
如何在工具箱中使用正则表达式
已发表: 2022-04-17- 什么是正则表达式?
- 我们如何构建正则表达式?
- 带有正则表达式的 SEO 示例
- 使用正则表达式过滤关键字
- 包括或排除品牌名称
- 在品牌字词中包含或排除错误
- 包括或排除以特定字词结尾的关键字字词
- 包含或排除以特定字词开头的关键字字词
- 包括或排除与特定属性相关的关键字词
- 包含或排除包含英国城市名称的关键字词
- 使用正则表达式过滤 URL
- 包括或排除子域
- 包括或排除以 / 结尾或不结尾的 URL
- 包括或排除包含数字的 URL
- 包含或排除特定格式的 URL
- 包含或排除与错误市场相关的 URL
- 概括
什么是正则表达式?
正则表达式用于检查或验证模式。 它们的主要应用是过滤元素和查找匹配项,例如,在以下场景中:
- 分析:您可以使用正则表达式来细分流量。
- Htaccess:您可以以更有效的方式重写 URL。
- SISTRIX:您可以过滤我们包含 URL、片段或关键字的报告。
正则表达式 - 或 Regex - 可用于许多编程语言,但本教程将基于 Perl,因为它使用已可用的 SISTRIX Regex 功能所基于的标准。
我们如何构建正则表达式?
我们将通过使用字符、分组、量词和类来做到这一点,因为这是我们将能够构建表达式的语法。
| 人物 | 行为 | 例子 |
|---|---|---|
| ? | 查找前面的字符 1 次或 0 次。 | HTTPS? |
| * | 查找前面的字符 0 次或更多次。 | 30* |
| + | 查找前面的字符 1 次或多次。 | [0-9]+ |
| | | 寻找一个或另一个元素。 (或者) | (jpg|jpeg) |
| ^ | 表示模式的开始 | ^https |
| $ | 表示模式的结束 | html$ |
| · | 查找任何字符(通配符) | 4.. |
| \ | 不解释特殊字符(跳过字符) | \/ |
| 分组 | 行为 | 例子 |
|---|---|---|
| () | 捕获特定内容 | (西斯特里克斯) 匹配 sistrix |
| [] | 捕获括号内的字符 | [0-9] 匹配任何数字字符 [阿兹] 匹配任何小写字母 |
| {} | 指示迭代次数,最小值或最大值 | .{1,3} 匹配任何重复 1 到 3 次的字符。 |
在本教程中,我们不会使用量词,但我们认为熟悉它们对您来说仍然很有趣,以防您在其他环境中使用它们。
| 量词 | 行为 |
|---|---|
| \w | 查找单词、数字或 _ 类型的字符 |
| \d | 寻找数字字符 |
| \s | 寻找空白字符 |
| \b | 匹配单词的开头或结尾 |
| \W | 查找不是单词、数字或 _ 的字符 |
| \D | 查找不是数字的字符 |
| \S | 查找不是空格的字符。 |
带有正则表达式的 SEO 示例
为了能够使用建议的示例,您需要转到“关键字”部分并使用关键字、URL、标题或描述过滤器。
使用正则表达式过滤关键字
要访问此功能,您只需分析域1并转到关键字2 ,然后转到过滤器选择3
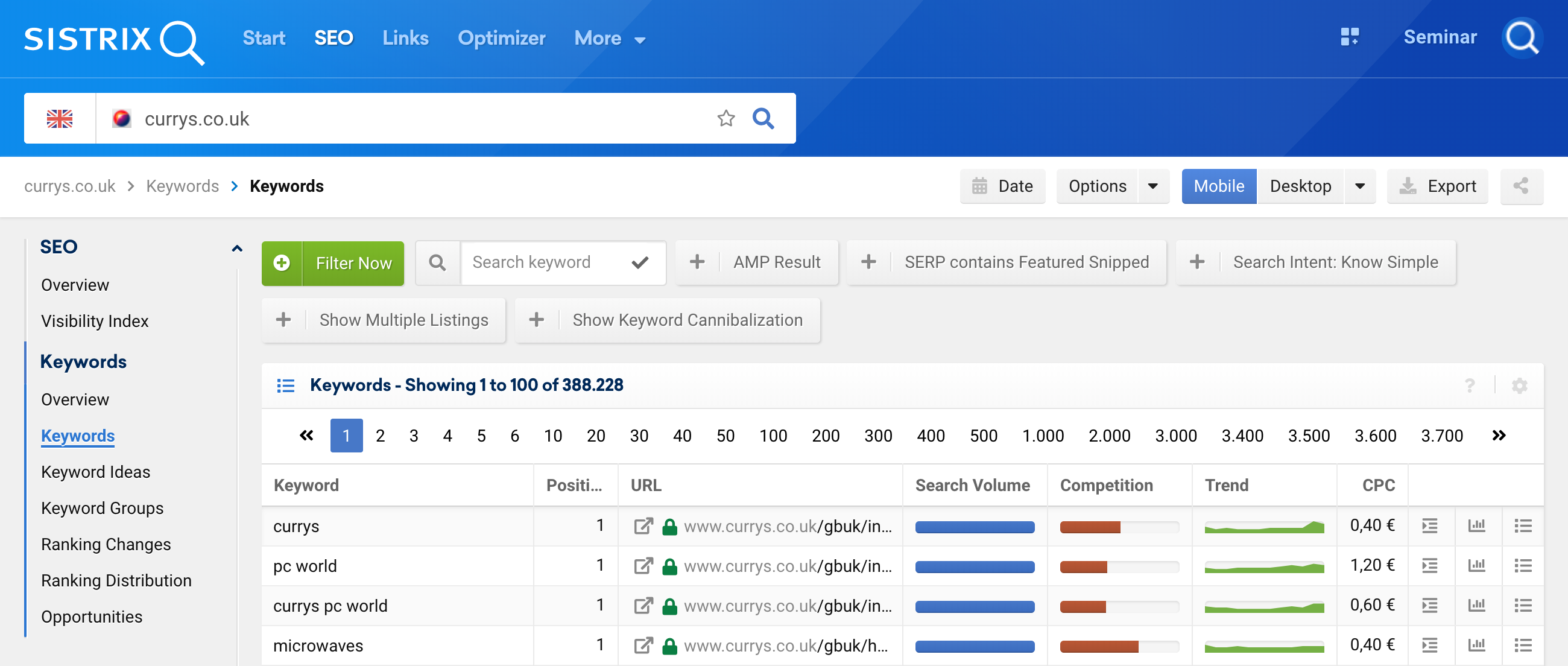
然后,将关键字过滤器与 Regex 4一起使用。
现在,我们想提出几个用例,您可以在其中应用这些表达式,以充分利用项目的关键字分析,或者在分析竞争对手时。
包括或排除品牌名称
想象一下,您有一个接受不同拼写的品牌,或者有几个不同的品牌名称。 我们可以创建一个正则表达式来对我们认为是品牌术语的所有关键字进行分组。 例如,currys.co.uk 有各种品牌关键词,即:
咖喱, 咖喱, 电脑世界
因此,我们将使用以下表达式:
(curry|currys|pc world).* 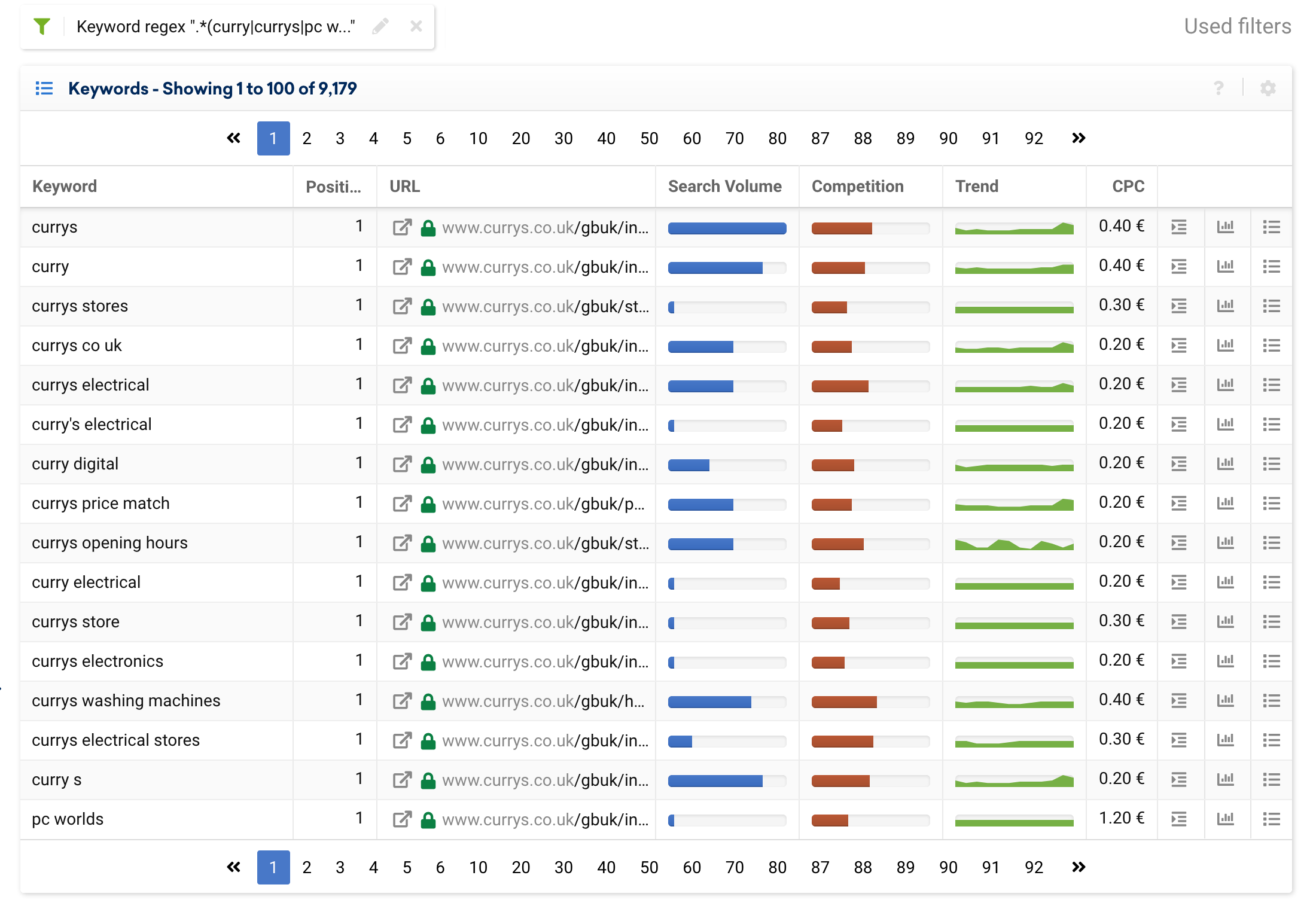
您可以在下面看到我们将得到的结果:
也可以使用以下表达式将过滤器设置为排除品牌关键字,它将仅显示通用关键字:
^(?!.*(curry|currys|pc world).*?) 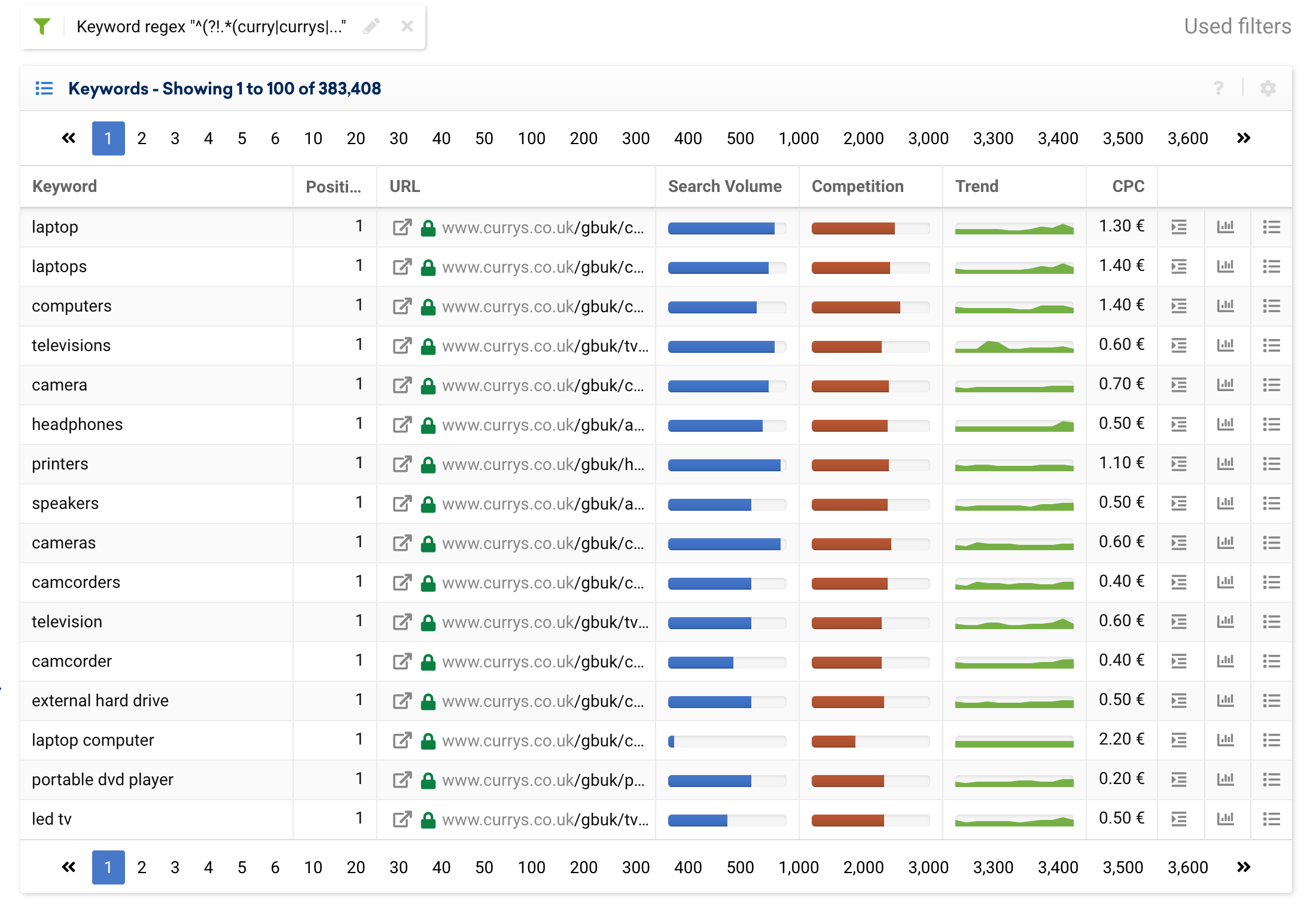
在品牌字词中包含或排除错误
我们可能会遇到品牌,这些品牌经常拼写错误或写有错误,例如瑞安航空。
以下是用户输入以查找该航空公司的一些术语示例:
- 瑞安航空
- 雷亚纳
- 瑞安艾尔
- 拉扬红外线
- 瑞亚那艾尔
- 拉亚奈尔
- 拉扬阿里
- 雷亚尔空气
我们已经确定了超过 35 个品牌名称,我们只需使用一个正则表达式即可捕获:
包括所有品牌变体:
(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)? ![ryanair.com 的 SISTRIX 工具箱中的关键字表,带有正则表达式过滤器“.(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|行|)?(行|ir)?"应用。](/uploads/article/246/J4RlqK5XMR1iRPm6.png)
排除所有品牌变体:
^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air)?(e|lines| )?(line|ir)?).)*$ ![ryanair.com 的 SISTRIX 工具箱中的关键字表,带有正则表达式过滤器“^((?!(r|t)[hzeuayi]?[naiy].?[an]?[airn].?(r|t|air) ?(e|lines| )?(line|ir)?).)*$" 应用。](/uploads/article/246/x8B4lxmc6Vmja5ch.png)
当然,我们仍然可以将其他过滤器应用于此列表,例如“包含”、“不包含”、“结束于”或“开始于”。
包括或排除以特定字词结尾的关键字字词
要搜索一个唯一的关键字,一个简单的过滤器就足够了,但是如果我们想要执行多个条件的搜索,例如:所有以“buy”开头并以“online”结尾的关键字,我们可以使用:
^buy.*online$这适用于像螺丝钉这样的在线商店,将返回以下结果:
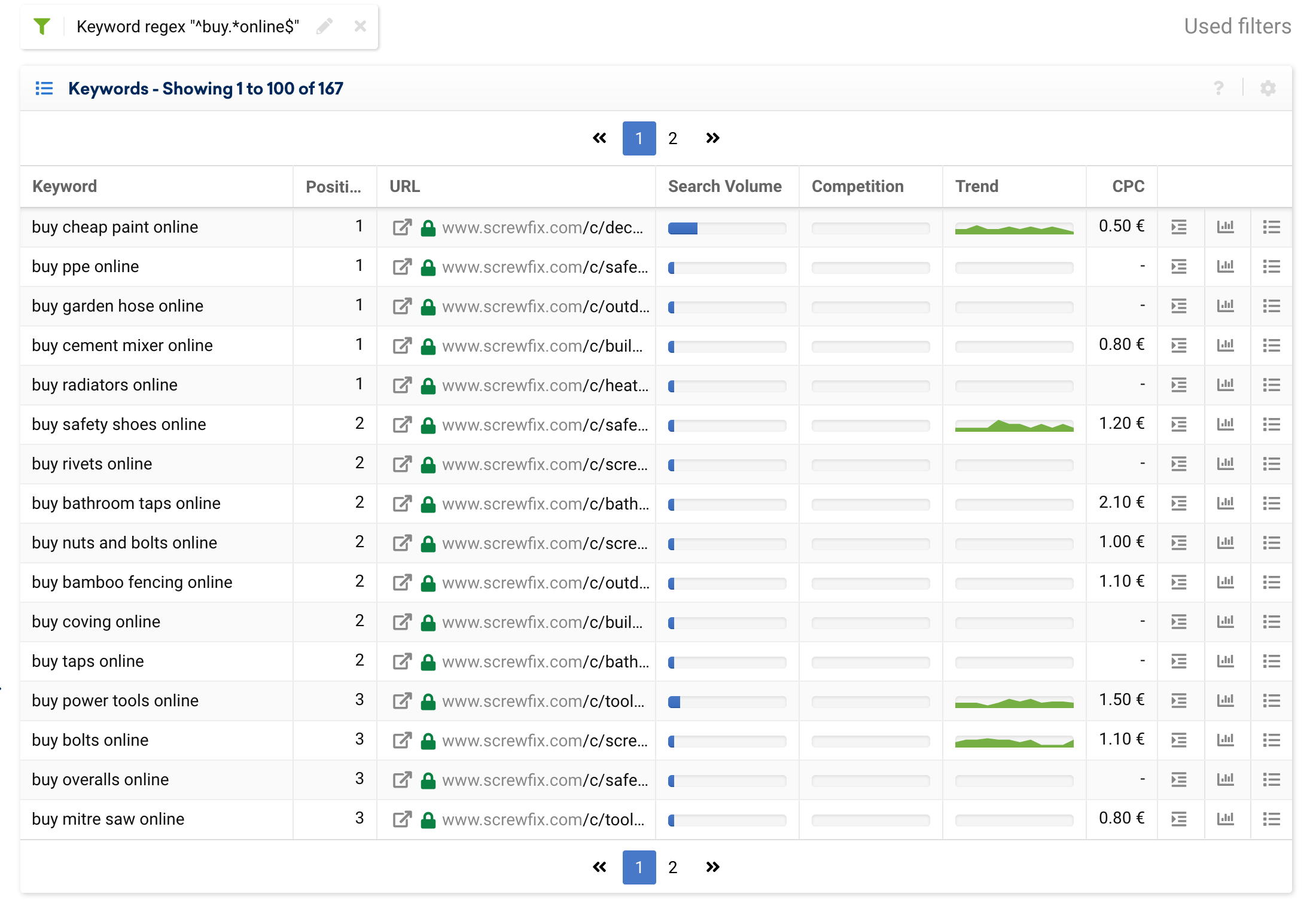
包含或排除以特定字词开头的关键字字词
从比较工具的角度来看,能够过滤包含各种品牌名称的关键字可能会很有趣。
例如,我们可以创建一个正则表达式,它将根据我们想要的条件对术语进行分组,在这种情况下,任何以括号内包含的任何品牌名称开头的关键字术语:
^(sony|panasonic|philips|samsung).*同样,我们可以使用它来排除它们:

^(?!(sony|panasonic|philips|samsung).*)包括或排除与特定属性相关的关键字词
让我们用一个在许多项目中经常遇到的属性的例子来试试这个:价格。
有许多暗示价格的搜索查询,例如:“便宜”、“折扣”、“奥特莱斯”、“优惠券”、“报价”、“低成本”、“预算”等。
如果我们想从结果中排除它们,我们可以使用以下表达式:
.*(cheap|budget|offer|outlet|price).* 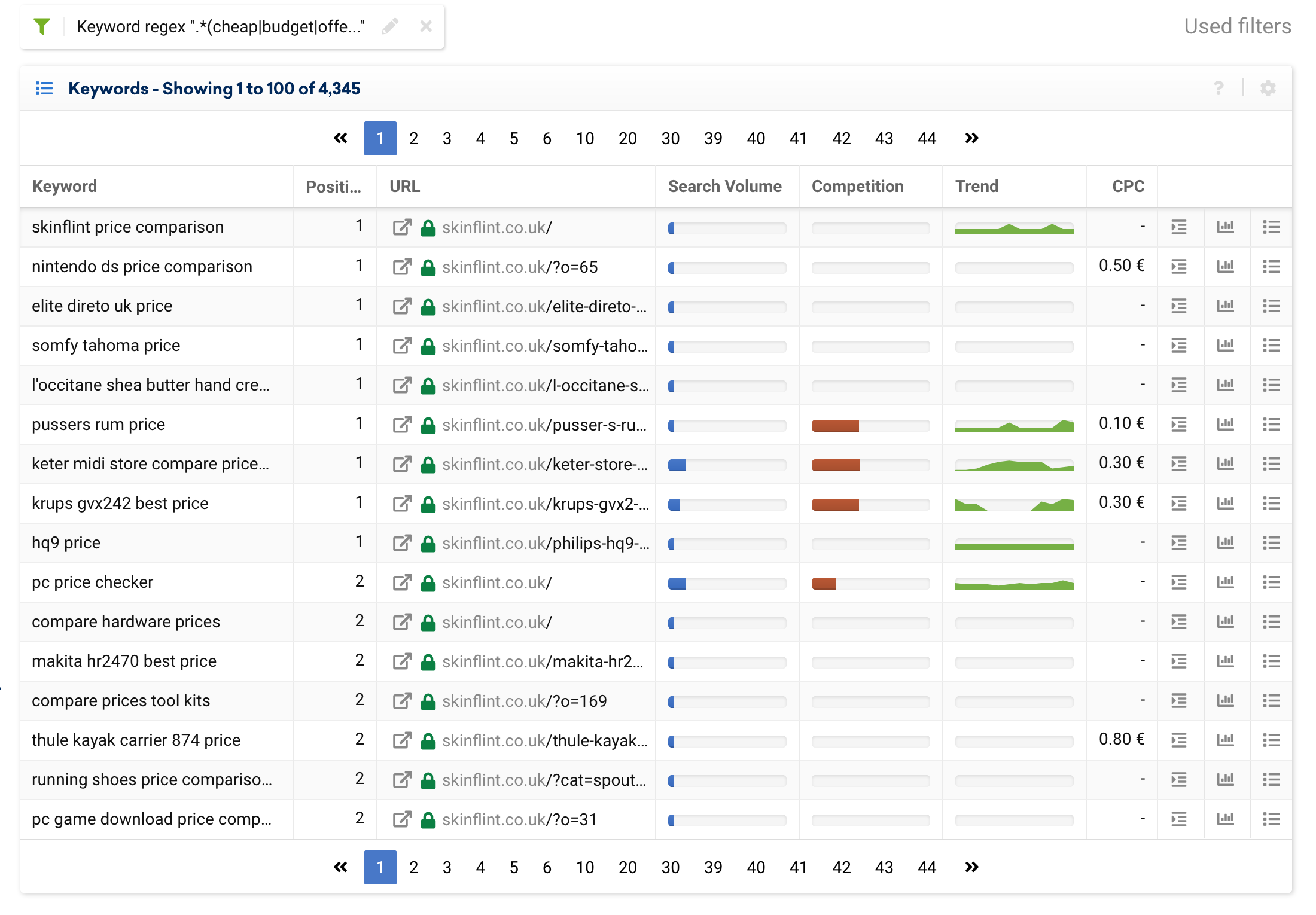
利用表格的动态列,我们可以按搜索量按降序组织数据,只需单击列的标题即可。
在其他情况下,我们还可以使用其他属性,如颜色、形状、大小、目标等。
包含或排除包含英国城市名称的关键字词
许多项目需要本地存在跟踪。 为此,我们可以使用正则表达式对省、地区、城市、城镇等进行分组。
在此示例中,我们将使用城市列表构建一个正则表达式,该表达式将过滤包含城市的关键字词。
.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*任何有实体存在的电子商务企业或比较工具都可以使用此表达式来排除城市,甚至添加品牌关键字或排除其他参数。
^(?!(.*(aberdeen|armagh|bangor|bath|belfast|birmingham|bradford|brighton|brighton & hove|bristol|cambridge|canterbury|cardiff|carlisle|chelmsford|chester|chichester|coventry|derby|derry|dundee|durham|edinburgh|ely|exeter|glasgow|gloucester|hereford|inverness|kingston|kingston upon hull|lancaster|leeds|leicester|lichfield|lincoln|lisburn|liverpool|london|manchester|newcastle|newcastle upon tyne|newport|newry|norwich|nottingham|oxford|perth|peterborough|plymouth|portsmouth|preston|ripon|st albans|st asaph|st davids|salford|salisbury|sheffield|southampton|stoke|stoke-on-trent|sunderland|swansea|truro|wakefield|wells|westminster|winchester|wolverhampton|worcester|york).*))但是,我们也可以将它们分成几个表达式,如下所示:
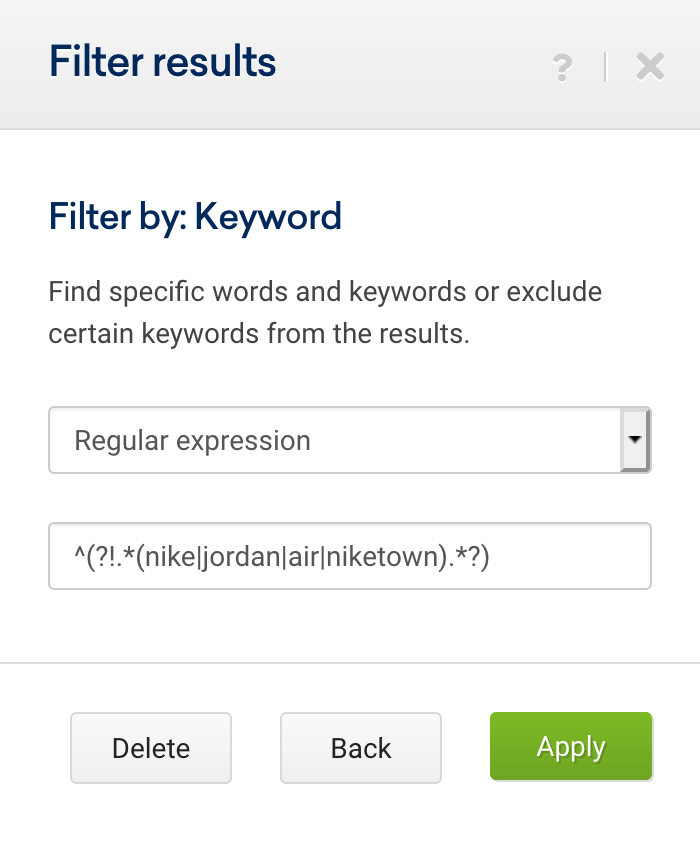
从这里开始,我们添加专家过滤器以指示这两个表达式的类型是“and”,而不是类型“or”。
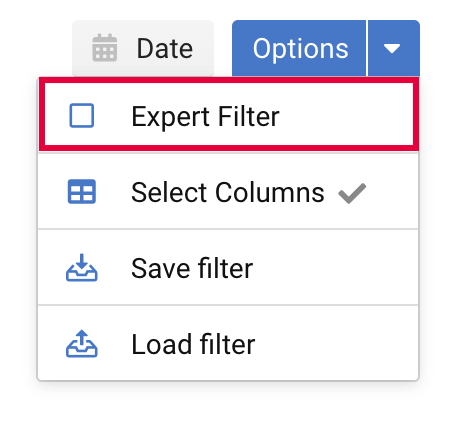
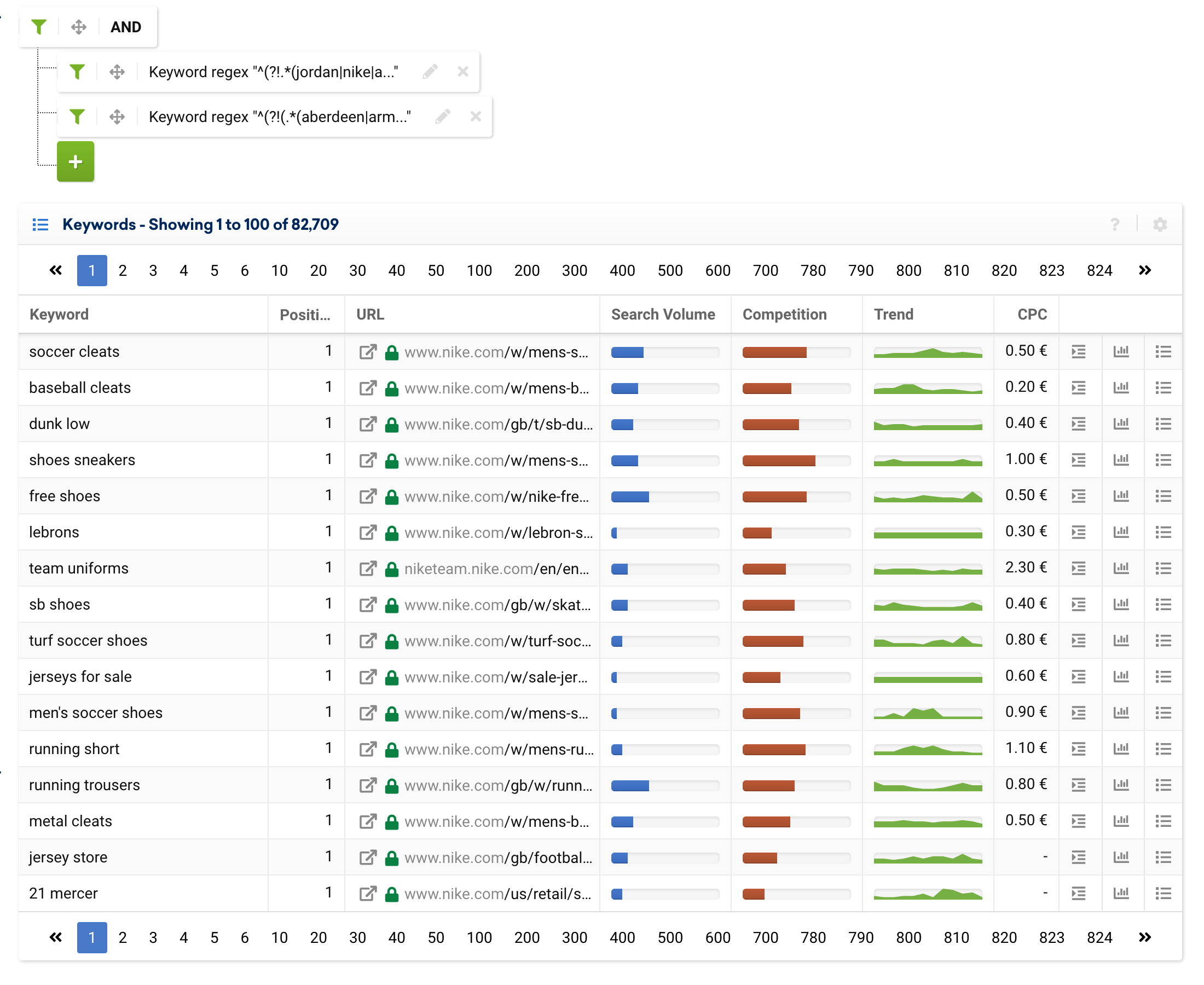
使用正则表达式过滤 URL
为了过滤 URL,您需要遵循的步骤与我们为关键字探索的步骤相同,唯一的区别是,您必须选择“URL”,然后选择正则表达式。
包括或排除子域
现在我们已经学习了如何使用正则表达式来过滤关键字,让我们找到一些需要过滤 URL 的典型 SEO 用例。
以下是分析整个域并按战略子域对 URL 进行分组的一些基本用例:
(www|support) 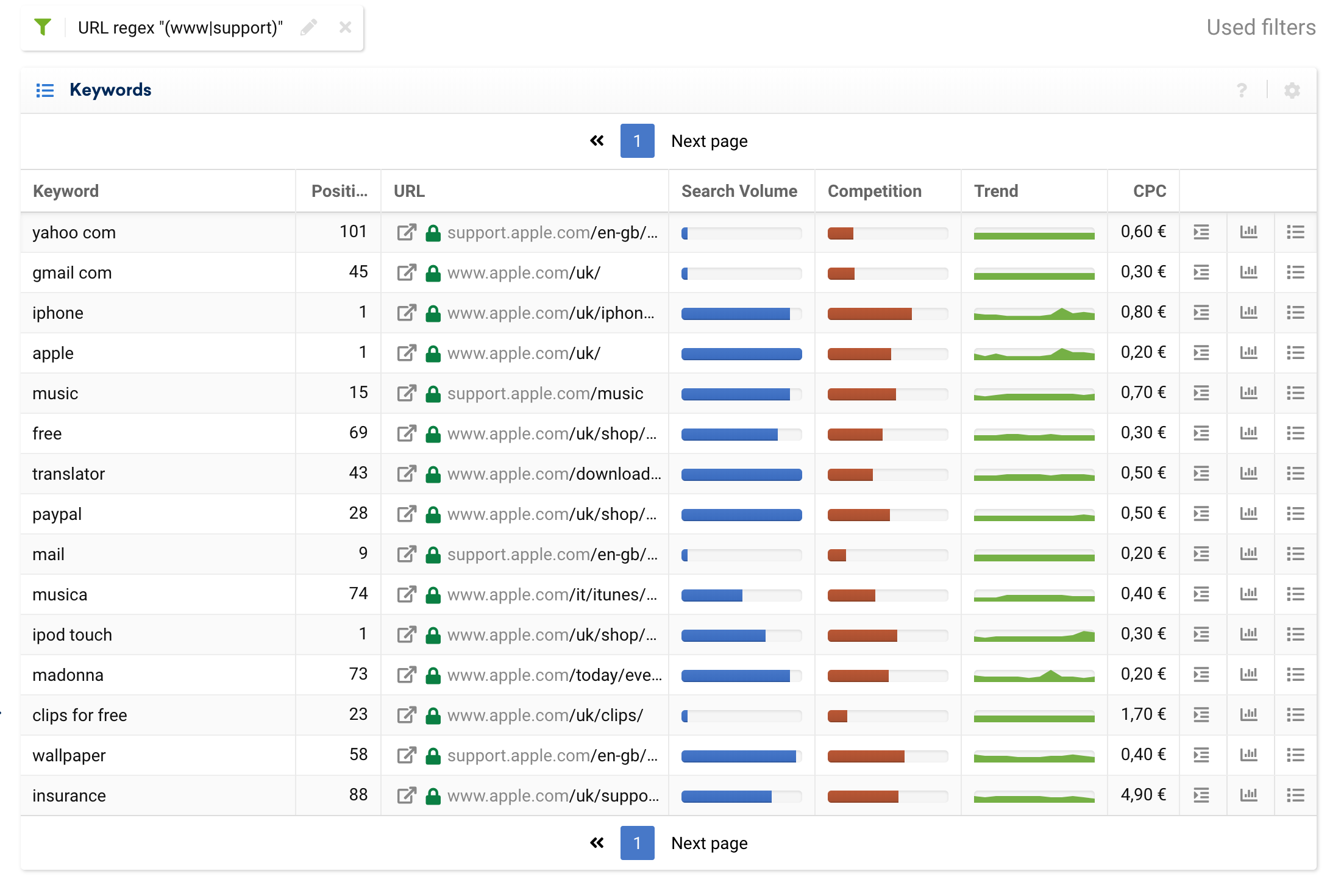
例如,我们可以使用排除过滤器来分离纯事务性子域,并忽略来自博客或常见问题解答的信息关键字。
^^(?!.*(www|support).*?) 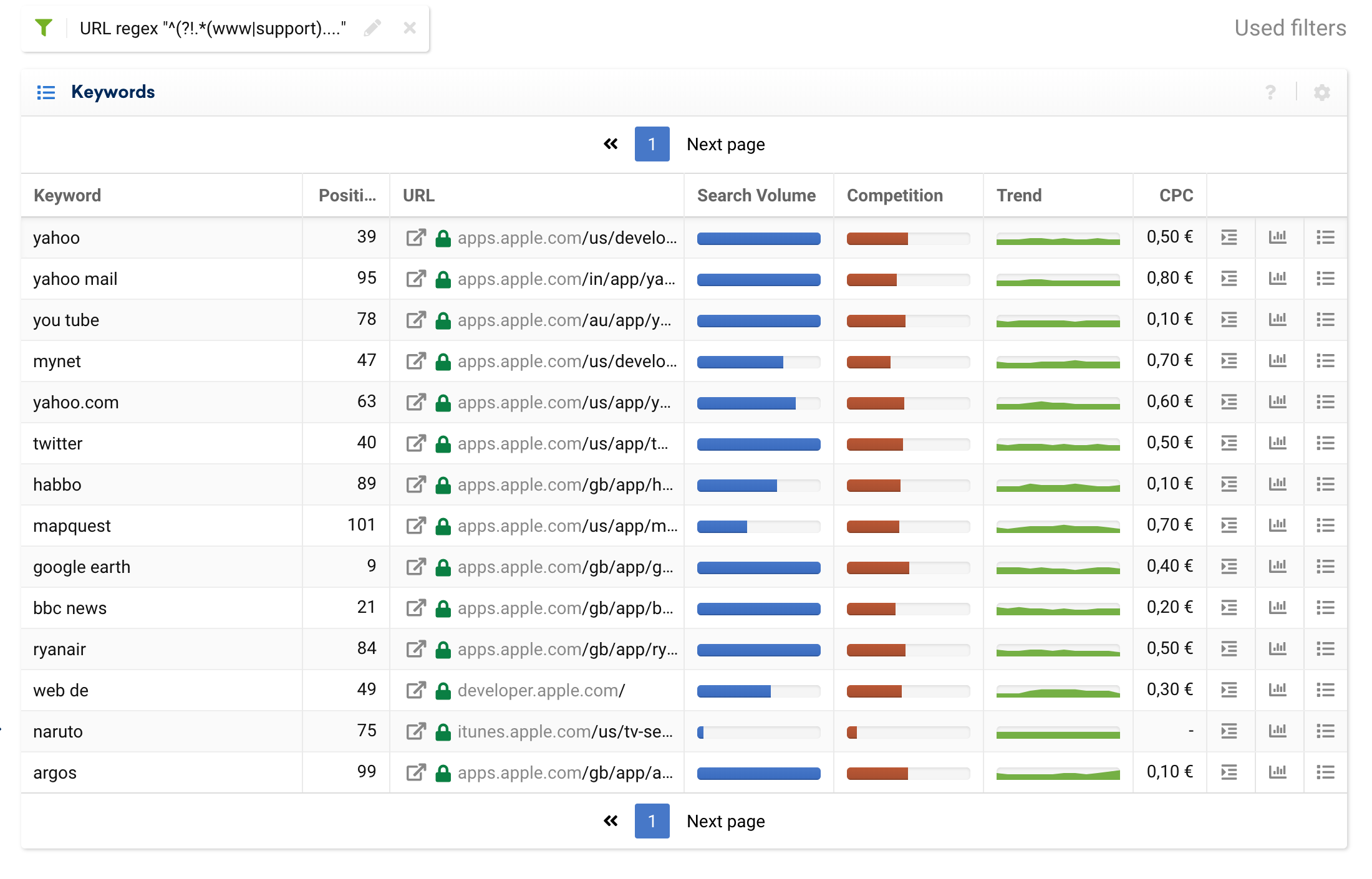
包括或排除以 / 结尾或不结尾的 URL
如果主页的 .com 域以斜线结尾,则可以调整正则表达式以匹配:
^.*.com/$ ^(?!(.*.com/$))任何以 / 结尾的 URL
.*/$我们也可以将这个正则表达式用于 URL,专门关注以斜杠 (/) 结尾的 URL。 为此,在搜索栏 (1) 中输入域,然后单击导航中的 URL (2),添加过滤器 (3) 并选择 URL 过滤器作为“正则表达式”(4):
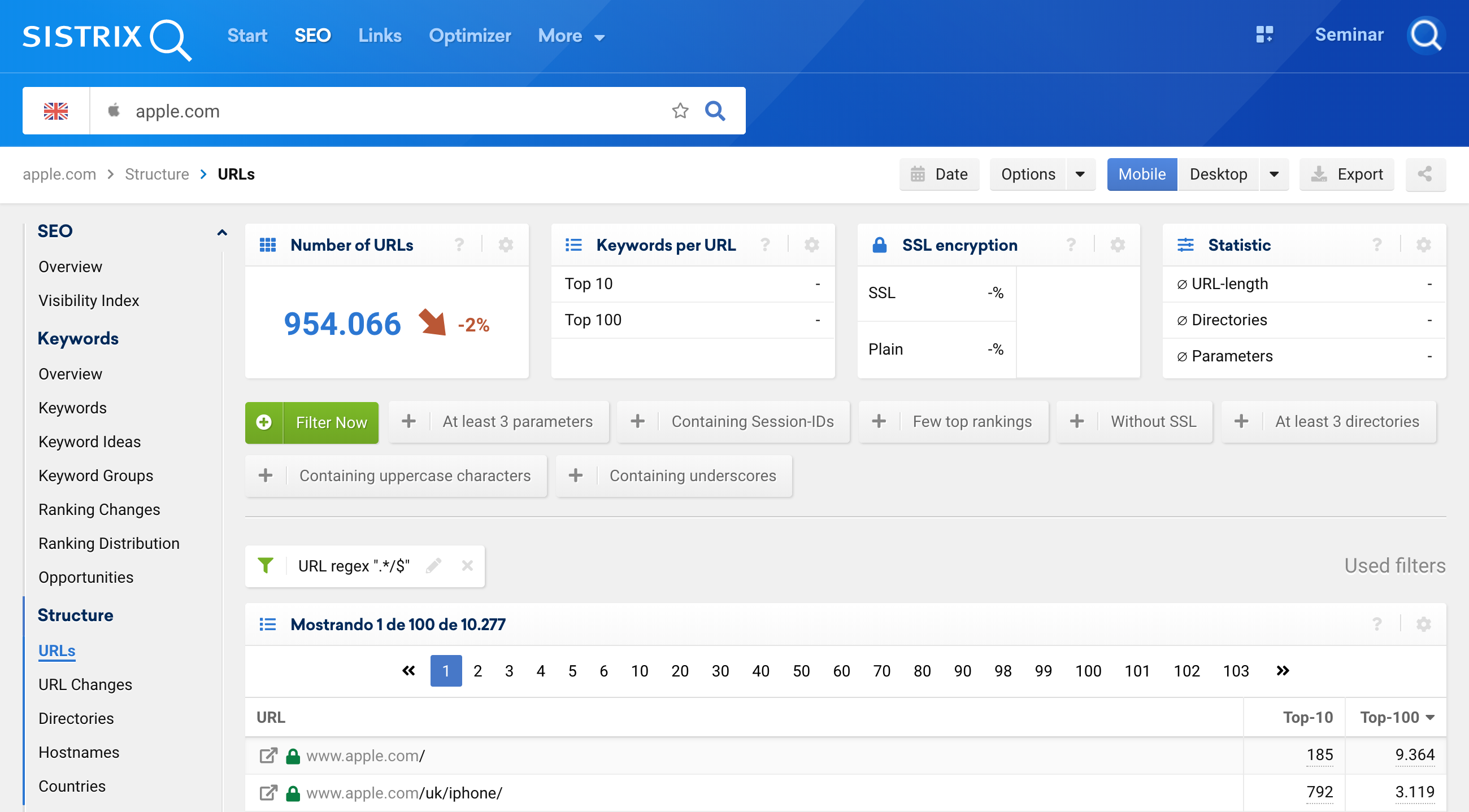
当然,这也适用于不以 / 结尾的 URL
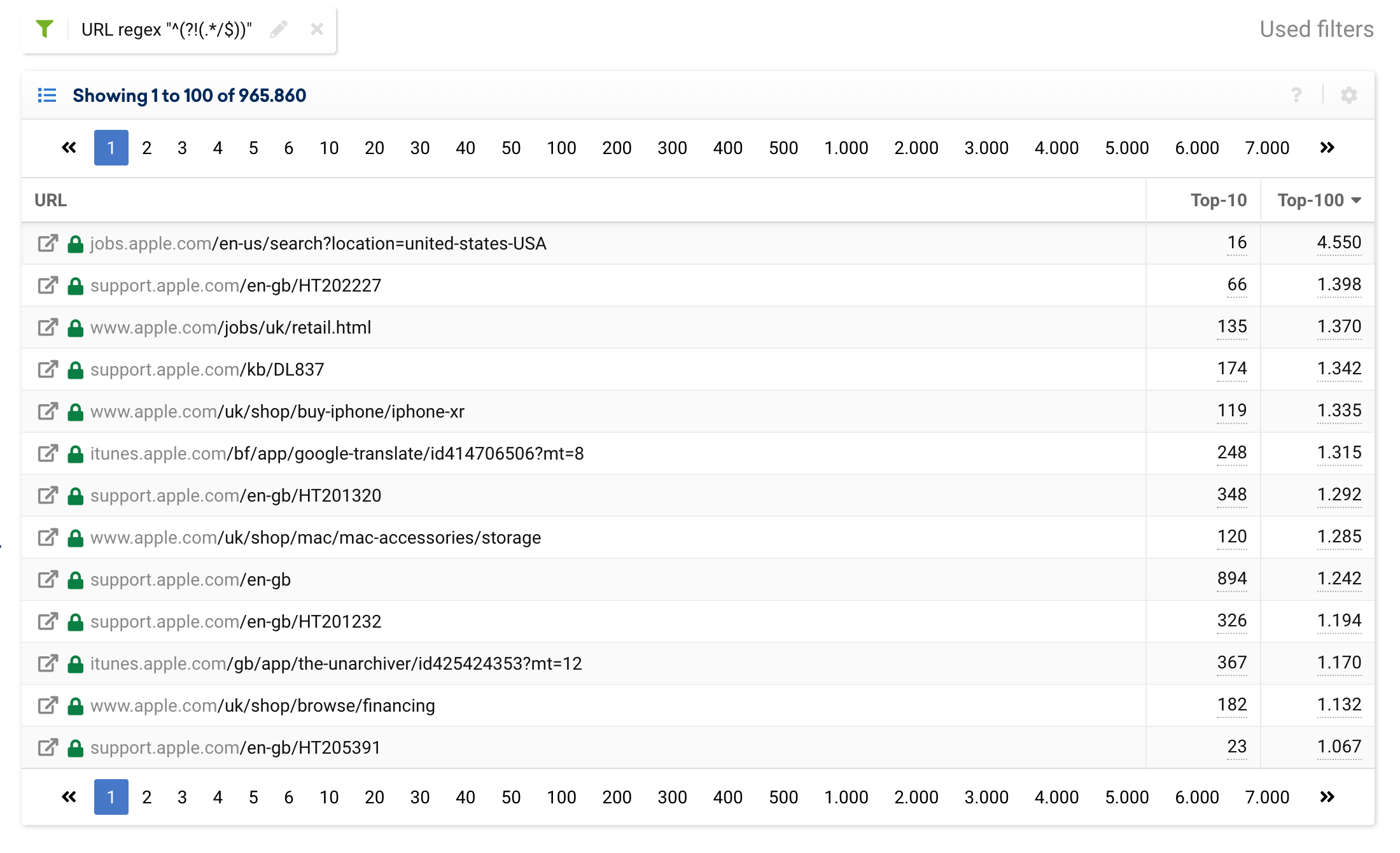
^(?!(.*/$)) 
包括或排除包含数字的 URL
我们可以修改 URL 语法来识别哪些包含数字以包含或排除它们:
.*-[0-9].* ^(?!(.*-[0-9].*))如果我们想要更具体的东西,并且我们知道有以特定数字结尾的 URL,我们还可以包括或排除它们,如下所示:
.*-[0-9]+$ ^(?!(.*-[0-9]+$))在这种情况下,我们的请求是过滤包含 8 个连续数字系列的链。
.*[0-9]{8}.html$ ^(?!(.*[0-9]{8}.html$))包含或排除特定格式的 URL
我们也可以使用 Regex 过滤 URL 格式。 例如,htm 或 html URL,以及 pdf URL。
这相当容易,因为我们可以依靠“结束于”或“包含”过滤器来做到这一点。
.*htm.?$ .*pdf$要排除所需的 URL 格式:
^(?!(.*html.?$).) ^(?!(.*pdf.?$).)我们可以在同一个表达式中使用多种格式,这将更有价值,并且可以省去连接多个过滤器的麻烦,包括:
.*(htm|html)$ .*(jpg|jpeg|gif|png)$我们还可以组合要排除的格式:
^(?!(.*(htm|html)$).) ^(?!(.*htm.?)$).) ^(?!(.*(jpg|jpeg|gif|png)$).)包含或排除与错误市场相关的 URL
我们可以监控不应出现在特定市场结果中的 URL。 例如,与美国、墨西哥或德国市场相关的 URL 出现在西班牙语的结果中。
以以下 URL 实例为基础:
西班牙的西班牙语 /es_es/
英国英语 /en_gb/
美国英语 /en_us/
意大利的意大利语 /it_it/
等等。
我们可以使用 Regex 来过滤不属于西班牙市场的 URL 数量。
^(?!(.*[es]_[az].*)|(.*[az]_[es].*).) ![hm.com 的 SISTRIX 工具箱中的关键字表,应用了正则表达式过滤器“^(?!(.*[es]_[a-z].*)|(.*[a-z]_[es].*).)” .](/uploads/article/246/TIPPU8qnSB57ontM.png)
如您所见,该表达式允许主页 URL,即语言选择器所在的位置。
为了进一步细化这个表达式并去掉主页,我们可以扩展它,如下所示:
^(?!(.*.com/$)|(.*[es]_[az].*)|(.*[az]_[es].*).) ![hm.com 的 SISTRIX 工具箱中的关键字表,带有正则表达式过滤器“^(?!(.*.com/$)|(.*[es]_[a-z].*)|(.*[a-z]_[ es].*).)”应用。](/uploads/article/246/vxYA4KacpOcflwYd.png)
概括
使用本文中提供的参数,您现在可以找到自己的用例,正则表达式可以派上用场,帮助您提高 SEO 分析效率。
您可以使用 https://www.Regextester.com/ 等工具或直接使用 SISTRIX 的 URL、关键字或片段过滤器继续测试和练习。
尽管我们不提供对 Regex 的支持,但我们将继续使用新的用例和 SEO 分析更新本教程,这些可能对您有用。