
كيفية استخدام التعبيرات العادية في Toolbox
نشرت: 2022-04-17- ما هو التعبير النمطي؟
- كيف يمكننا بناء التعبيرات النمطية؟
- أمثلة على تحسين محركات البحث مع التعبيرات العادية
- تصفية الكلمات الأساسية مع التعبيرات العادية
- تضمين أو استبعاد اسم العلامة التجارية
- قم بتضمين أو استبعاد الأخطاء في المصطلحات المتعلقة بالعلامة التجارية
- قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية التي تنتهي بكلمات محددة
- قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية بدءًا من كلمات محددة
- قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية المتعلقة بسمات معينة
- قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية التي تحتوي على أسماء المدن في United Kindgom
- تصفية عناوين URL مع التعبيرات العادية
- تضمين أو استبعاد المجالات الفرعية
- تضمين أو استبعاد عناوين URL التي تنتهي أو لا تنتهي بـ /
- تضمين أو استبعاد عناوين URL التي تحتوي على أرقام
- قم بتضمين أو استبعاد عناوين URL بتنسيق معين
- قم بتضمين أو استبعاد عناوين URL المتعلقة بالأسواق غير الصحيحة
- ملخص
ما هو التعبير النمطي؟
يتم استخدام التعبير العادي للتحقق أو التحقق من نمط. تطبيقهم الرئيسي هو تصفية العناصر وإيجاد التطابقات ، على سبيل المثال ، في السيناريوهات التالية:
- التحليلات: يمكنك استخدام Regex لتقسيم حركة المرور.
- Htaccess: يمكنك إعادة كتابة عناوين URL بطريقة أكثر فاعلية.
- SISTRIX: يمكنك تصفية تقاريرنا التي تحتوي على عناوين URL أو مقتطفات أو كلمات رئيسية.
يمكن استخدام التعبيرات العادية - أو Regex - في العديد من لغات البرمجة ، ولكن هذا البرنامج التعليمي سيعتمد على Perl ، حيث يستخدم المعيار الذي تستند إليه وظيفة SISTRIX Regex المتوفرة بالفعل .
كيف يمكننا بناء التعبيرات النمطية؟
سنقوم بذلك باستخدام الشخصيات والتجمعات والمحددات الكمية والفئات ، لأنها البنية التي من خلالها سنكون قادرين على بناء التعبيرات.
| الشخصيات | سلوك | مثال |
|---|---|---|
| ؟ | يبحث عن الحرف السابق 1 أو 0 مرة. | https؟ |
| * | يبحث عن الحرف السابق 0 أو أكثر من المرات. | 30 * |
| + | يبحث عن الحرف السابق 1 مرة أو أكثر. | [0-9] + |
| | | يبحث عن عنصر أو آخر. (أو) | (jpg | jpeg) |
| ^ | يشير إلى بداية النمط | ^ https |
| $ | يشير إلى نهاية النمط | html $ |
| · | يبحث عن أي حرف (wild card) | 4 .. |
| \ | لا يفسر حرفًا خاصًا (تخطي الأحرف) | \ / |
| التجمع | سلوك | مثال |
|---|---|---|
| () | يلتقط محتوى معين | (سيستريكس) مباريات sistrix |
| [] | يلتقط الأحرف بين قوسين | [0-9] يتطابق مع أي حرف رقمي [az] يتطابق مع أي حرف صغير |
| {} | يشير إلى عدد التكرارات ، الحد الأدنى أو الأقصى | . {1،3} يتطابق مع أي حرف يتكرر بين 1 و 3 مرات. |
في هذا البرنامج التعليمي ، لن نستخدم المحددات الكمية ، لكننا نعتقد أنه لا يزال من المثير للاهتمام أن تتعرف عليها في حالة استخدامها في بيئات أخرى.
| محددو الكمية | سلوك |
|---|---|
| \ w | يبحث عن كلمة أو رقم أو _ نوع الحرف |
| \د | يبحث عن حرف رقم |
| \س | يبحث عن حرف مسافة بيضاء |
| \ب | المطابقات تبدأ أو نهاية الكلمة |
| \ دبليو | يبحث عن حرف ليس كلمة أو رقمًا أو _ |
| \د | يبحث عن حرف ليس رقمًا |
| \س | يبحث عن حرف ليس مسافة بيضاء. |
أمثلة على تحسين محركات البحث مع التعبيرات العادية
لتتمكن من استخدام الأمثلة المقترحة ، تحتاج إلى الانتقال إلى قسم "الكلمات الرئيسية" واستخدام عوامل تصفية الكلمات الرئيسية أو عنوان URL أو العنوان أو الوصف.
تصفية الكلمات الأساسية مع التعبيرات العادية
للوصول إلى هذه الميزة ، ما عليك سوى تحليل المجال 1 والانتقال إلى الكلمات الرئيسية 2 ، ثم الانتقال إلى تحديد عامل التصفية 3
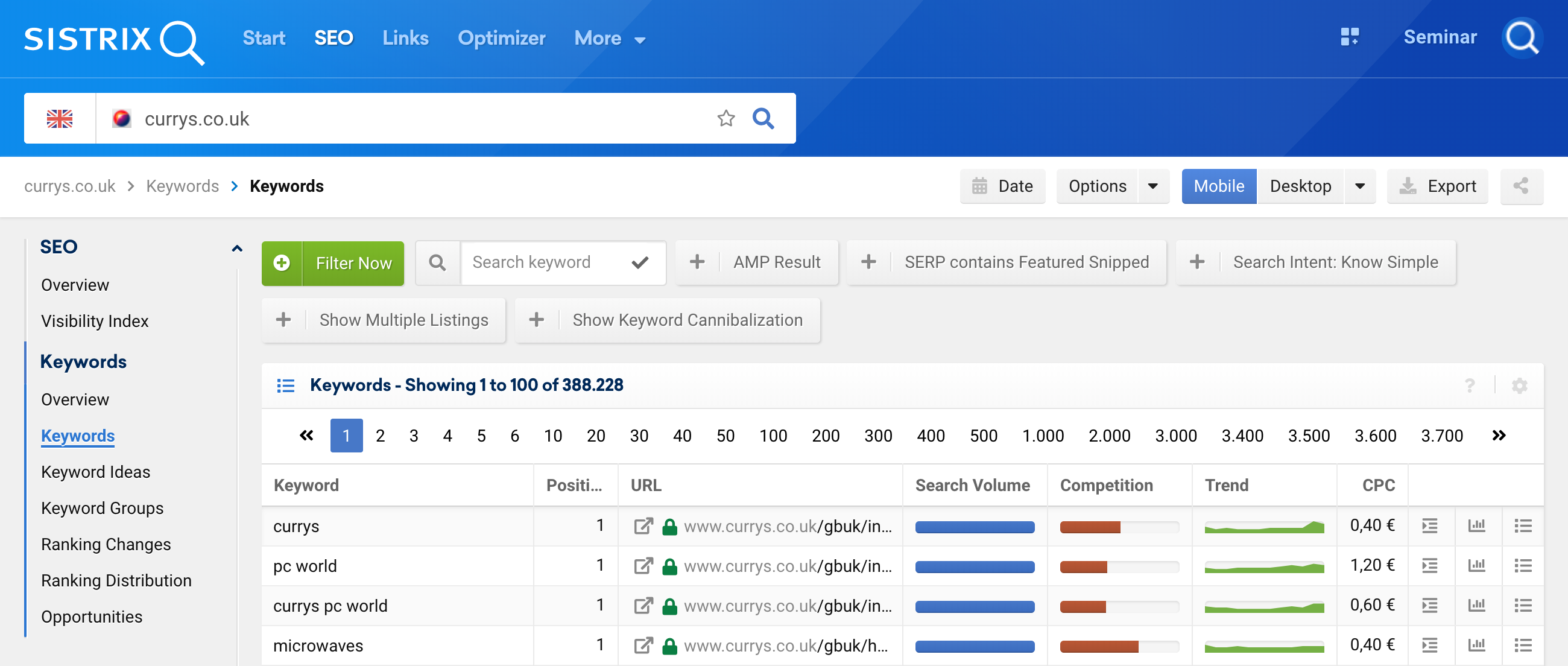
وبعد ذلك ، استخدم مرشح الكلمات الرئيسية مع Regex 4 .
نود الآن اقتراح العديد من حالات الاستخدام حيث يمكنك تطبيق هذه التعبيرات لتحقيق أقصى استفادة من تحليل الكلمات الرئيسية لمشاريعك ، أو عند تحليل منافسيك.
تضمين أو استبعاد اسم العلامة التجارية
تخيل أن لديك علامة تجارية تقبل تهجئات مختلفة أو تعرف بعدة أسماء تجارية مختلفة. يمكننا إنشاء تعبير عادي لتجميع كل الكلمات الرئيسية التي نعتبرها مصطلحات ذات علامة تجارية. على سبيل المثال ، يحتوي currys.co.uk على العديد من الكلمات الرئيسية ذات العلامات التجارية ، وهي:
كاري ، كاري ، عالم الكمبيوتر
وبالتالي ، سوف نستخدم التعبير التالي:
(curry|currys|pc world).* 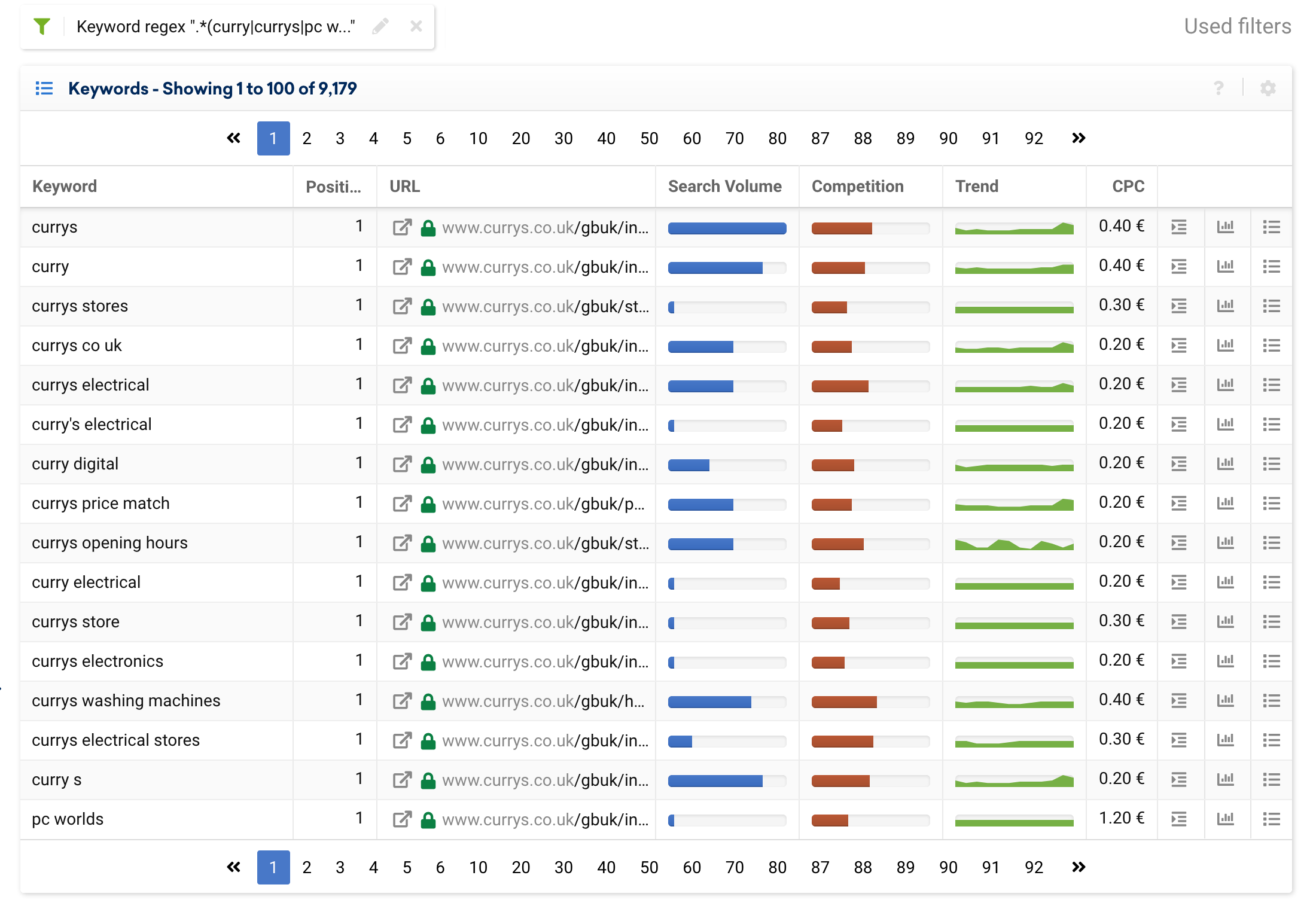
أدناه يمكنك رؤية النتائج التي سنحصل عليها:
من الممكن أيضًا تعيين عامل التصفية لاستبعاد الكلمات الرئيسية ذات العلامات التجارية ، باستخدام التعبير التالي ، وسيعرض الكلمات الرئيسية العامة فقط:
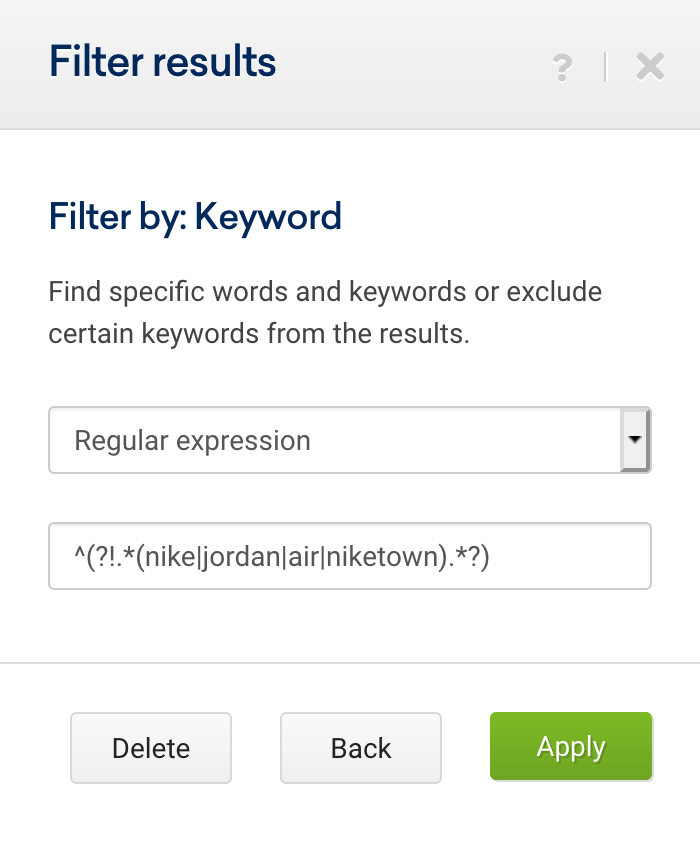
^(?!.*(curry|currys|pc world).*?) 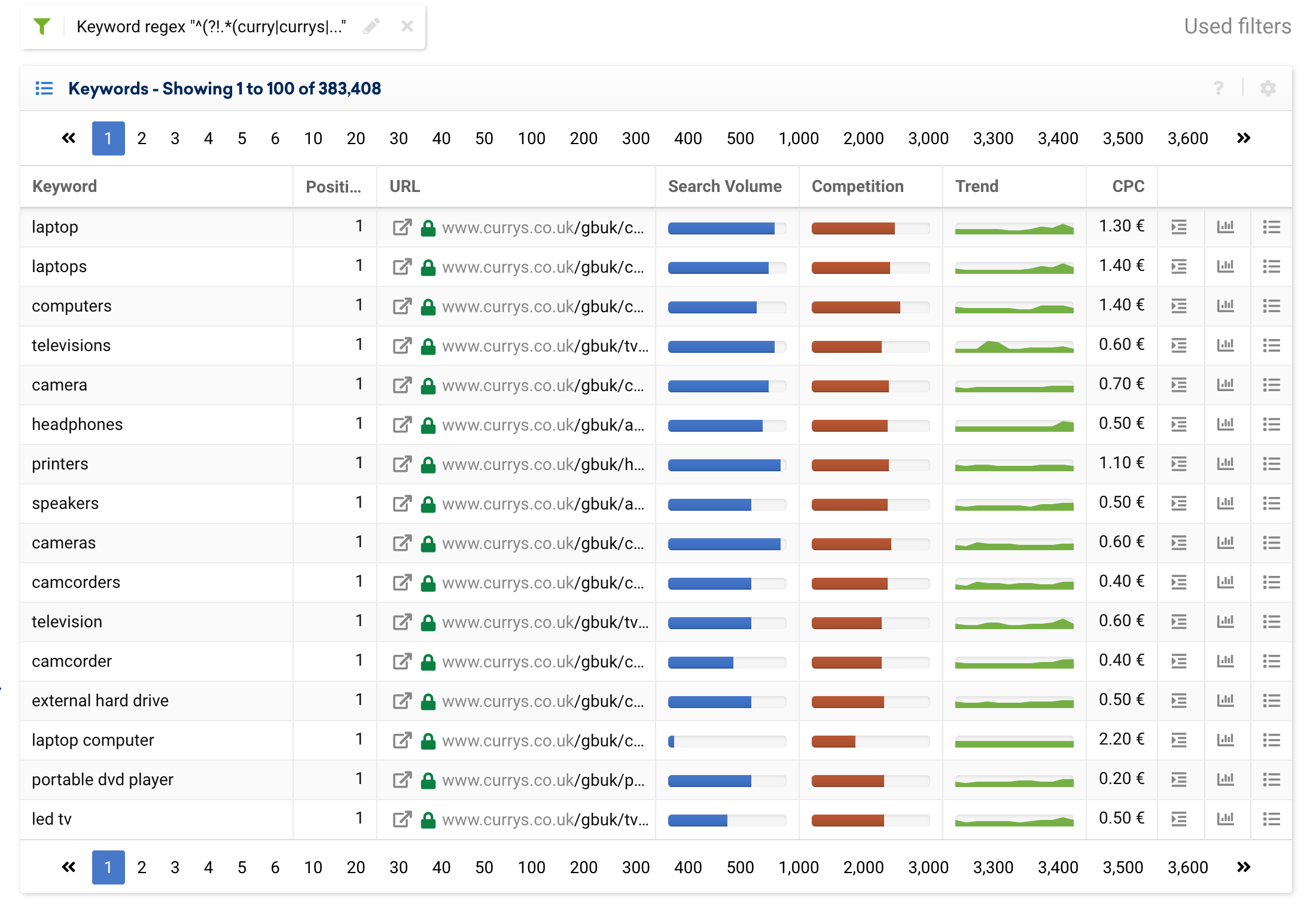
قم بتضمين أو استبعاد الأخطاء في المصطلحات المتعلقة بالعلامة التجارية
هناك احتمال أن نواجه علامات تجارية غالبًا ما تكون بها أخطاء إملائية أو مكتوبة بها أخطاء ، مثل Ryanair.
فيما يلي بعض الأمثلة على المصطلحات التي يدخلها المستخدمون للبحث عن شركة الطيران هذه:
- ريان اير
- رايانر
- ريان الأشعة تحت الحمراء
- ريان الأشعة تحت الحمراء
- ريانة اير
- ريا نير
- ريان اري
- هواء رايار
لقد حددنا أكثر من 35 اسمًا تجاريًا يمكننا التقاطها باستخدام تعبير عادي واحد فقط:
لتضمين جميع أنواع العلامات التجارية:
(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)? ![جدول الكلمات الرئيسية في SISTRIX Toolbox for ryanair.com مع مرشح regex ". (r | t) [hzeuayi]؟ [naiy].؟ [an]؟ [airn].؟ (r | t | air)؟ (e | خطوط |)؟ (خط | ir)؟ " مُطبَّق.](/uploads/article/246/J4RlqK5XMR1iRPm6.png)
لاستبعاد جميع أنواع العلامات التجارية:
^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$ ![جدول الكلمات الرئيسية في SISTRIX Toolbox for ryanair.com مع مرشح regex "^ ((؟! (r | t) [hzeuayi]؟ [naiy].؟ [an]؟ [airn].؟ (r | t | air) ؟ (e | lines |)؟ (line | ir)؟).) * $ "تم تطبيقه.](/uploads/article/246/x8B4lxmc6Vmja5ch.png)
بالطبع لا يزال بإمكاننا تطبيق عوامل تصفية أخرى على هذه القائمة ، مثل "يحتوي على" أو "لا يحتوي على" أو "ينتهي بـ" أو "يبدأ بـ".
قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية التي تنتهي بكلمات محددة
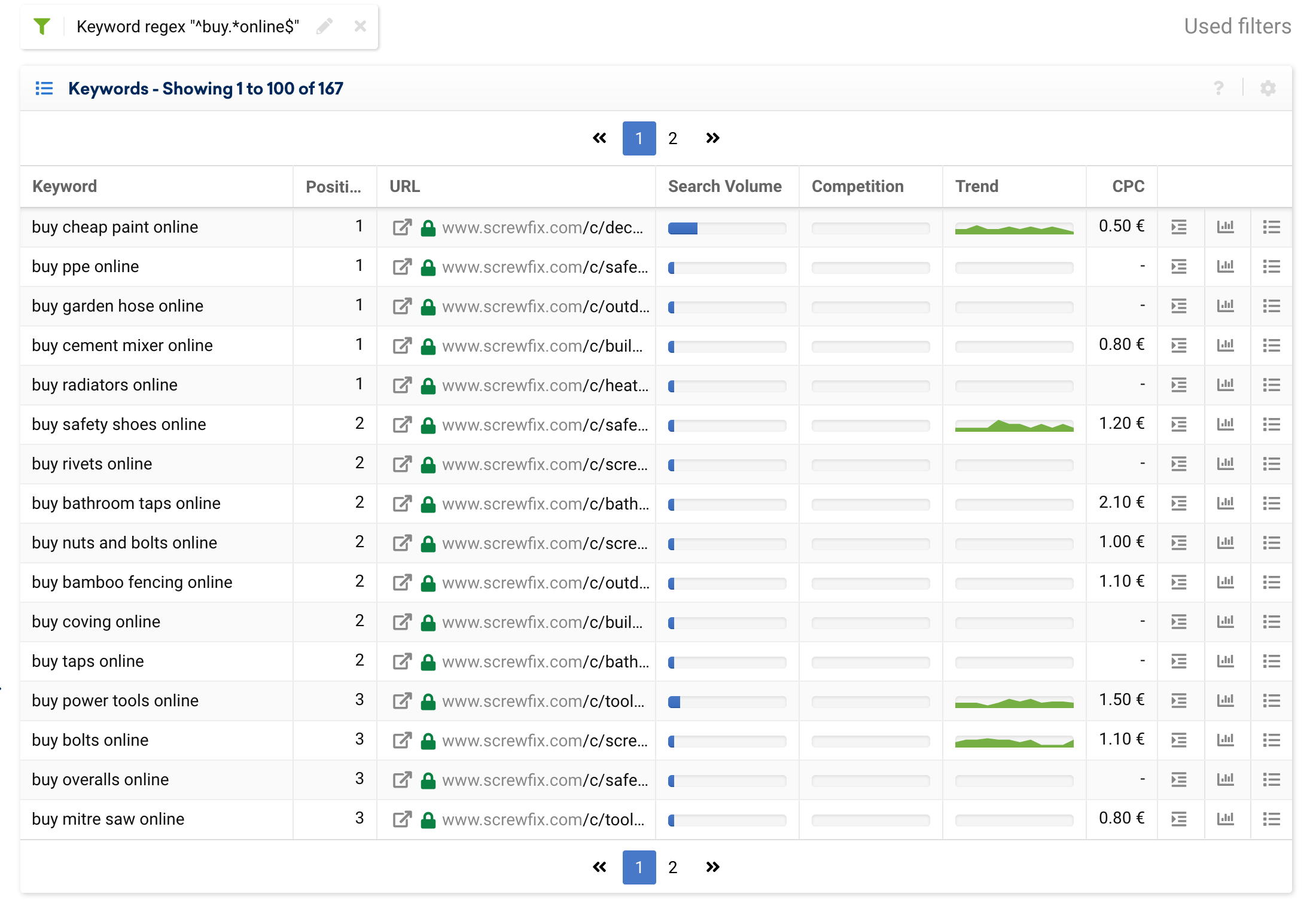
للبحث عن كلمة رئيسية فريدة ، يكفي استخدام مرشح بسيط ، ولكن إذا أردنا إجراء بحث بعدة شروط ، على سبيل المثال: جميع الكلمات الرئيسية التي تبدأ بـ "شراء" وتنتهي بـ "عبر الإنترنت" ، فيمكننا استخدام:
^buy.*online$هذا ، عند تطبيقه على متجر عبر الإنترنت مثل screwfix.com ، سيعرض النتائج التالية:
قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية بدءًا من كلمات محددة
من وجهة نظر أداة المقارنة ، قد يكون من المثير للاهتمام أن تكون قادرًا على تصفية الكلمات الرئيسية التي تحتوي على أسماء تجارية مختلفة.
على سبيل المثال ، يمكننا إنشاء تعبير عادي يقوم بتجميع المصطلحات بناءً على المعايير التي نريدها ، وهي في هذه الحالة ، أي مصطلح كلمة رئيسية يبدأ بأي اسم علامة تجارية مضمن داخل الأقواس:

^(sony|panasonic|philips|samsung).*وبالمثل ، يمكننا استخدامه لاستبعادهم:
^(?!(sony|panasonic|philips|samsung).*)قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية المتعلقة بسمات معينة
لنجرب هذا بمثال على سمة شائعة في العديد من المشاريع: السعر.
هناك العديد من طلبات البحث التي تشير إلى السعر ، مثل: "رخيص" ، "خصم" ، "منفذ" ، "قسيمة" ، "عرض" ، "تكلفة منخفضة" ، "ميزانية" ، إلخ.
إذا أردنا استبعادها من النتائج ، فيمكننا استخدام التعبير التالي:
.*(cheap|budget|offer|outlet|price).* 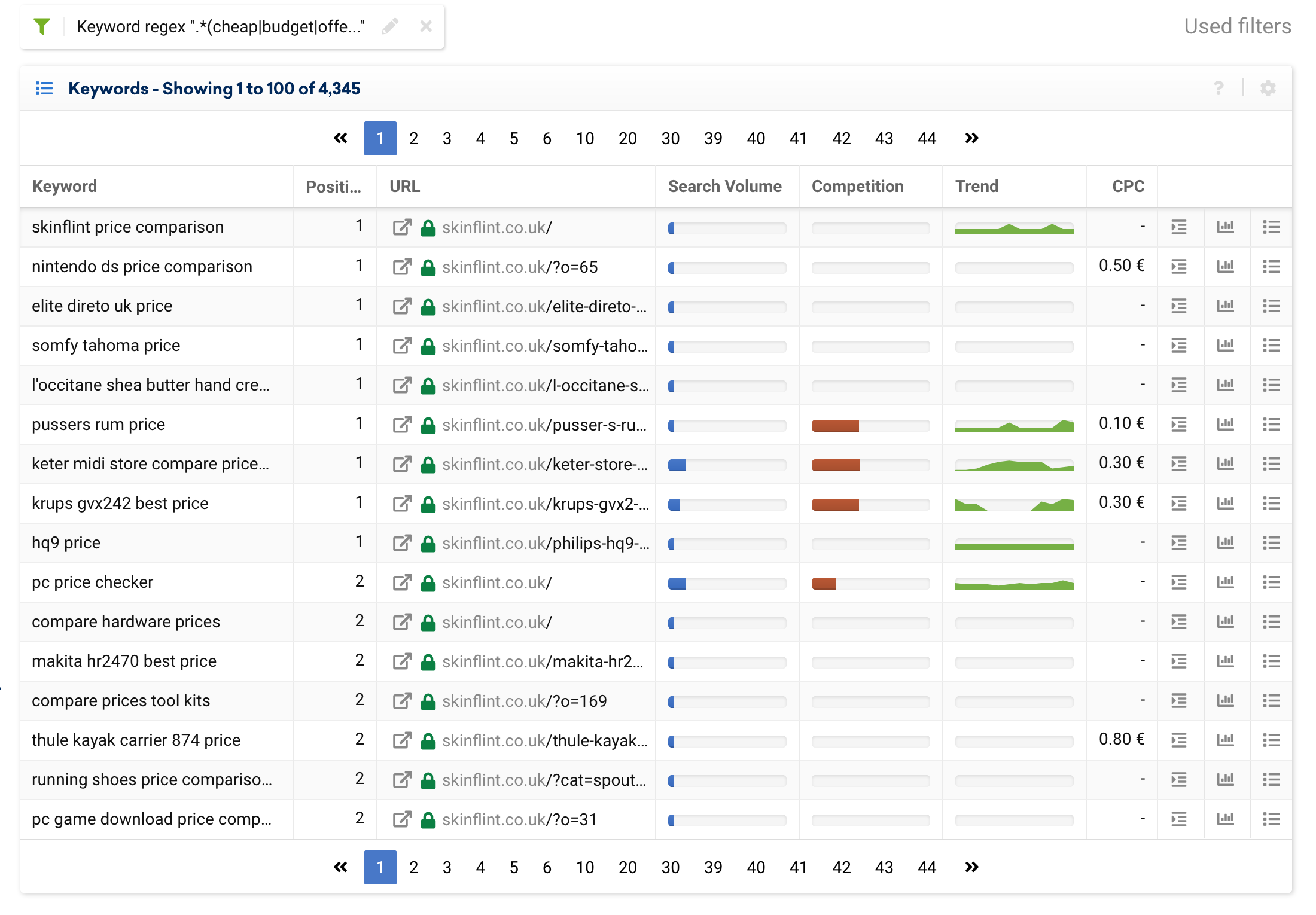
باستخدام الأعمدة الديناميكية للجدول ، يمكننا تنظيم البيانات حسب حجم البحث بترتيب تنازلي ، بمجرد النقر فوق رأس العمود.
في حالات أخرى ، يمكننا أيضًا استخدام سمات أخرى مثل الألوان والأشكال والأحجام والهدف وما إلى ذلك.
قم بتضمين أو استبعاد مصطلحات الكلمات الرئيسية التي تحتوي على أسماء المدن في United Kindgom
تتطلب العديد من المشاريع تتبع التواجد المحلي. للقيام بذلك ، يمكننا استخدام Regex لتجميع المقاطعات والمناطق والمدن والبلدات ، إلخ.
في هذا المثال ، سنأخذ قائمة المدن لبناء تعبير عادي يقوم بتصفية مصطلحات الكلمات الرئيسية التي تحتوي على مدينة.
.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*يمكن لأي عمل تجاري إلكتروني أو أداة مقارنة ذات حضور مادي استخدام هذا التعبير لاستبعاد مدن ، وحتى إضافة كلمات رئيسية ذات علامة تجارية أو استبعاد معلمات أخرى.
^(?!(.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*))ومع ذلك ، يمكننا أيضًا فصلها في عدة تعبيرات ، كما هو موضح أدناه:
من الآن فصاعدًا نضيف عامل تصفية الخبراء للإشارة إلى أن هذين التعبيرين من النوع "و" ، بدلاً من النوع "أو".
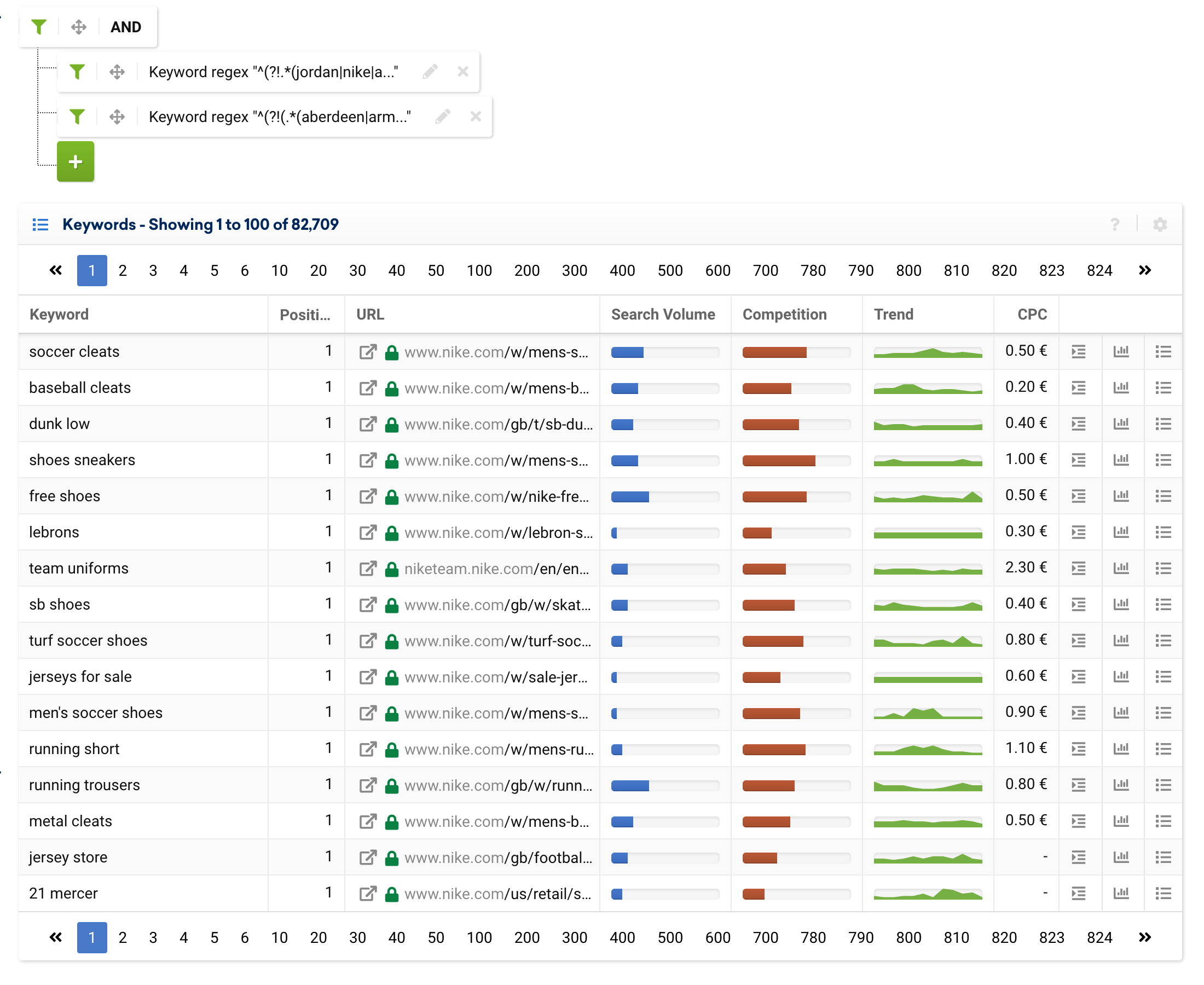
تصفية عناوين URL مع التعبيرات العادية
الخطوات التي يتعين عليك اتباعها لتصفية عناوين URL هي نفسها تلك التي اكتشفناها للكلمات الرئيسية ، والفرق الوحيد هو أنه سيتعين عليك تحديد "عناوين URL" ثم التعبيرات العادية.
تضمين أو استبعاد المجالات الفرعية
الآن بعد أن تعلمنا كيفية استخدام التعبيرات العادية لتصفية الكلمات الرئيسية ، فلنجد بعض حالات استخدام مُحسنات محركات البحث النموذجية التي نحتاج فيها إلى تصفية عناوين URL.
فيما يلي بعض حالات الاستخدام الأساسية لتحليل مجال بأكمله وتجميع عناوين URL حسب النطاقات الفرعية الإستراتيجية:
(www|support) 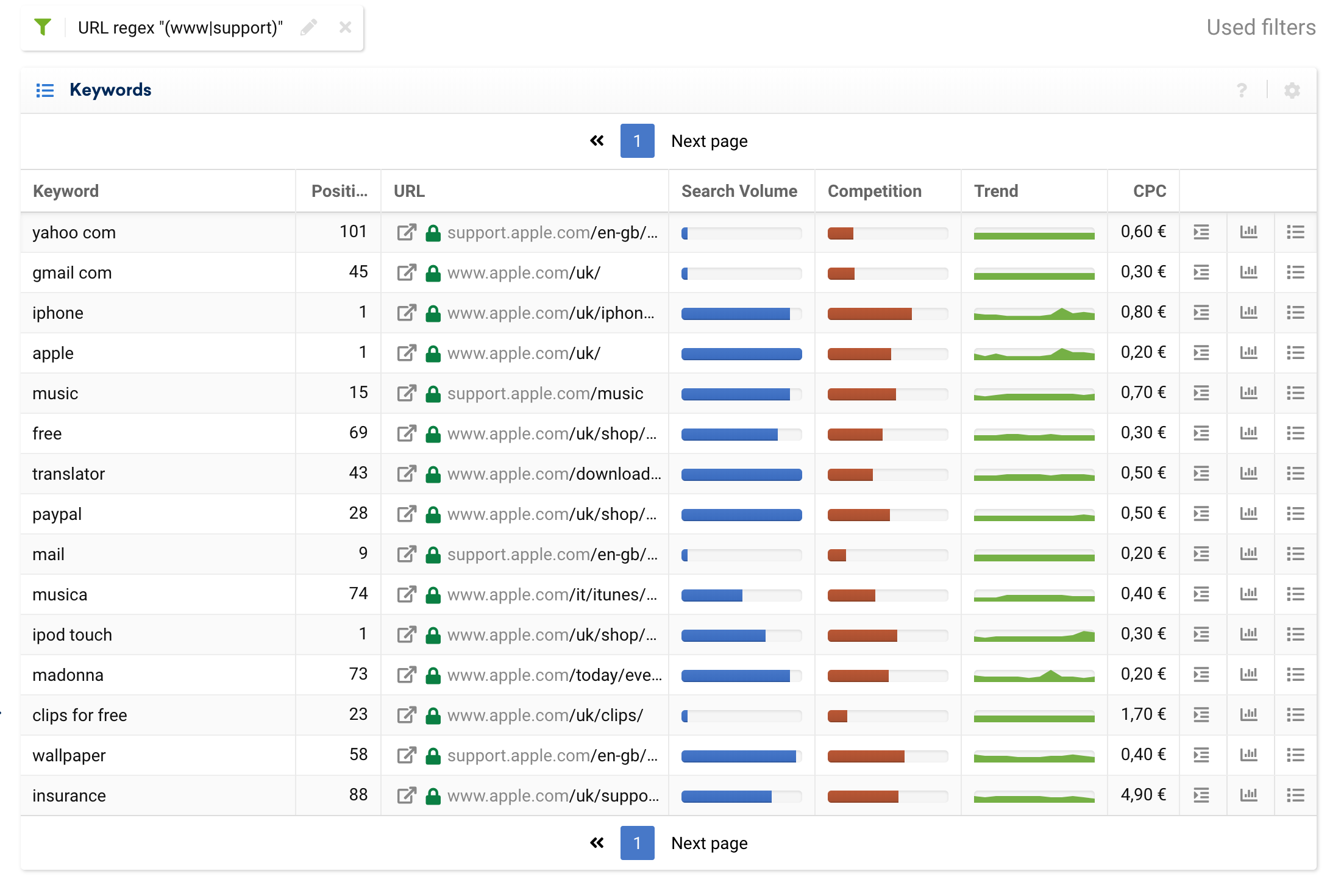
يمكننا استخدام عامل تصفية الاستبعاد ، على سبيل المثال ، لفصل النطاقات الفرعية للمعاملات البحتة ، وترك الكلمات الرئيسية الإعلامية الواردة من المدونات أو الأسئلة الشائعة.
^^(?!.*(www|support).*?) 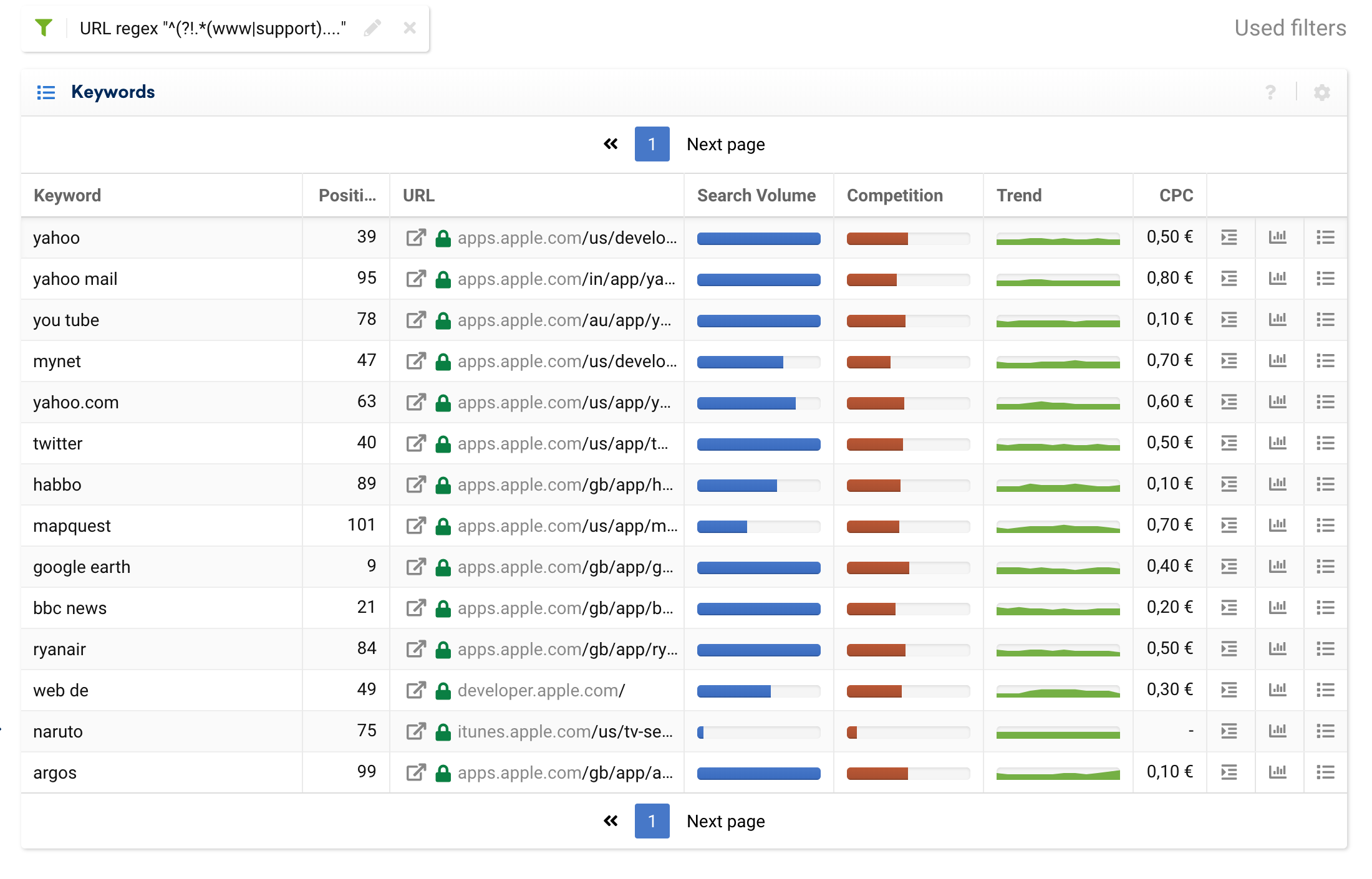
تضمين أو استبعاد عناوين URL التي تنتهي أو لا تنتهي بـ /
إذا انتهى نطاق .com للصفحة الرئيسية بشرطة مائلة ، فيمكن تكييف regex لمطابقة:
^.*.com/$ ^(?!(.*.com/$))أي عنوان URL ينتهي بـ /
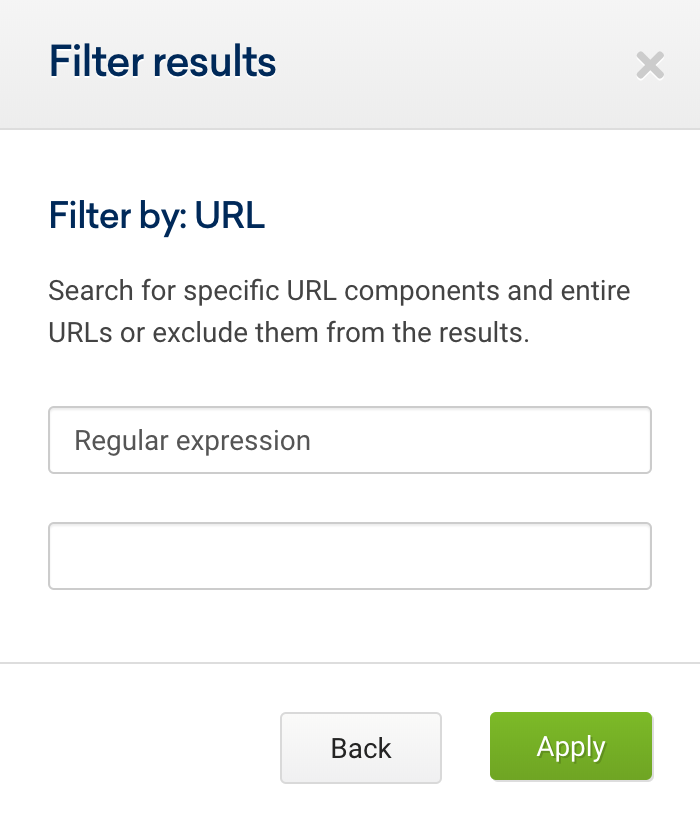
.*/$يمكننا أيضًا استخدام Regex لعناوين URL للتركيز حصريًا على عناوين URL التي تنتهي بشرطة مائلة (/). للقيام بذلك ، أدخل المجال في شريط البحث (1) ، ثم انقر فوق عناوين URL في شريط التنقل (2) ، وأضف عامل تصفية (3) واختر مرشح URL كـ "تعبير عادي" (4):
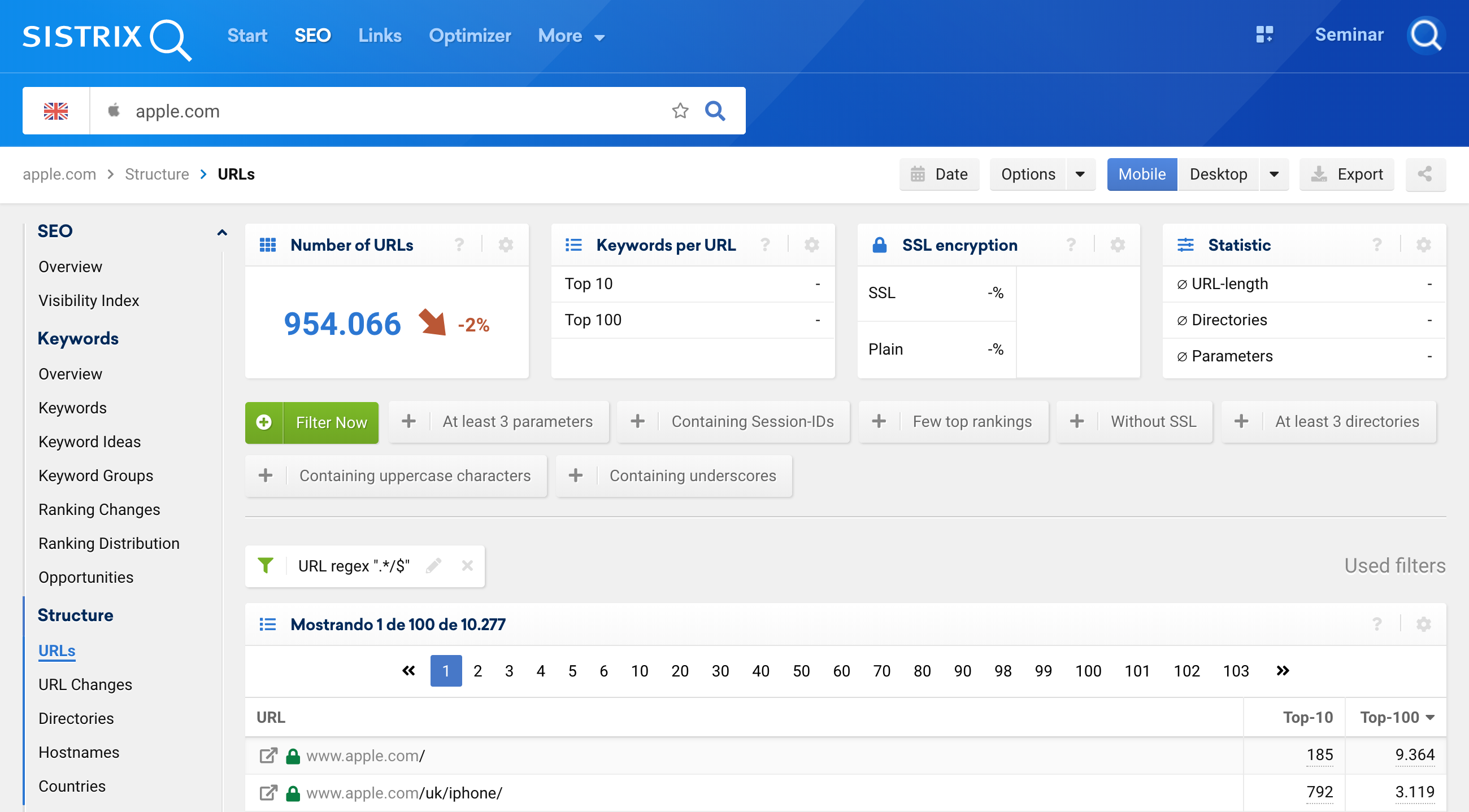
بالطبع ، يعمل هذا أيضًا مع عناوين URL التي لا تنتهي بـ /
^(?!(.*/$)) 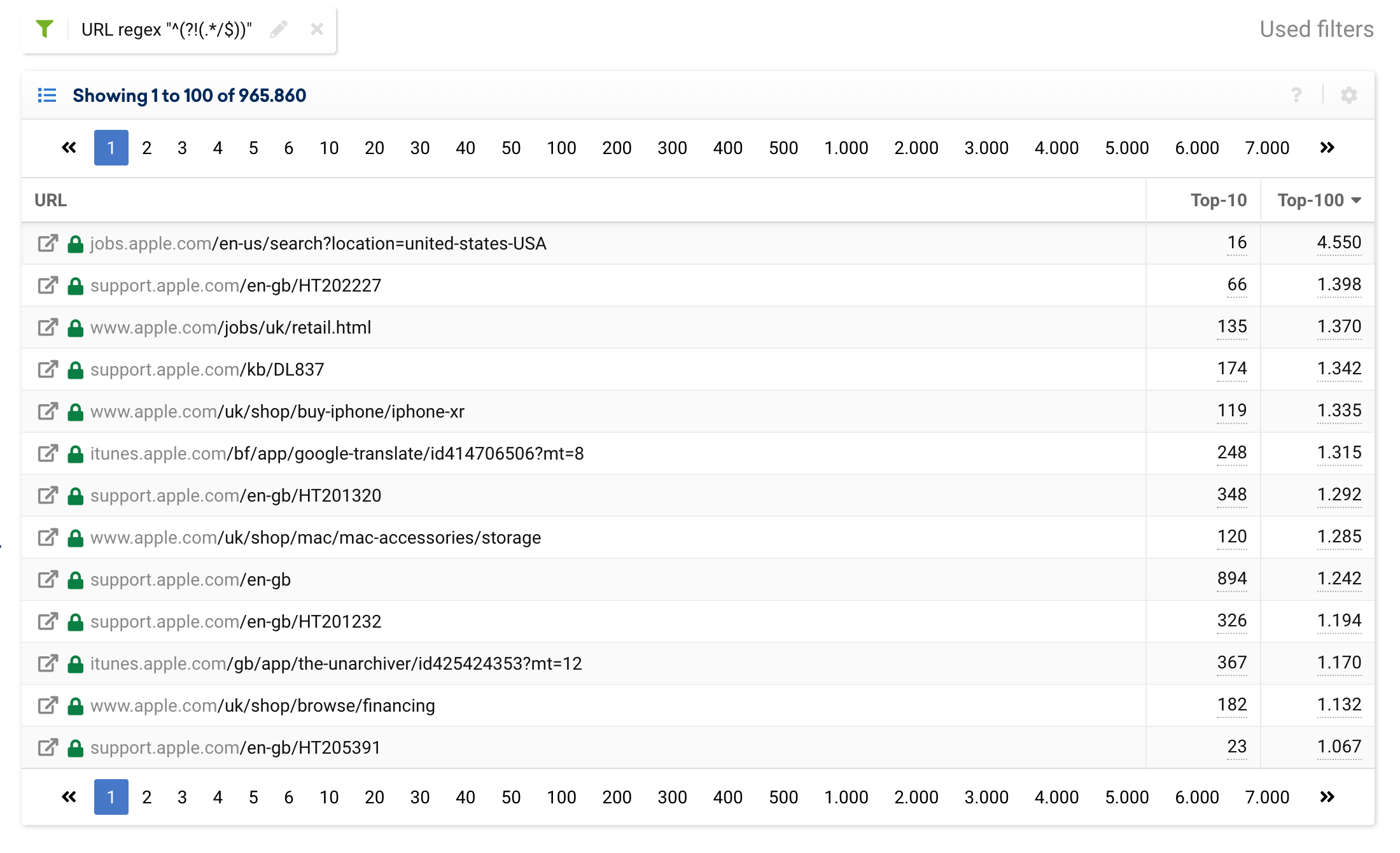
تضمين أو استبعاد عناوين URL التي تحتوي على أرقام
يمكننا العبث ببنية عنوان URL لتحديد تلك التي تحتوي على أرقام لتضمينها أو استبعادها:
.*-[0-9].* ^(?!(.*-[0-9].*))إذا أردنا شيئًا أكثر تحديدًا ، وعرفنا أن هناك عناوين URL تنتهي برقم معين ، فيمكننا أيضًا تضمينها أو استبعادها على النحو التالي:
.*-[0-9]+$ ^(?!(.*-[0-9]+$))في هذه الحالة ، كان طلبنا هو تصفية السلاسل التي تحتوي على سلسلة من 8 أرقام متتالية.
.*[0-9]{8}.html$ ^(?!(.*[0-9]{8}.html$))قم بتضمين أو استبعاد عناوين URL بتنسيق معين
يمكننا استخدام Regex لتصفية تنسيقات عناوين URL أيضًا. على سبيل المثال ، عناوين URL بتنسيق htm أو html ، بالإضافة إلى عناوين pdf.
هذا سهل إلى حد ما ، حيث يمكننا الاعتماد على عوامل تصفية "ينتهي بـ" أو "يحتوي على" للقيام بذلك.
.*htm.?$ .*pdf$لاستبعاد تنسيقات URL المطلوبة:
^(?!(.*html.?$).) ^(?!(.*pdf.?$).)يمكننا استخدام العديد من التنسيقات في نفس التعبير ، والتي ستكون أكثر قيمة ، وستوفر علينا متاعب ربط العديد من الفلاتر ، لتشمل:
.*(htm|html)$ .*(jpg|jpeg|gif|png)$ويمكننا أيضًا دمج التنسيقات لاستبعادها:
^(?!(.*(htm|html)$).) ^(?!(.*htm.?)$).) ^(?!(.*(jpg|jpeg|gif|png)$).)قم بتضمين أو استبعاد عناوين URL المتعلقة بالأسواق غير الصحيحة
يمكننا مراقبة عناوين URL التي لا ينبغي أن تظهر في نتائج سوق معين. على سبيل المثال ، عناوين URL المتعلقة بالولايات المتحدة أو المكسيك أو الأسواق الألمانية التي تظهر في نتائج السوق الإسبانية.
أخذ مثيلات URL التالية كأساس لنا:
الإسبانية الإسبانية / es_es /
الإنجليزية البريطانية / en_gb /
الإنجليزية الأمريكية / en_us /
الإيطالي الإيطالي / it_it /
وهلم جرا.
يمكننا استخدام Regex لتصفية عدد عناوين URL التي لا تنتمي إلى السوق الإسبانية.
^(?!(.*[es]_[az].*)|(.*[az]_[es].*).) ![تم تطبيق جدول الكلمات الرئيسية في SISTRIX Toolbox for hm.com مع عامل تصفية regex "^ (؟! (. * [es] _ [a-z]. *) | (. * [a-z] _ [es]. *).)" .](/uploads/article/246/TIPPU8qnSB57ontM.png)
كما ترى ، يسمح التعبير بعنوان URL للصفحة الرئيسية ، حيث يوجد محدد اللغة.
لتنقيح هذا التعبير بشكل أكبر وترك الصفحة الرئيسية خارجًا ، يمكننا توسيعه كما هو موضح أدناه:
^(?!(.*.com/$)|(.*[es]_[az].*)|(.*[az]_[es].*).) ![جدول الكلمات الرئيسية في SISTRIX Toolbox for hm.com مع عامل تصفية regex "^ (؟! (. *. com / $) | (. * [es] _ [a-z]. *) | (. * [a-z] _ [ es]. *).) "تطبيق.](/uploads/article/246/vxYA4KacpOcflwYd.png)
ملخص
باستخدام المعلمات الواردة في هذا المنشور ، يمكنك الآن العثور على حالات الاستخدام الخاصة بك حيث يمكن أن تكون التعبيرات العادية في متناول اليد وتساعدك على جعل تحليلات تحسين محركات البحث الخاصة بك أكثر كفاءة.
يمكنك الاستمرار في الاختبار والممارسة باستخدام أدوات مثل https://www.Regextester.com/ ، أو مباشرةً باستخدام عوامل تصفية عنوان URL أو الكلمات الرئيسية أو المقتطفات الخاصة بـ SISTRIX.
على الرغم من أننا لا نقدم دعمًا لـ Regex ، إلا أننا سنواصل تحديث هذا البرنامج التعليمي بحالات استخدام جديدة وتحليلات تحسين محركات البحث التي قد تكون مفيدة لك.