
วิธีใช้นิพจน์ทั่วไปในกล่องเครื่องมือ
เผยแพร่แล้ว: 2022-04-17- นิพจน์ทั่วไปคืออะไร?
- เราจะสร้างนิพจน์ทั่วไปได้อย่างไร
- ตัวอย่าง SEO พร้อมนิพจน์ทั่วไป
- การกรองคำหลักด้วยนิพจน์ทั่วไป
- รวมหรือยกเว้นชื่อแบรนด์
- รวมหรือยกเว้นข้อผิดพลาดในเงื่อนไขของแบรนด์
- รวมหรือยกเว้นคำสำคัญที่ลงท้ายด้วยคำเฉพาะ
- รวมหรือยกเว้นคำสำคัญที่ขึ้นต้นด้วยคำเฉพาะ
- รวมหรือยกเว้นคำสำคัญที่เกี่ยวข้องกับคุณลักษณะเฉพาะ
- รวมหรือยกเว้นคำสำคัญที่มีชื่อของเมืองใน United Kindgom
- การกรอง URL ด้วยนิพจน์ทั่วไป
- รวมหรือยกเว้นโดเมนย่อย
- รวมหรือยกเว้น URL ที่ลงท้ายหรือไม่ลงท้ายด้วย /
- รวมหรือยกเว้น URL ที่มีตัวเลข
- รวมหรือยกเว้น URL ในรูปแบบเฉพาะ
- รวมหรือยกเว้น URL ที่เกี่ยวข้องกับตลาดที่ไม่ถูกต้อง
- สรุป
นิพจน์ทั่วไปคืออะไร?
นิพจน์ทั่วไปใช้เพื่อตรวจสอบหรือตรวจสอบรูปแบบ แอปพลิเคชันหลักของพวกเขาใช้สำหรับกรององค์ประกอบและค้นหารายการที่ตรงกัน ตัวอย่างเช่น ในสถานการณ์ต่อไปนี้:
- Analytics: คุณสามารถใช้ Regex เพื่อแบ่งกลุ่มการเข้าชม
- Htaccess: คุณสามารถเขียน URL ใหม่ได้อย่างมีประสิทธิภาพมากขึ้น
- SISTRIX: คุณสามารถกรองรายงานของเราที่มี URL ตัวอย่างหรือคำหลัก
นิพจน์ทั่วไป –หรือ Regex– สามารถใช้ได้ในภาษาการเขียนโปรแกรมหลายภาษา แต่บทช่วยสอนนี้จะใช้ Perl เนื่องจากใช้มาตรฐานที่ ใช้ฟังก์ชัน SISTRIX Regex ที่มีอยู่แล้ว
เราจะสร้างนิพจน์ทั่วไปได้อย่างไร
เราจะทำสิ่งนี้โดยใช้อักขระ การจัดกลุ่ม ปริมาณ และคลาส เนื่องจากเป็นไวยากรณ์ที่เราจะสามารถสร้างนิพจน์ได้
| ตัวละคร | พฤติกรรม | ตัวอย่าง |
|---|---|---|
| ? | ค้นหาอักขระนำหน้า 1 หรือ 0 ครั้ง | https? |
| * | ค้นหาอักขระนำหน้า 0 ครั้งขึ้นไป | 30* |
| + | ค้นหาอักขระนำหน้า 1 ครั้งขึ้นไป | [0-9]+ |
| | | ค้นหาองค์ประกอบอย่างใดอย่างหนึ่ง (หรือ) | (jpg|jpeg) |
| ^ | ระบุจุดเริ่มต้นของรูปแบบ | ^https |
| $ | ระบุจุดสิ้นสุดของรูปแบบ | html$ |
| · | ค้นหาตัวละครใด ๆ (ไวด์การ์ด) | 4.. |
| \ | ไม่ตีความอักขระพิเศษ (ข้ามอักขระ) | \/ |
| การจัดกลุ่ม | พฤติกรรม | ตัวอย่าง |
|---|---|---|
| () | จับเนื้อหาเฉพาะ | (ซิสทริกซ์) ตรงกับ sistrix |
| [] | จับตัวอักษรภายในวงเล็บ | [0-9] ตรงกับอักขระตัวเลขใด ๆ [az] ตรงกับอักษรตัวพิมพ์เล็ก |
| {} | ระบุจำนวนการวนซ้ำ ต่ำสุดหรือสูงสุด | .{1,3} จับคู่กับอักขระใดๆ ที่ทำซ้ำระหว่าง 1 ถึง 3 ครั้ง |
ในบทช่วยสอนนี้ เราจะไม่ใช้ตัวระบุปริมาณ แต่เราคิดว่ายังคงน่าสนใจสำหรับคุณที่จะทำความคุ้นเคยกับตัววัดเหล่านี้ ในกรณีที่คุณใช้ในสภาพแวดล้อมอื่นๆ
| ปริมาณ | พฤติกรรม |
|---|---|
| \w | ค้นหาคำ ตัวเลข หรือ _ ประเภทอักขระ |
| \d | มองหาตัวอักษร |
| \s | มองหาอักขระช่องว่าง |
| \b | จับคู่จุดเริ่มต้นหรือจุดสิ้นสุดของคำ |
| \W | ค้นหาอักขระที่ไม่ใช่คำ ตัวเลข หรือ _ |
| \D | มองหาอักขระที่ไม่ใช่ตัวเลข |
| \S | มองหาตัวละครที่ไม่ใช่ช่องว่าง |
ตัวอย่าง SEO พร้อมนิพจน์ทั่วไป
เพื่อให้สามารถใช้ตัวอย่างที่แนะนำได้ คุณต้องไปที่ส่วน 'คำหลัก' และใช้ตัวกรองคำหลัก, URL, ชื่อหรือคำอธิบาย
การกรองคำหลักด้วยนิพจน์ทั่วไป
ในการเข้าถึงคุณลักษณะนี้ คุณจะต้องวิเคราะห์โดเมน 1 และไปที่คำหลัก 2 จากนั้นไปที่การเลือกตัวกรอง 3
จากนั้น ใช้ตัวกรองคำหลักกับ Regex 4
ตอนนี้ เราอยากจะเสนอกรณีการใช้งานหลายๆ กรณีที่คุณสามารถนำนิพจน์เหล่านี้ไปใช้ให้เกิดประโยชน์สูงสุดจากการวิเคราะห์คำหลักของโครงการของคุณ หรือเมื่อคุณกำลังวิเคราะห์คู่แข่งของคุณ
รวมหรือยกเว้นชื่อแบรนด์
ลองนึกภาพว่าคุณมีแบรนด์ที่ยอมรับการสะกดคำต่างๆ หรือเป็นที่รู้จักจากชื่อแบรนด์ต่างๆ มากมาย เราสามารถสร้างนิพจน์ทั่วไปเพื่อจัดกลุ่มคำหลักทั้งหมดที่เราพิจารณาว่าเป็นคำที่มีตราสินค้า ตัวอย่างเช่น currys.co.uk มีคำหลักของแบรนด์ต่างๆ ได้แก่:
แกง, แกง, pc world
ดังนั้น เราจะใช้นิพจน์ต่อไปนี้:
(curry|currys|pc world).* 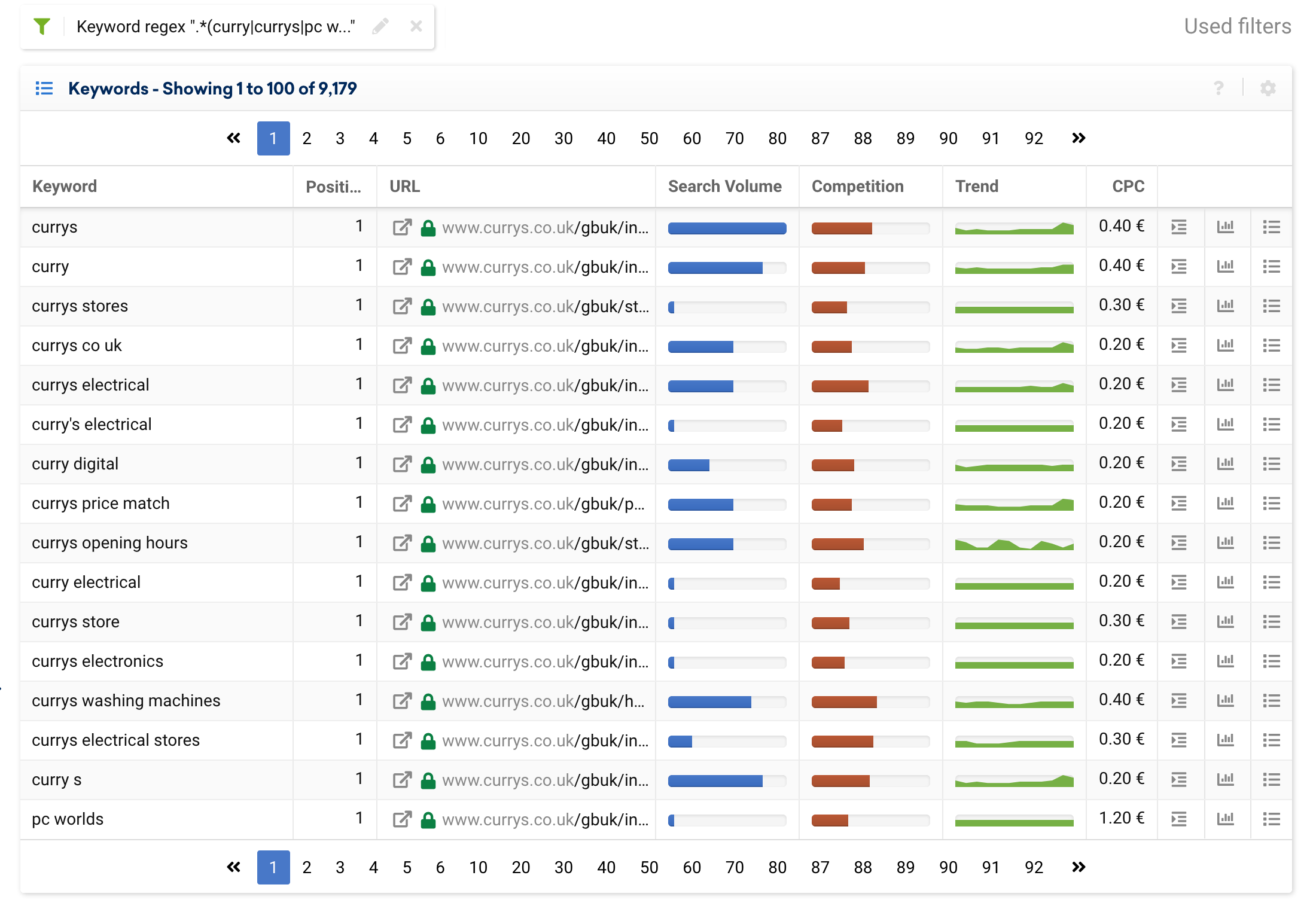
ด้านล่างนี้คุณจะเห็นผลลัพธ์ที่เราจะได้รับ:
นอกจากนี้ยังสามารถตั้งค่าตัวกรองเพื่อยกเว้นคำหลักที่มีตราสินค้า โดยใช้นิพจน์ต่อไปนี้ และจะแสดงเฉพาะคำหลักทั่วไปเท่านั้น:
^(?!.*(curry|currys|pc world).*?) 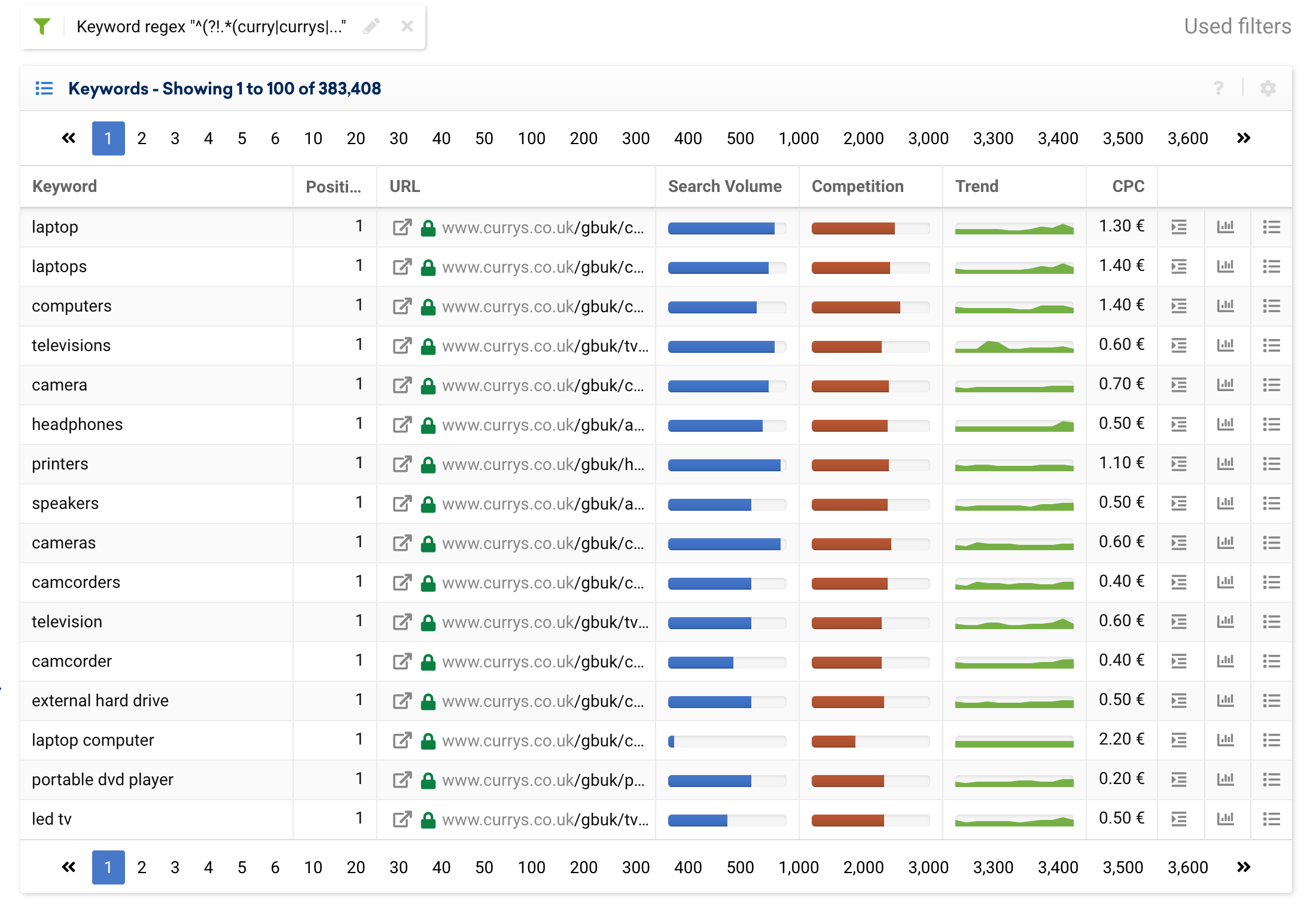
รวมหรือยกเว้นข้อผิดพลาดในเงื่อนไขของแบรนด์
มีโอกาสที่เราอาจพบแบรนด์ต่างๆ ซึ่งมักสะกดผิดหรือเขียนโดยมีข้อผิดพลาด เช่น Ryanair
ต่อไปนี้คือตัวอย่างคำศัพท์บางส่วนที่ผู้ใช้ป้อนเพื่อค้นหาสายการบินนี้:
- ไรอันแอร์
- rayaner
- ไรอัน ir
- rayan ir
- rayana eir
- รายาแนร์
- รายัน อารีย์
- รายาร์แอร์
เราได้ระบุชื่อแบรนด์มากกว่า 35 ชื่อที่เราสามารถจับภาพได้โดยใช้นิพจน์ทั่วไปเพียงรายการเดียว:
เพื่อรวมรูปแบบแบรนด์ทั้งหมด:
(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)? ![ตารางคำหลักในกล่องเครื่องมือ SISTRIX สำหรับ ryanair.com พร้อมตัวกรอง regex ".(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e| บรรทัด| )?(line|ir)?" สมัครแล้ว.](/uploads/article/246/J4RlqK5XMR1iRPm6.png)
หากต้องการยกเว้นรูปแบบแบรนด์ทั้งหมด:
^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$ ![ตารางคำหลักในกล่องเครื่องมือ SISTRIX สำหรับ ryanair.com พร้อมตัวกรอง regex "^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air) ?(e|lines| )?(line|ir)?).)*$" ใช้แล้ว](/uploads/article/246/x8B4lxmc6Vmja5ch.png)
แน่นอน เรายังคงใช้ตัวกรองอื่นๆ กับรายการนี้ได้ เช่น "มี" "ไม่มี" "ลงท้ายด้วย" หรือ "เริ่มต้นด้วย"
รวมหรือยกเว้นคำสำคัญที่ลงท้ายด้วยคำเฉพาะ
ในการค้นหาคีย์เวิร์ดที่ไม่ซ้ำ ตัวกรองง่ายๆ ก็เพียงพอแล้ว แต่ถ้าเราต้องการค้นหาด้วยเงื่อนไขหลายประการ เช่น คีย์เวิร์ดทั้งหมดที่ขึ้นต้นด้วย "ซื้อ" และลงท้ายด้วย "ออนไลน์" เราสามารถใช้:
^buy.*online$ซึ่งใช้กับร้านค้าออนไลน์เช่น screwfix.com จะส่งคืนผลลัพธ์ต่อไปนี้:
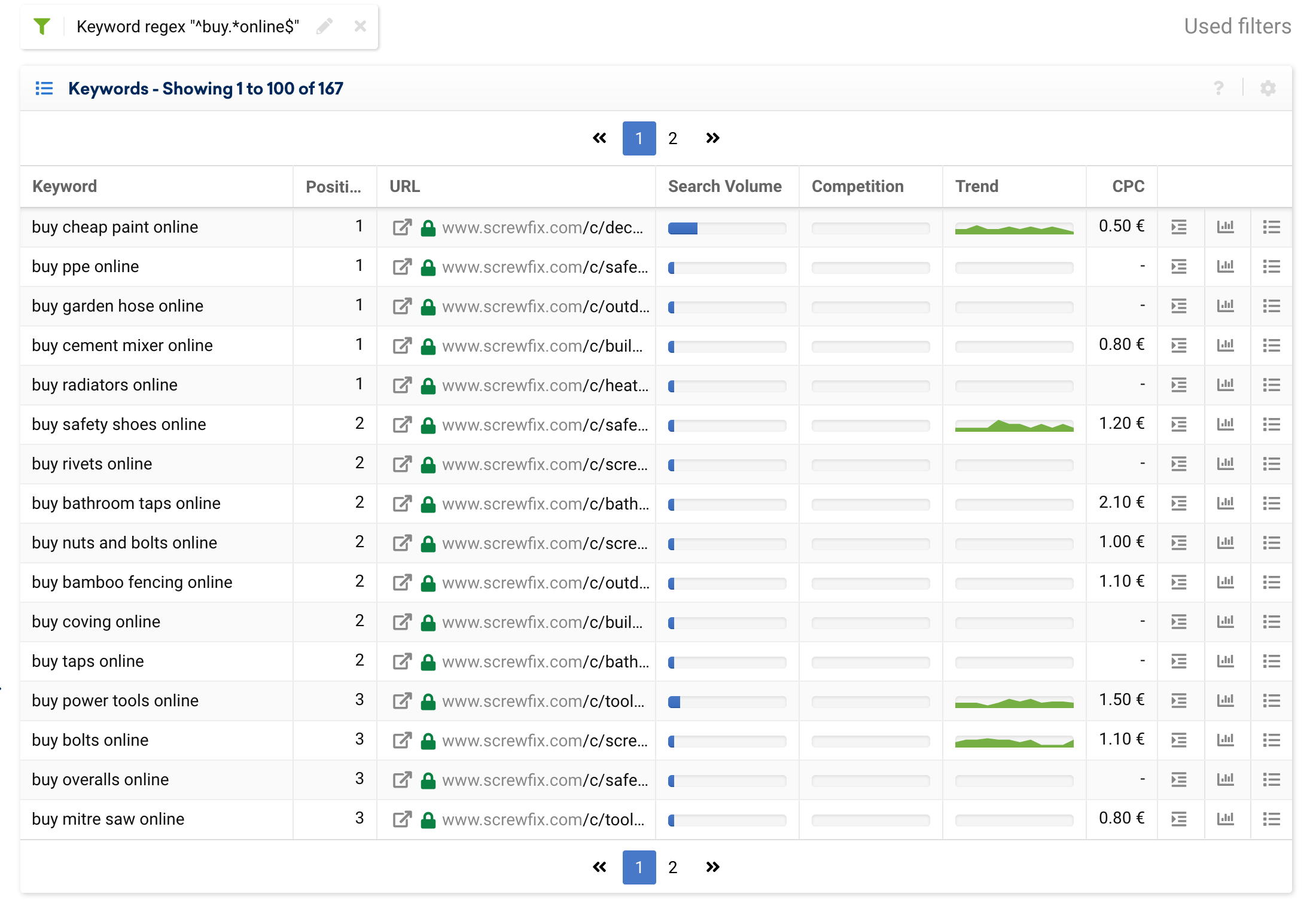
รวมหรือยกเว้นคำสำคัญที่ขึ้นต้นด้วยคำเฉพาะ
จากมุมมองของเครื่องมือเปรียบเทียบ การกรองคำหลักที่มีชื่อตราสินค้าต่างๆ
ตัวอย่างเช่น เราสามารถสร้างนิพจน์ทั่วไปที่จะจัดกลุ่มคำตามเกณฑ์ที่เราต้องการ ซึ่งในกรณีนี้คือคำสำคัญใดๆ ที่ขึ้นต้นด้วยชื่อแบรนด์ที่รวมอยู่ในวงเล็บ:
^(sony|panasonic|philips|samsung).*ในทำนองเดียวกัน เราสามารถใช้เพื่อยกเว้น:
^(?!(sony|panasonic|philips|samsung).*)รวมหรือยกเว้นคำสำคัญที่เกี่ยวข้องกับคุณลักษณะเฉพาะ
มาลองใช้ตัวอย่างแอตทริบิวต์ที่พบบ่อยในหลายโครงการ: ราคา

มีคำค้นหามากมายที่พาดพิงถึงราคา เช่น "ถูก" "ลดราคา" "เอาท์เล็ต" "คูปอง" "เสนอ" "ต้นทุนต่ำ" "งบประมาณ" เป็นต้น
หากเราต้องการแยกออกจากผลลัพธ์ เราสามารถใช้นิพจน์ต่อไปนี้:
.*(cheap|budget|offer|outlet|price).* 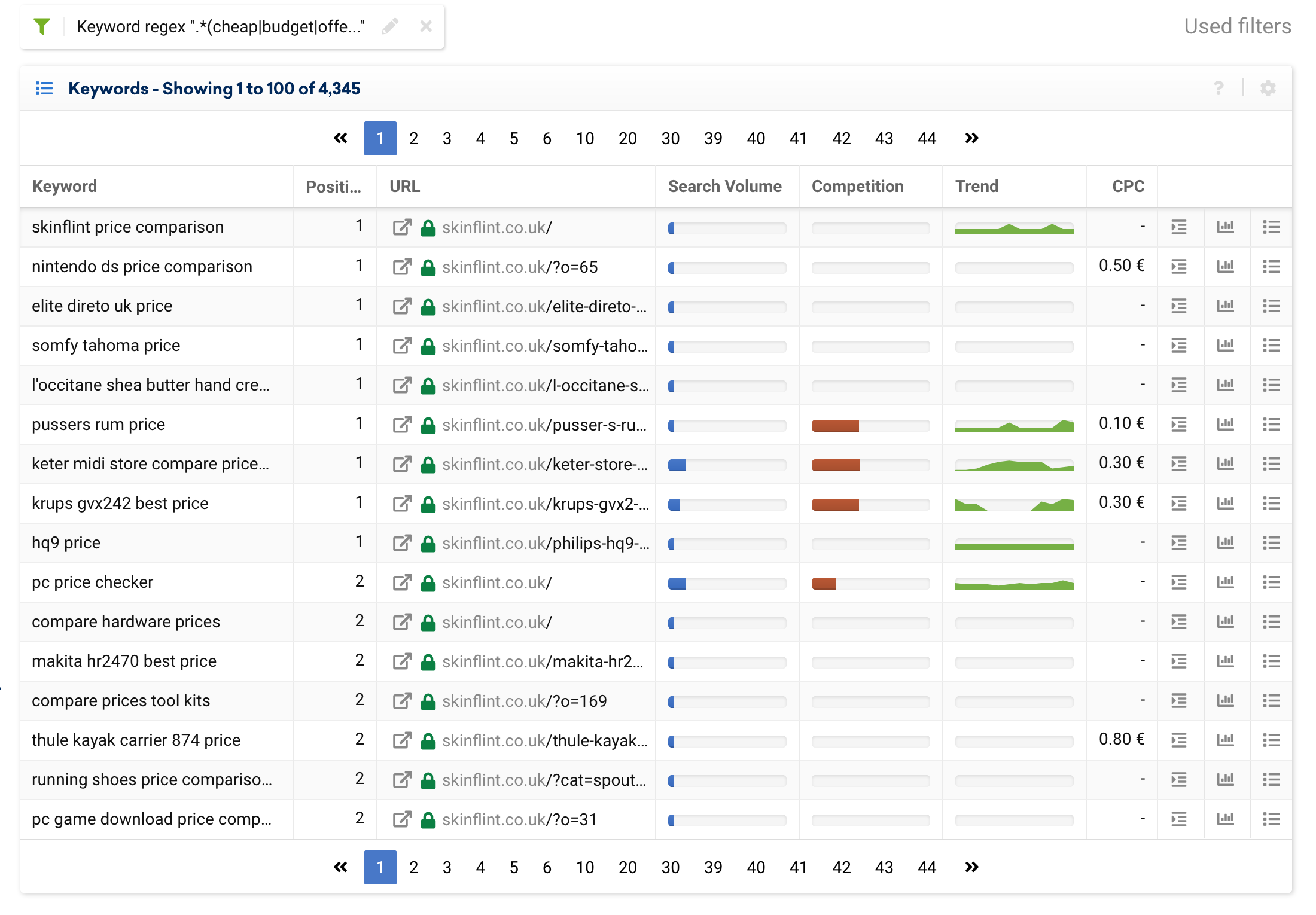
เมื่อใช้คอลัมน์ไดนามิกของตาราง เราสามารถจัดระเบียบข้อมูลตามปริมาณการค้นหาในลำดับจากมากไปน้อย เพียงคลิกที่ส่วนหัวของคอลัมน์
ในกรณีอื่นๆ เรายังสามารถใช้คุณลักษณะอื่นๆ เช่น สี รูปร่าง ขนาด เป้าหมาย เป็นต้น
รวมหรือยกเว้นคำสำคัญที่มีชื่อของเมืองใน United Kindgom
หลายโครงการต้องการการติดตามสถานะในพื้นที่ ในการทำเช่นนี้ เราสามารถใช้ Regex เพื่อจัดกลุ่มจังหวัด ภูมิภาค เมือง เมือง ฯลฯ
ในตัวอย่างนี้ เราจะใช้รายชื่อเมืองเพื่อสร้างนิพจน์ทั่วไปที่จะกรองคำสำคัญที่มีเมือง
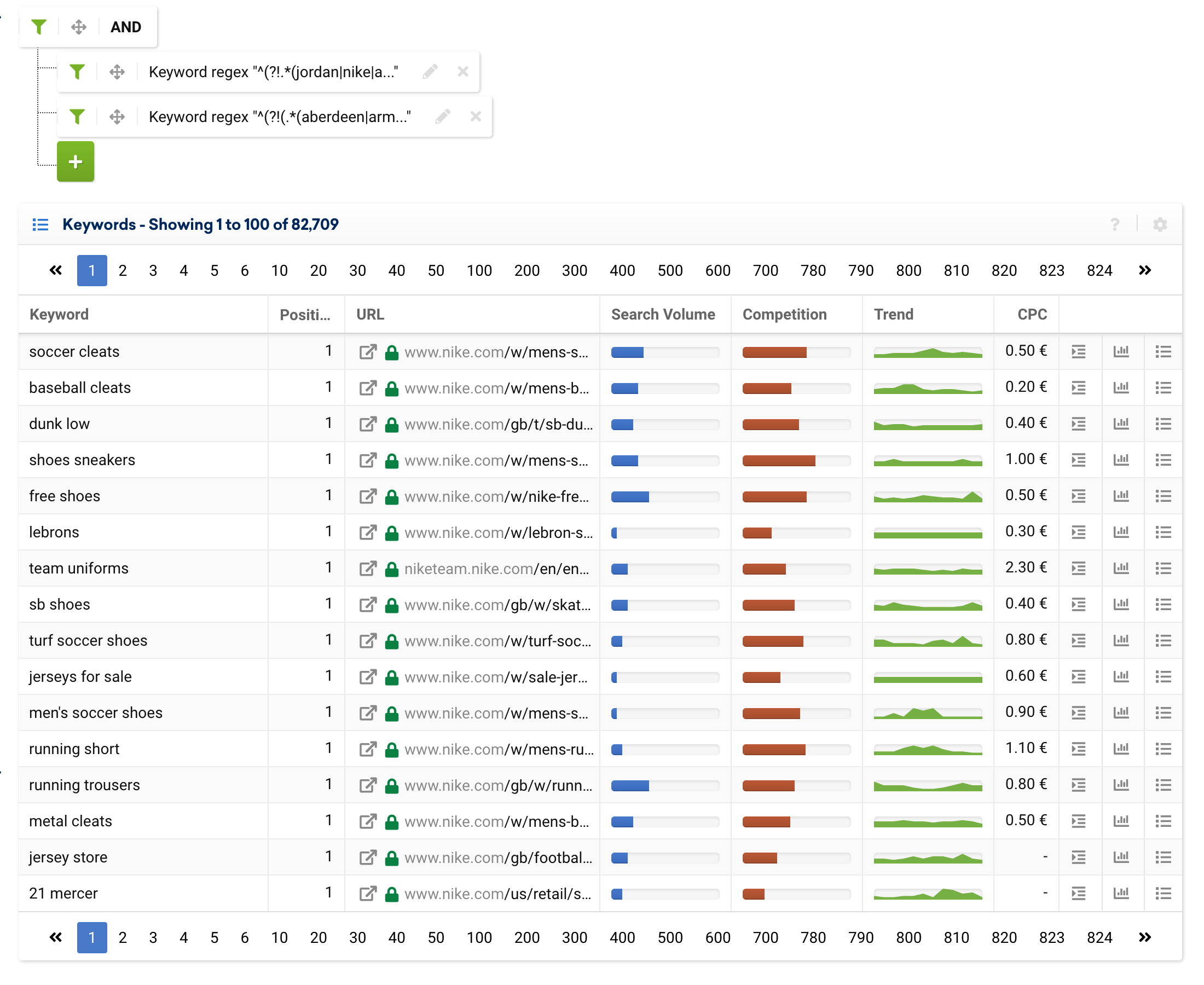
.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*ธุรกิจอีคอมเมิร์ซหรือเครื่องมือเปรียบเทียบใดๆ ที่มีสถานะทางกายภาพสามารถใช้นิพจน์นี้เพื่อยกเว้นเมือง หรือแม้แต่เพิ่มคำหลักที่มีตราสินค้าหรือยกเว้นพารามิเตอร์อื่นๆ
^(?!(.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*))อย่างไรก็ตาม เราสามารถแยกออกเป็นหลายนิพจน์ได้ ดังที่แสดงด้านล่าง:
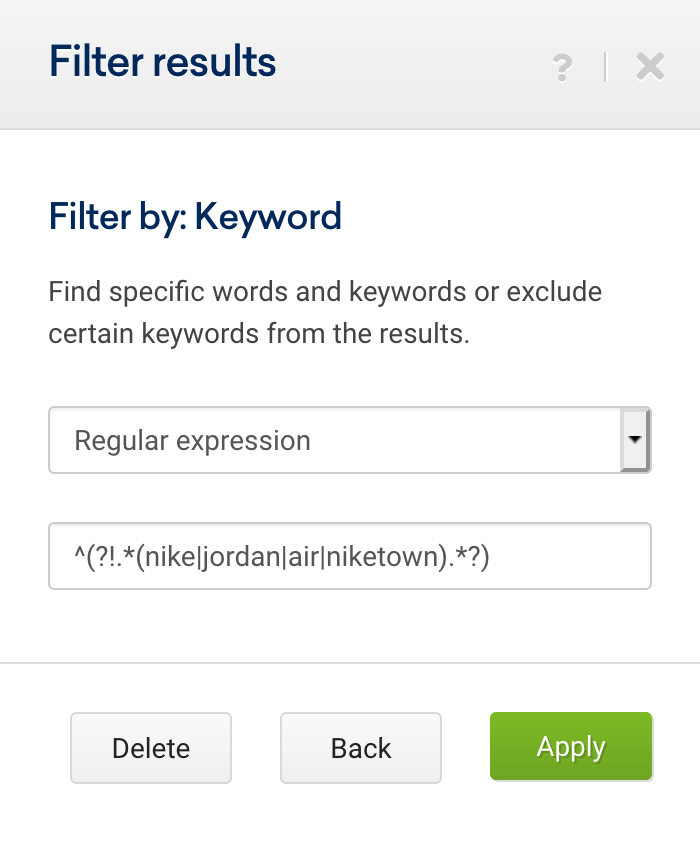
จากนี้ไป เราเพิ่มตัวกรองผู้เชี่ยวชาญเพื่อระบุว่านิพจน์ทั้งสองนี้เป็นประเภท "และ" แทนที่จะเป็นประเภท "หรือ"
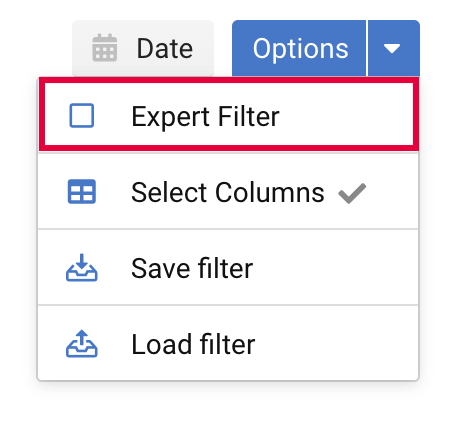
การกรอง URL ด้วยนิพจน์ทั่วไป
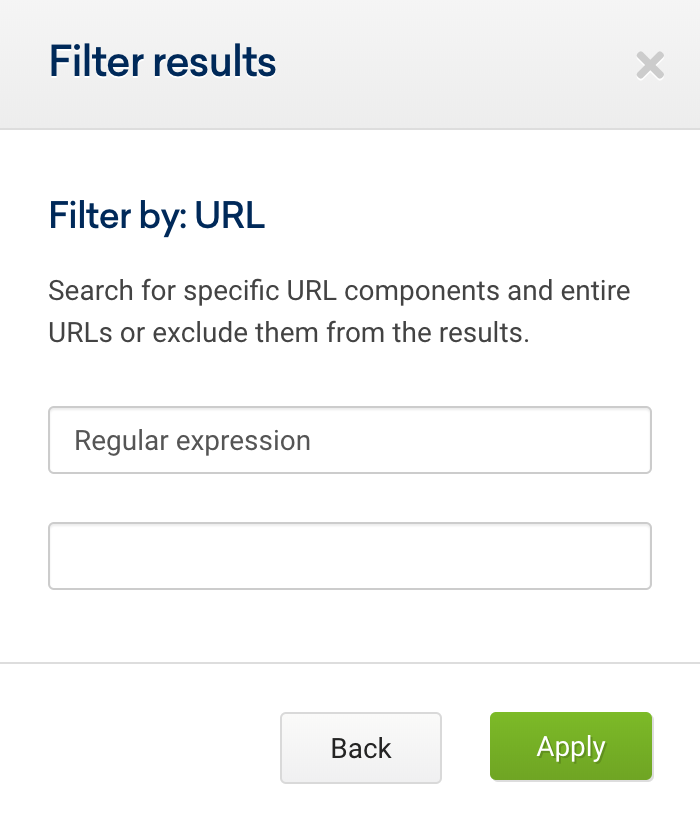
ขั้นตอนที่คุณต้องปฏิบัติตามเพื่อกรอง URL จะเหมือนกับขั้นตอนที่เราสำรวจสำหรับคำหลัก ความแตกต่างเพียงอย่างเดียวคือ คุณจะต้องเลือก "URL" แล้วเลือกนิพจน์ทั่วไป
รวมหรือยกเว้นโดเมนย่อย
ตอนนี้เราได้เรียนรู้วิธีใช้นิพจน์ทั่วไปในการกรองคำหลักแล้ว มาดูกรณีการใช้งาน SEO ทั่วไปที่เราจำเป็นต้องกรอง URL
ต่อไปนี้คือกรณีการใช้งานพื้นฐานสำหรับการวิเคราะห์ทั้งโดเมนและการจัดกลุ่ม URL ตามโดเมนย่อยเชิงกลยุทธ์:
(www|support) 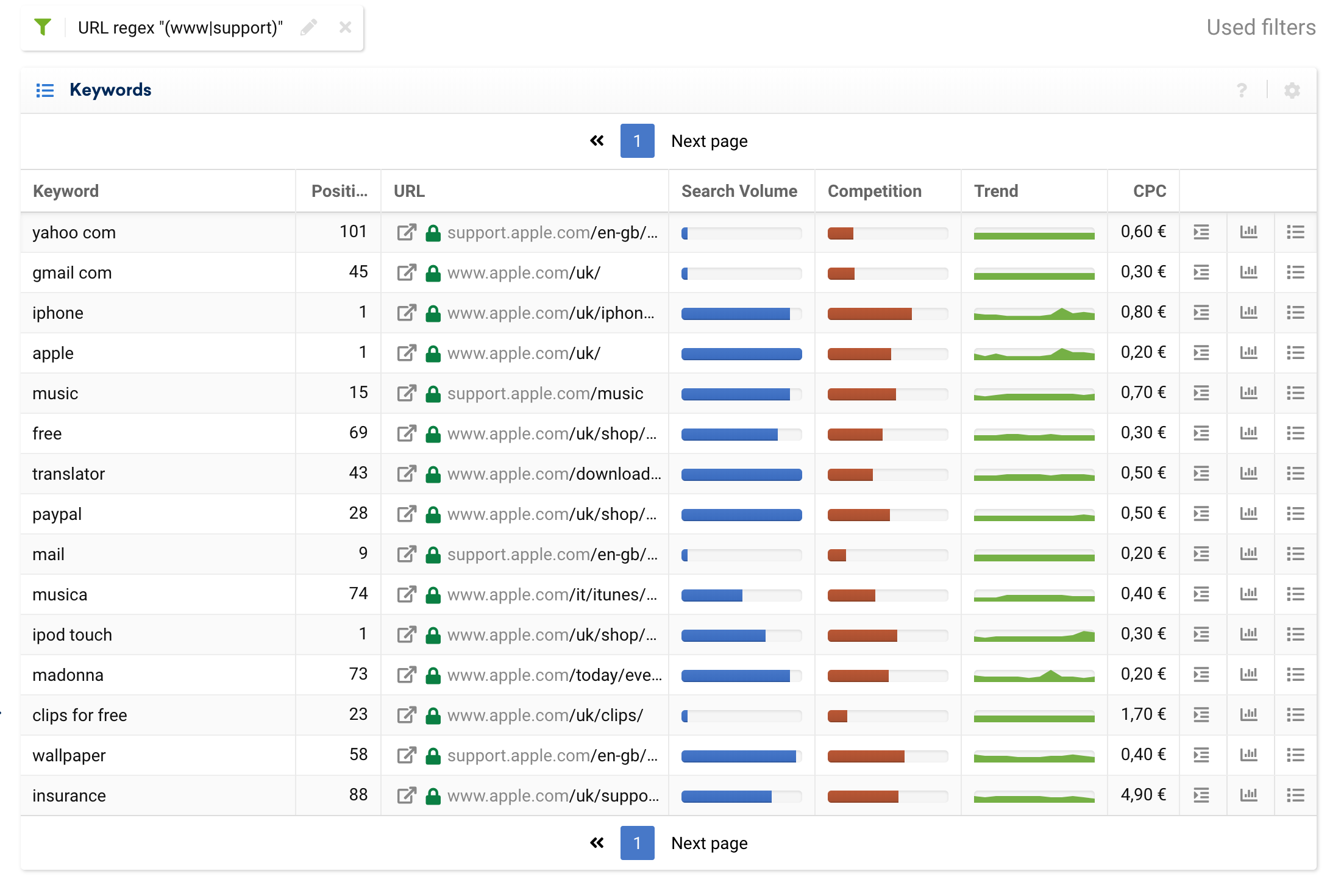
เราสามารถใช้ตัวกรองการยกเว้นเพื่อแยกโดเมนย่อยของธุรกรรมเพียงอย่างเดียว และละเว้นคำหลักที่ให้ข้อมูลที่มาจากบล็อกหรือคำถามที่พบบ่อย
^^(?!.*(www|support).*?) 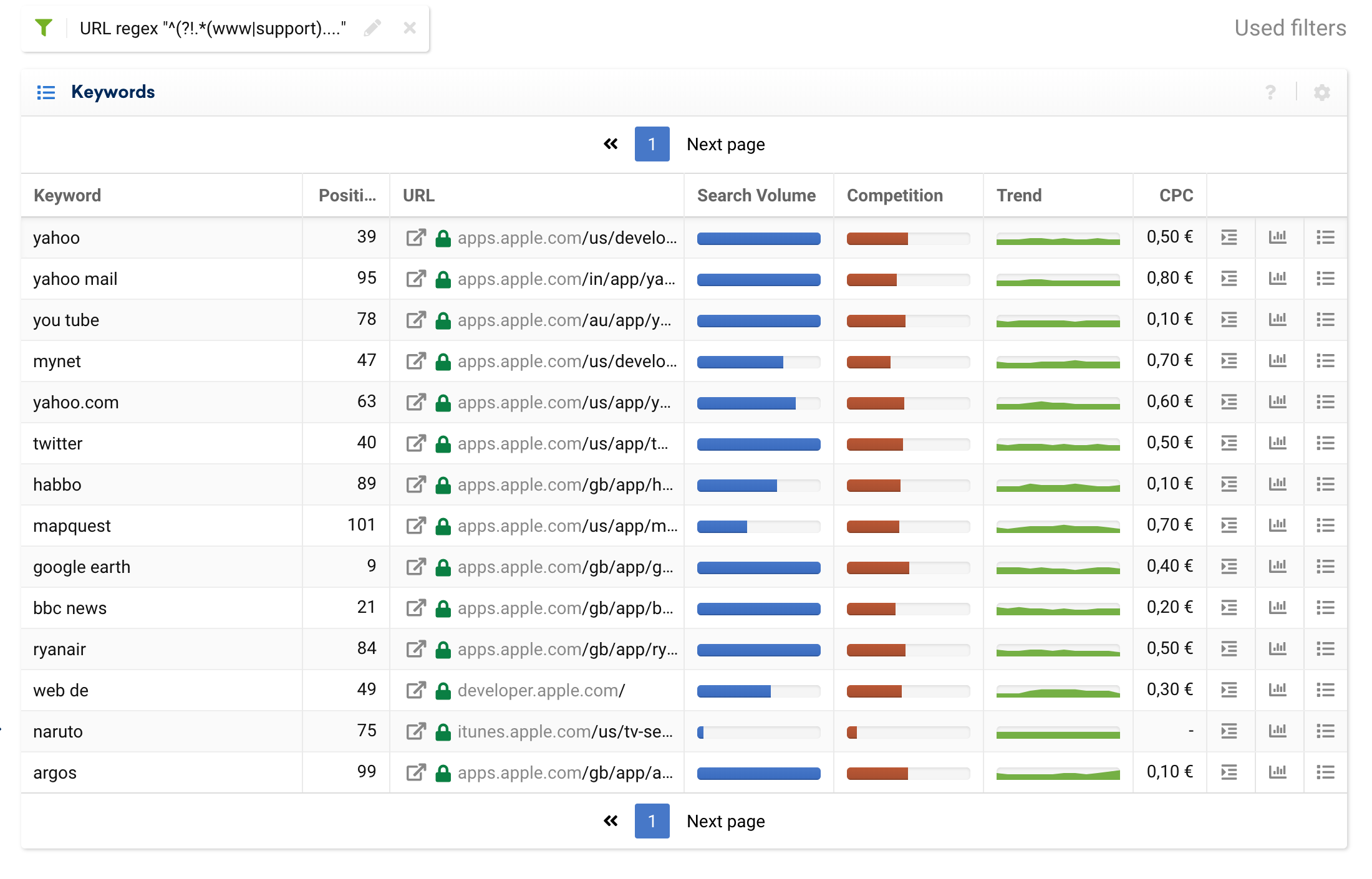
รวมหรือยกเว้น URL ที่ลงท้ายหรือไม่ลงท้ายด้วย /
หากโดเมน .com ของหน้าแรกลงท้ายด้วยเครื่องหมายทับ regex สามารถปรับให้ตรงกันได้:
^.*.com/$ ^(?!(.*.com/$))URL ใดๆ ที่ลงท้ายด้วย /
.*/$นอกจากนี้เรายังสามารถใช้ Regex นี้สำหรับ URL เพื่อเน้นเฉพาะ URL ที่ลงท้ายด้วยเครื่องหมายทับ (/) ในการดำเนินการดังกล่าว ให้ป้อนโดเมนลงในแถบค้นหา (1) จากนั้นคลิก URL ในการนำทาง (2) เพิ่มตัวกรอง (3) และเลือกตัวกรอง URL เป็น “นิพจน์ทั่วไป” (4):
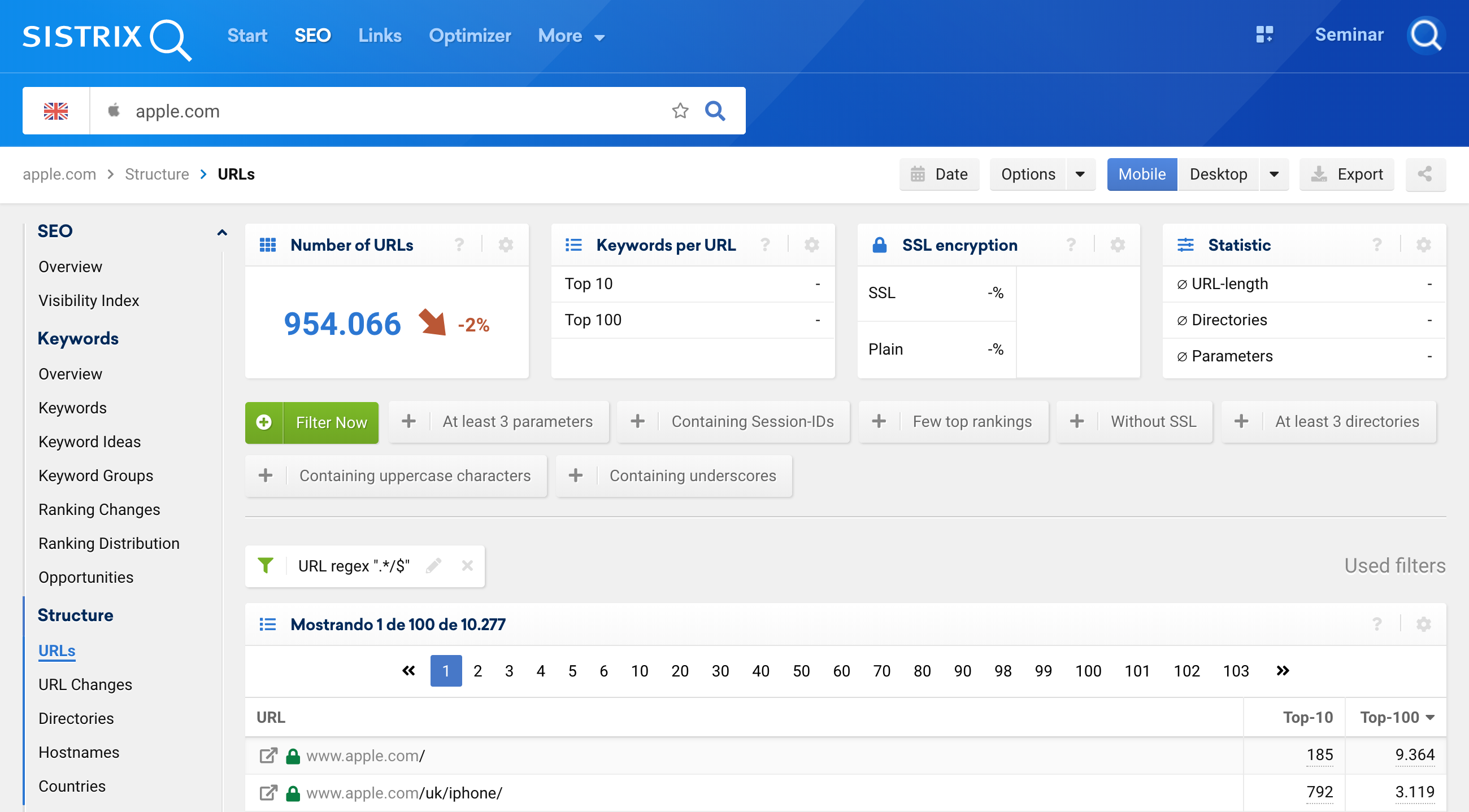
แน่นอนว่าสิ่งนี้ใช้ได้กับ URL ที่ไม่ได้ลงท้ายด้วย /
^(?!(.*/$)) 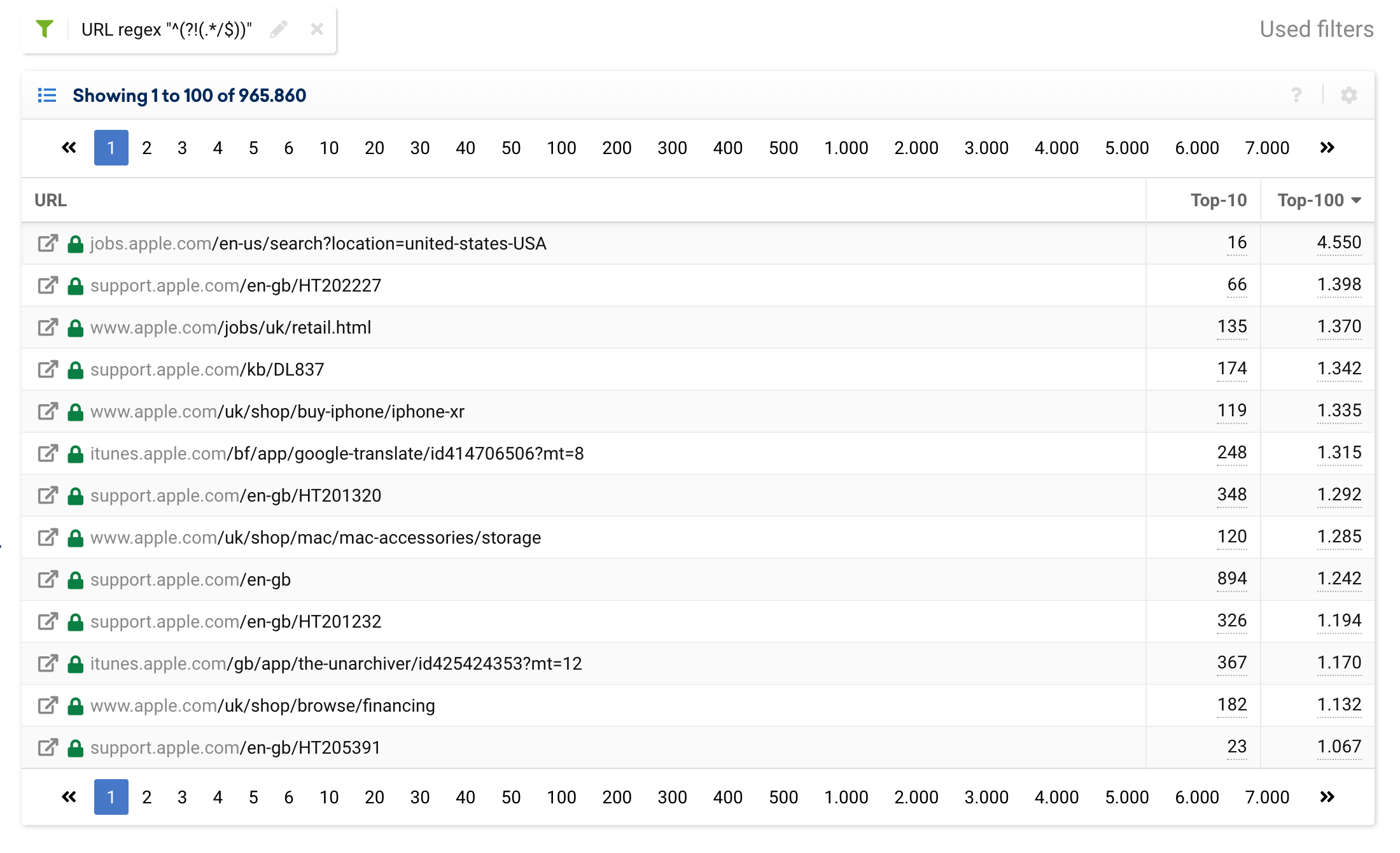
รวมหรือยกเว้น URL ที่มีตัวเลข
เราสามารถแก้ไขไวยากรณ์ URL เพื่อระบุว่ามีตัวเลขใดบ้างที่จะรวมหรือแยกออก:
.*-[0-9].* ^(?!(.*-[0-9].*))หากเราต้องการสิ่งที่เจาะจงมากกว่านี้ และเรารู้ว่ามี URL ที่ลงท้ายด้วยตัวเลขเฉพาะ เราสามารถรวมหรือยกเว้น URL ได้ดังนี้:
.*-[0-9]+$ ^(?!(.*-[0-9]+$))ในกรณีนี้ คำขอของเราคือกรองสายโซ่ที่มีตัวเลขต่อเนื่องกัน 8 ตัว
.*[0-9]{8}.html$ ^(?!(.*[0-9]{8}.html$))รวมหรือยกเว้น URL ในรูปแบบเฉพาะ
เราสามารถใช้ Regex เพื่อกรองรูปแบบ URL ได้เช่นกัน ตัวอย่างเช่น URL htm หรือ html รวมถึง pdf
มันค่อนข้างง่ายเพราะเราสามารถวางใจได้ว่าจะใช้ตัวกรอง "ลงท้ายด้วย" หรือ "มี"
.*htm.?$ .*pdf$หากต้องการยกเว้นรูปแบบ URL ที่ต้องการ:
^(?!(.*html.?$).) ^(?!(.*pdf.?$).)เราสามารถใช้รูปแบบได้หลายรูปแบบภายในนิพจน์เดียวกัน ซึ่งจะมีค่ามากกว่า และจะช่วยเราไม่ต้องยุ่งยากในการรวมตัวกรองหลายตัวเข้าด้วยกัน ซึ่งรวมถึง:
.*(htm|html)$ .*(jpg|jpeg|gif|png)$และเรายังสามารถรวมรูปแบบที่จะยกเว้นได้:
^(?!(.*(htm|html)$).) ^(?!(.*htm.?)$).) ^(?!(.*(jpg|jpeg|gif|png)$).)รวมหรือยกเว้น URL ที่เกี่ยวข้องกับตลาดที่ไม่ถูกต้อง
เราสามารถตรวจสอบ URL ที่ไม่ควรปรากฏในผลลัพธ์ของตลาดเฉพาะ ตัวอย่างเช่น URL ที่เกี่ยวข้องกับตลาดสหรัฐอเมริกา เม็กซิโก หรือเยอรมันที่ปรากฏในผลลัพธ์ของตลาดสเปน
ใช้อินสแตนซ์ URL ต่อไปนี้เป็นพื้นฐานของเรา:
สเปนของสเปน /es_es/
อังกฤษแบบอังกฤษ /en_gb/
ภาษาอังกฤษแบบสหรัฐอเมริกา /en_us/
อิตาเลี่ยนของอิตาลี /it_it/
และอื่นๆ.
เราสามารถใช้ Regex เพื่อกรองจำนวน URL ที่ไม่ได้เป็นของตลาดสเปน
^(?!(.*[es]_[az].*)|(.*[az]_[es].*).) ![ตารางคำหลักในกล่องเครื่องมือ SISTRIX สำหรับ hm.com ที่มีตัวกรอง regex "^(?!(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)" ถูกนำไปใช้ .](/uploads/article/246/TIPPU8qnSB57ontM.png)
ดังที่คุณเห็น นิพจน์อนุญาตให้ใช้ URL ของโฮมเพจ ซึ่งเป็นที่ตั้งของตัวเลือกภาษา
เพื่อปรับแต่งนิพจน์นี้เพิ่มเติมและออกจากหน้าแรก เราสามารถขยายได้ดังที่แสดงด้านล่าง:
^(?!(.*.com/$)|(.*[es]_[az].*)|(.*[az]_[es].*).) ![ตารางคำหลักในกล่องเครื่องมือ SISTRIX สำหรับ hm.com ที่มีตัวกรอง regex "^(?!(.*.com/$)|(.*[es]_[a-z].*)|(.*[a-z]_[ es].*).)" ใช้](/uploads/article/246/vxYA4KacpOcflwYd.png)
สรุป
ด้วยพารามิเตอร์ที่ให้ไว้ในโพสต์นี้ คุณจะสามารถค้นหากรณีการใช้งานของคุณเองได้ ซึ่งนิพจน์ทั่วไปอาจมีประโยชน์ และช่วยให้คุณวิเคราะห์ SEO ได้อย่างมีประสิทธิภาพมากขึ้น
คุณสามารถทำการทดสอบและฝึกฝนต่อไปด้วยเครื่องมือต่างๆ เช่น https://www.Regextester.com/ หรือโดยตรงกับตัวกรอง URL คำหลักหรือตัวอย่างข้อมูลของ SISTRIX
แม้ว่าเราจะไม่ได้ให้การสนับสนุน Regex แต่เราจะอัปเดตบทช่วยสอนนี้ต่อไปด้วยกรณีการใช้งานใหม่และการวิเคราะห์ SEO ที่อาจเป็นประโยชน์สำหรับคุณ