍵字或排除其他參數。
^(?!(.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*))但是,我們也可以將它們分成幾個表達式,如下所示:
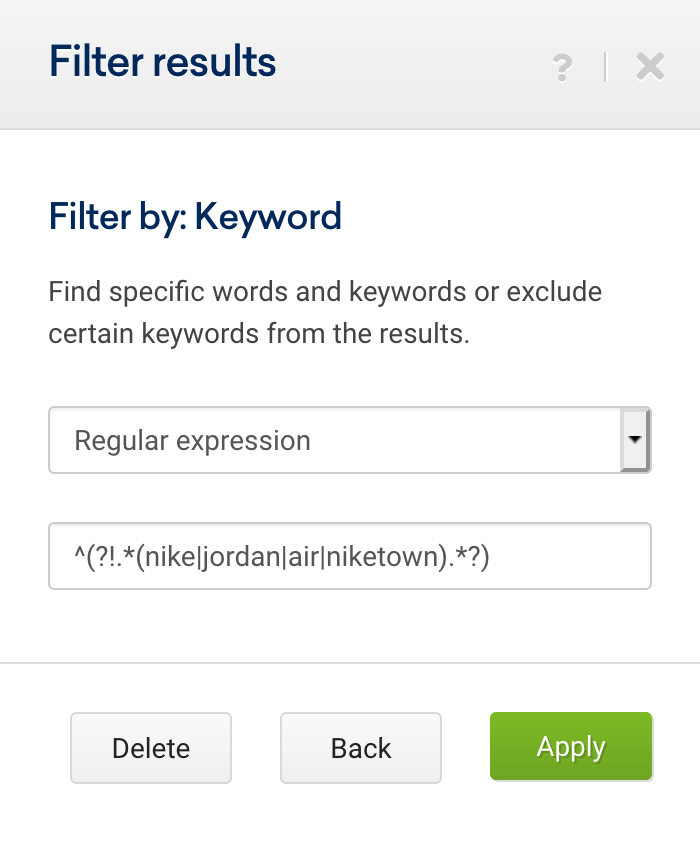
從這裡開始,我們添加專家過濾器以指示這兩個表達式的類型是“and”,而不是類型“or”。
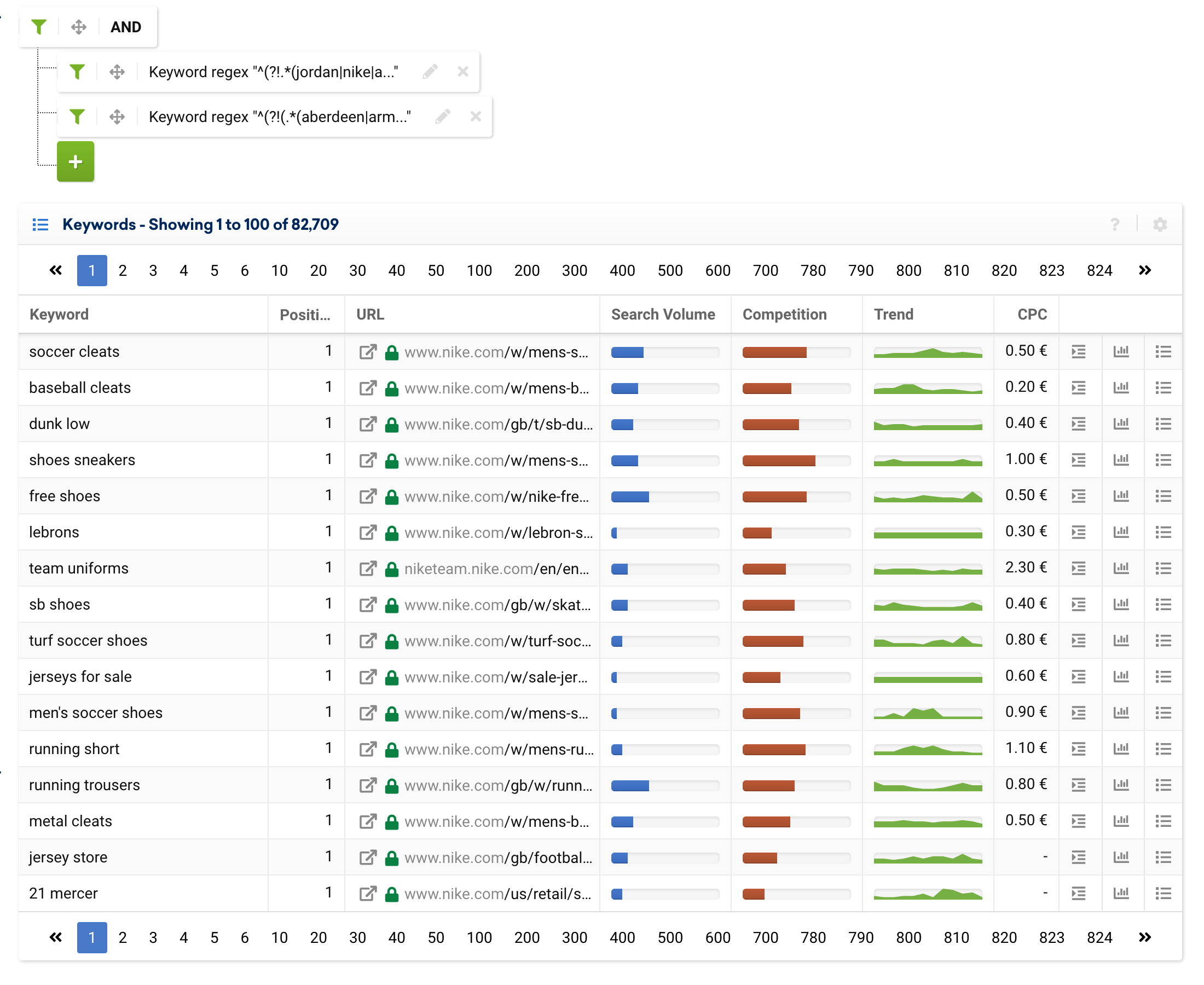
使用正則表達式過濾 URL
為了過濾 URL,您需要遵循的步驟與我們為關鍵字探索的步驟相同,唯一的區別是,您必須選擇“URL”,然後選擇正則表達式。
包括或排除子域
現在我們已經學習瞭如何使用正則表達式來過濾關鍵字,讓我們找到一些需要過濾 URL 的典型 SEO 用例。
以下是分析整個域並按戰略子域對 URL 進行分組的一些基本用例:
(www|support) 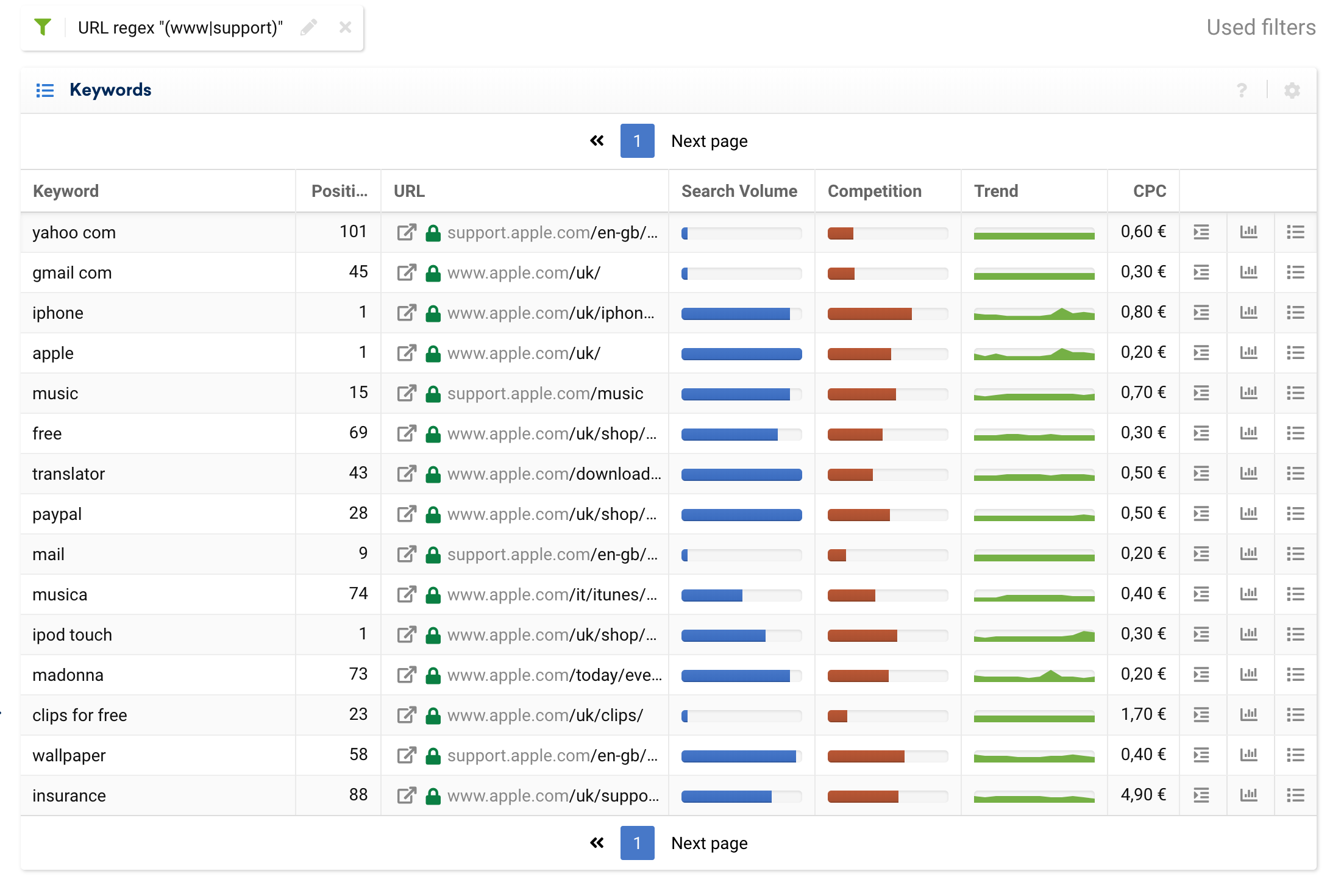
例如,我們可以使用排除過濾器來分離純事務性子域,並忽略來自博客或常見問題解答的信息關鍵字。
^^(?!.*(www|support).*?) 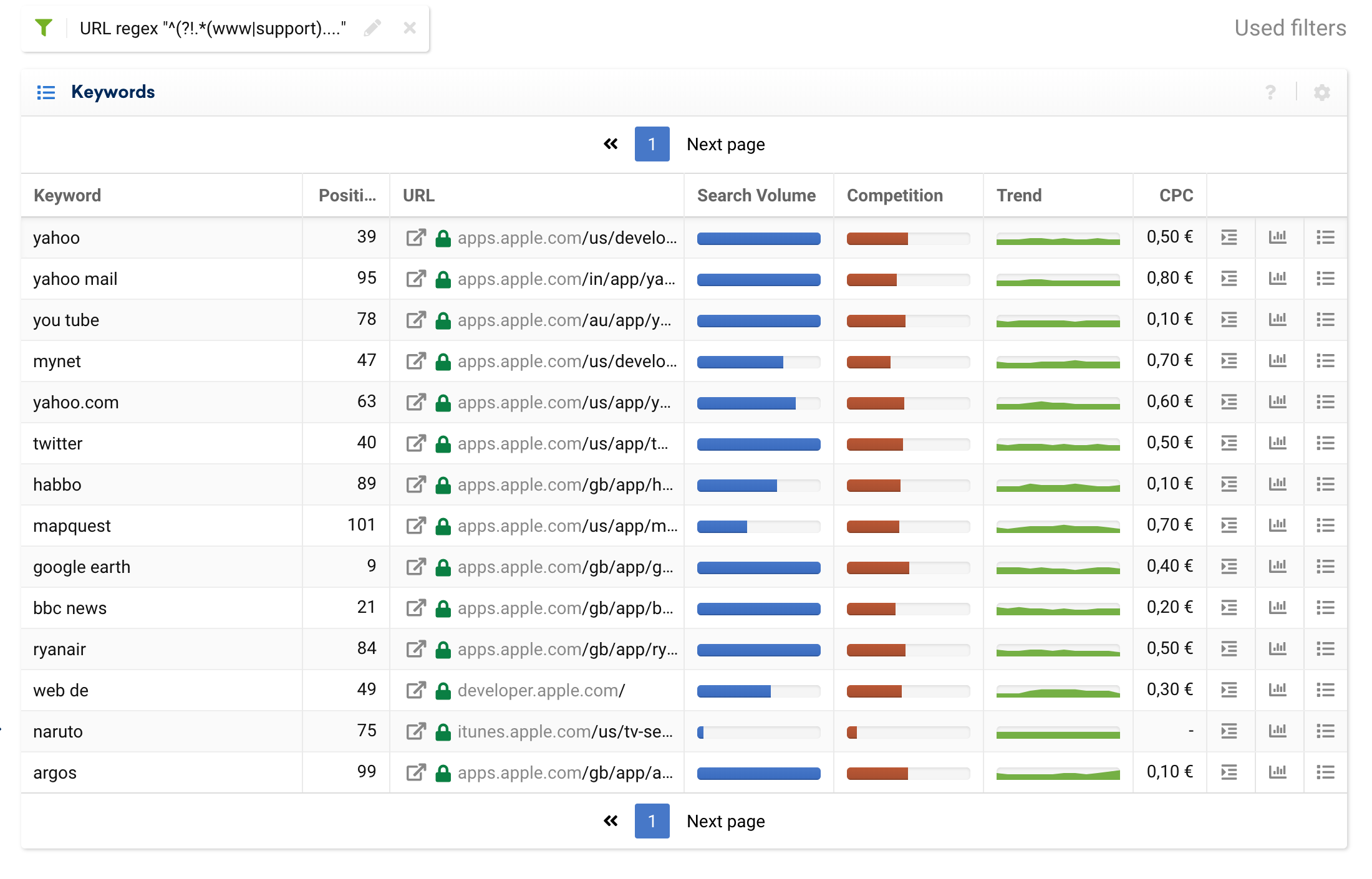
包括或排除以 / 結尾或不結尾的 URL
如果主頁的 .com 域以斜線結尾,則可以調整正則表達式以匹配:
^.*.com/$ ^(?!(.*.com/$))任何以 / 結尾的 URL
.*/$我們也可以將這個正則表達式用於 URL,專門關注以斜杠 (/) 結尾的 URL。 為此,在搜索欄 (1) 中輸入域,然後單擊導航中的 URL (2),添加過濾器 (3) 並選擇 URL 過濾器作為“正則表達式”(4):
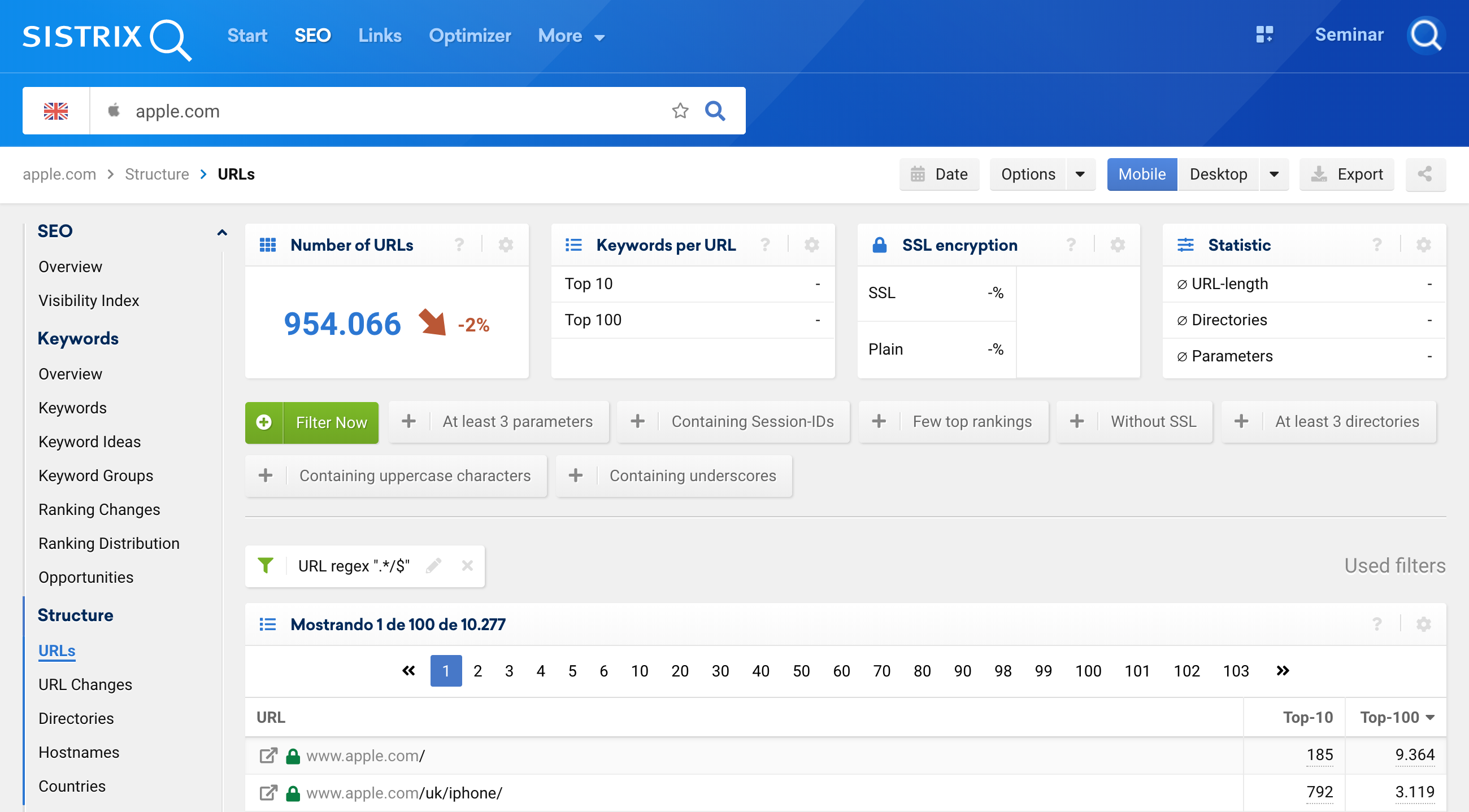
當然,這也適用於不以 / 結尾的 URL
^(?!(.*/$)) 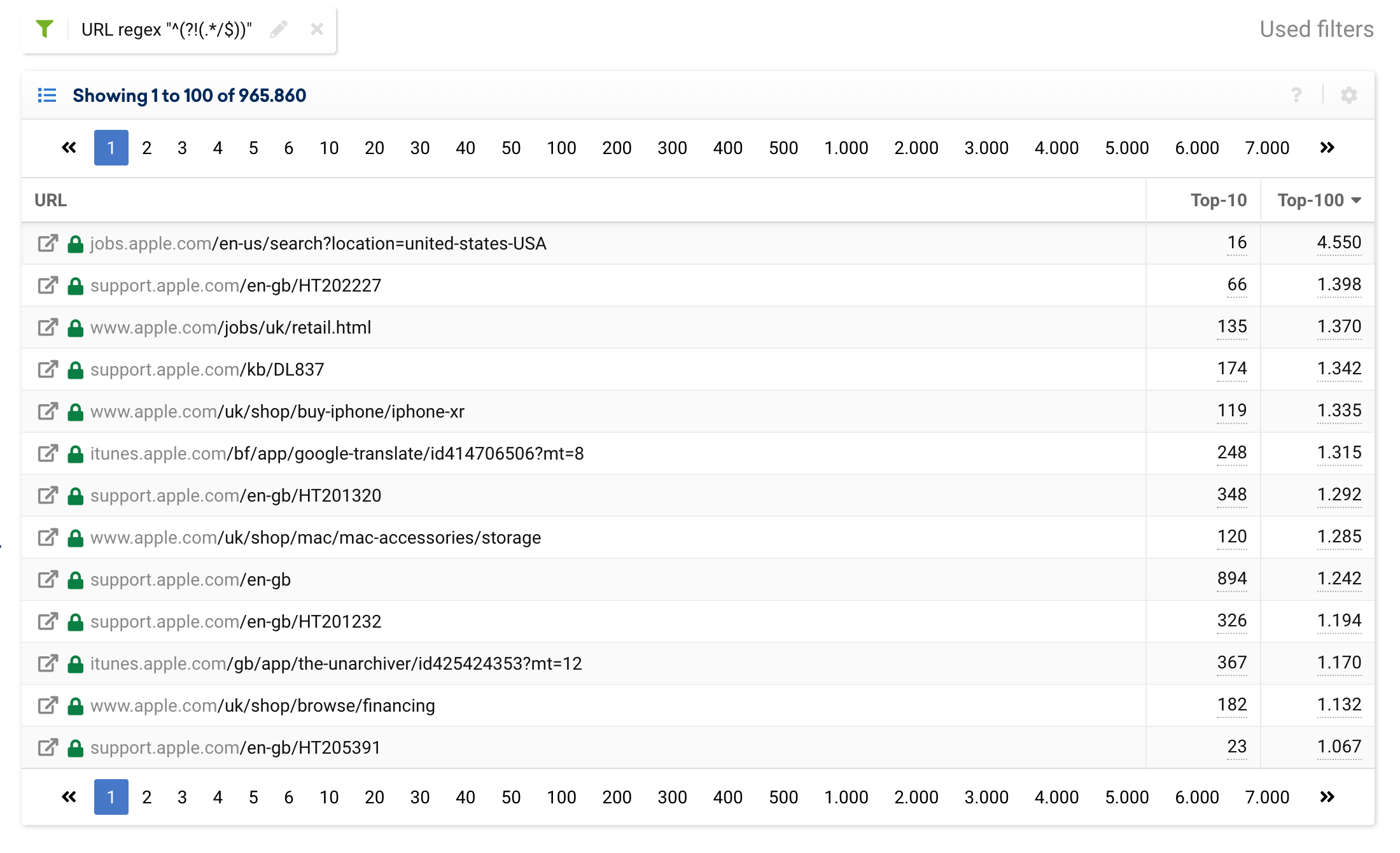
包括或排除包含數字的 URL
我們可以修改 URL 語法來識別哪些包含數字以包含或排除它們:
.*-[0-9].* ^(?!(.*-[0-9].*))如果我們想要更具體的東西,並且我們知道有以特定數字結尾的 URL,我們還可以包括或排除它們,如下所示:
.*-[0-9]+$ ^(?!(.*-[0-9]+$))在這種情況下,我們的請求是過濾包含 8 個連續數字系列的鏈。
.*[0-9]{8}.html$ ^(?!(.*[0-9]{8}.html$))包含或排除特定格式的 URL
我們也可以使用 Regex 過濾 URL 格式。 例如,htm 或 html URL,以及 pdf URL。
這相當容易,因為我們可以依靠“結束於”或“包含”過濾器來做到這一點。
.*htm.?$ .*pdf$要排除所需的 URL 格式:
^(?!(.*html.?$).) ^(?!(.*pdf.?$).)我們可以在同一個表達式中使用多種格式,這將更有價值,並且可以省去連接多個過濾器的麻煩,包括:
.*(htm|html)$ .*(jpg|jpeg|gif|png)$我們還可以組合要排除的格式:
^(?!(.*(htm|html)$).) ^(?!(.*htm.?)$).) ^(?!(.*(jpg|jpeg|gif|png)$).)包含或排除與錯誤市場相關的 URL
我們可以監控不應出現在特定市場結果中的 URL。 例如,與美國、墨西哥或德國市場相關的 URL 出現在西班牙語的結果中。
以以下 URL 實例為基礎:
西班牙的西班牙語 /es_es/
英國英語 /en_gb/
美國英語 /en_us/
意大利的意大利語 /it_it/
等等。
我們可以使用 Regex 來過濾不屬於西班牙市場的 URL 數量。
^(?!(.*[es]_[az].*)|(.*[az]_[es].*).) ![hm.com 的 SISTRIX 工具箱中的關鍵字表,應用了正則表達式過濾器“^(?!(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)” .](/uploads/article/246/TIPPU8qnSB57ontM.png)
如您所見,該表達式允許主頁 URL,即語言選擇器所在的位置。
為了進一步細化這個表達式並去掉主頁,我們可以擴展它,如下所示:
^(?!(.*.com/$)|(.*[es]_[az].*)|(.*[az]_[es].*).) ![hm.com 的 SISTRIX 工具箱中的關鍵字表,帶有正則表達式過濾器“^(?!(.*.com/$)|(.*[es]_[a-z].*)|(.*[a-z]_[ es].*).)”應用。](/uploads/article/246/vxYA4KacpOcflwYd.png)
概括
使用本文中提供的參數,您現在可以找到自己的用例,正則表達式可以派上用場,幫助您提高 SEO 分析效率。
您可以使用 https://www.Regextester.com/ 等工具或直接使用 SISTRIX 的 URL、關鍵字或片段過濾器繼續測試和練習。
儘管我們不提供對 Regex 的支持,但我們將繼續使用新的用例和 SEO 分析更新本教程,這些可能對您有用。