
วิธีจัดการกับ Bot Herding และ Spider Wrangling สำหรับการจัดอันดับ?
เผยแพร่แล้ว: 2020-01-23
โปรแกรมรวบรวมข้อมูลของ Google จัดทำดัชนีเนื้อหาทุกชิ้นที่คุณเผยแพร่บนเว็บไซต์ของคุณ โปรแกรมรวบรวมข้อมูลเหล่านี้เป็นซอฟต์แวร์ที่ตั้งโปรแกรมไว้ซึ่งติดตามลิงก์และโค้ด และส่งไปยังอัลกอริทึม จากนั้นอัลกอริทึมจะจัดทำดัชนีและเพิ่มเนื้อหาของคุณลงในฐานข้อมูลขนาดใหญ่ ด้วยวิธีนี้ เมื่อใดก็ตามที่ผู้ใช้ค้นหาคำหลัก เครื่องมือค้นหาจะแยกและจัดอันดับผลลัพธ์ที่เกี่ยวข้องจากฐานข้อมูลของหน้าที่จัดทำดัชนีไว้แล้ว
Google กำหนดงบประมาณการรวบรวมข้อมูลให้กับทุกเว็บไซต์ และโปรแกรมรวบรวมข้อมูลจะดำเนินการรวบรวมข้อมูลของเว็บไซต์ของคุณตามนั้น คุณต้องจัดการและใช้งบประมาณการรวบรวมข้อมูลเพื่อให้แน่ใจว่ามีการรวบรวมข้อมูลและจัดทำดัชนีอย่างชาญฉลาดสำหรับเว็บไซต์ของคุณทั้งหมด
ในโพสต์นี้ คุณสามารถเรียนรู้เกี่ยวกับกลเม็ดและเครื่องมือในการจัดการวิธีที่บ็อต/แมงมุมหรือโปรแกรมรวบรวมข้อมูลรวบรวมข้อมูลและจัดทำดัชนีเว็บไซต์ของคุณ
1. การเพิ่มประสิทธิภาพคำสั่ง Disallow สำหรับ Robot.txt:

Robots.txt เป็นไฟล์ข้อความที่มีไวยากรณ์ที่เข้มงวดซึ่งทำงานเหมือนเป็นแนวทางสำหรับสไปเดอร์เพื่อกำหนดวิธีการรวบรวมข้อมูลไซต์ของคุณ ไฟล์ robots.txt ถูกบันทึกไว้ในที่เก็บโฮสต์ของเว็บไซต์ของคุณจากตำแหน่งที่โปรแกรมรวบรวมข้อมูลค้นหา URL ในการเพิ่มประสิทธิภาพ Robots.txt หรือ "Robots Exclusion Protocol" คุณสามารถใช้เทคนิคบางอย่างที่สามารถช่วยให้ URL ของไซต์ของคุณได้รับการรวบรวมข้อมูลโดยโปรแกรมรวบรวมข้อมูลของ Google เพื่อให้มีการจัดอันดับที่สูงขึ้น
หนึ่งในกลอุบายเหล่านั้นคือการใช้ "คำสั่งที่ไม่อนุญาต" ซึ่งเหมือนกับการวางป้าย "พื้นที่จำกัด" ในส่วนเฉพาะของเว็บไซต์ของคุณ ในการเพิ่มประสิทธิภาพคำสั่ง Disallow คุณต้องเข้าใจแนวป้องกันแรก: “ตัวแทนผู้ใช้”
User-agent Directive คืออะไร?
ไฟล์ Robots.txt แต่ละไฟล์ประกอบด้วยกฎตั้งแต่หนึ่งกฎขึ้นไป และในบรรดากฎนั้น กฎ User-agent เป็นสิ่งสำคัญที่สุด กฎนี้ให้โปรแกรมรวบรวมข้อมูลสามารถเข้าถึงและไม่สามารถเข้าถึงรายการใดรายการหนึ่งบนเว็บไซต์ได้
ดังนั้น คำสั่ง user-agent จะใช้เพื่อระบุถึงโปรแกรมรวบรวมข้อมูลเฉพาะ และให้คำแนะนำเกี่ยวกับวิธีการดำเนินการรวบรวมข้อมูล
ประเภทของโปรแกรมรวบรวมข้อมูลของ Google ที่นิยมใช้:
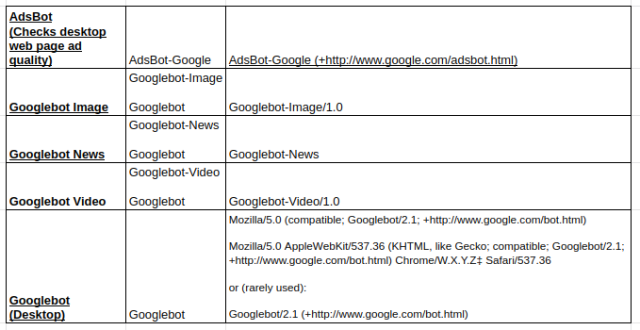
ไม่อนุญาตคำสั่ง:
หลังจากเรียนรู้เกี่ยวกับบอทที่ได้รับมอบหมายให้รวบรวมข้อมูลเว็บไซต์ของคุณแล้ว คุณสามารถเพิ่มประสิทธิภาพส่วนต่างๆ ของบอทได้ตามประเภทของ user-agent เคล็ดลับและตัวอย่างที่จำเป็นบางประการที่คุณสามารถปฏิบัติตามเพื่อเพิ่มประสิทธิภาพคำสั่งที่ไม่อนุญาตของเว็บไซต์ของคุณ ได้แก่
- ใช้ชื่อเต็มหน้าที่สามารถแสดงในเบราว์เซอร์เพื่อใช้สำหรับคำสั่งที่ไม่อนุญาต
- หากคุณต้องการเปลี่ยนเส้นทางโปรแกรมรวบรวมข้อมูลจากเส้นทางไดเรกทอรี ให้ใช้เครื่องหมาย “/”
- ใช้ * สำหรับคำนำหน้าพาธ คำต่อท้าย หรือสตริงทั้งหมด
ตัวอย่างของการใช้คำสั่ง disallow คือ:
# ตัวอย่างที่ 1: บล็อกเฉพาะ Googlebot
User-agent: Googlebot
ไม่อนุญาต: /
# ตัวอย่างที่ 2: บล็อก Googlebot และ Adsbot
User-agent: Googlebot
User-agent: AdsBot-Google
ไม่อนุญาต: /
# ตัวอย่างที่ 3: บล็อกทั้งหมดยกเว้นโปรแกรมรวบรวมข้อมูล AdsBot
ตัวแทนผู้ใช้: *
ไม่อนุญาต: /
2. คำสั่งที่ไม่ใช่ดัชนีสำหรับ Robots.txt:
เมื่อเว็บไซต์อื่นๆ เชื่อมโยงมายังไซต์ของคุณ มีโอกาสที่ URL ที่คุณไม่ต้องการให้โปรแกรมรวบรวมข้อมูลจัดทำดัชนีอาจถูกเปิดเผย เพื่อแก้ไขปัญหานี้ คุณสามารถใช้คำสั่งที่ไม่ใช่ดัชนี มาดูกันว่าเราจะนำคำสั่ง non-index ไปใช้กับ Robots.txt ได้อย่างไร:
มีสองวิธีในการใช้คำสั่งที่ไม่ใช่ดัชนีสำหรับเว็บไซต์ของคุณ:
<เมต้า> แท็ก:
เมตาแท็กเป็นส่วนย่อยของข้อความที่อธิบายเนื้อหาของหน้าเว็บของคุณในลักษณะที่มองเห็นได้สั้นๆ ซึ่งช่วยให้ผู้เยี่ยมชมทราบว่าจะเกิดอะไรขึ้น เราสามารถใช้สิ่งเดียวกันนี้เพื่อหลีกเลี่ยงไม่ให้โปรแกรมรวบรวมข้อมูลจัดทำดัชนีหน้าเว็บ
ขั้นแรก วางเมตาแท็ก “<meta name= “robots” content=” noindex”>” ในส่วน “<head>” ของหน้าเว็บที่คุณไม่ต้องการให้โปรแกรมรวบรวมข้อมูลจัดทำดัชนี
สำหรับโปรแกรมรวบรวมข้อมูลของ Google คุณสามารถใช้ “<meta name=”googlebot” content=”noindex”/>” ในส่วน “<head>”
เนื่องจากโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหาต่างๆ กำลังมองหาหน้าเว็บของคุณ พวกเขาจึงอาจตีความคำสั่งที่ไม่ใช่ดัชนีของคุณแตกต่างออกไป ด้วยเหตุนี้ หน้าของคุณจึงอาจปรากฏในผลการค้นหา
ดังนั้น จะช่วยได้หากคุณกำหนดคำสั่งสำหรับหน้าเว็บตามโปรแกรมรวบรวมข้อมูลหรือตัวแทนผู้ใช้
คุณสามารถใช้เมตาแท็กต่อไปนี้เพื่อใช้คำสั่งสำหรับโปรแกรมรวบรวมข้อมูลต่างๆ:
<ชื่อเมตา=”googlebot”เนื้อหา=”noindex”>
<meta name=”googlebot-news” content=”nosnippet”>
แท็ก X-Robots:
เราทุกคนทราบเกี่ยวกับส่วนหัว HTTP ที่ใช้เป็นการตอบสนองต่อคำขอข้อมูลเพิ่มเติมของไคลเอ็นต์หรือเครื่องมือค้นหาที่เกี่ยวข้องกับหน้าเว็บของคุณ เช่น ตำแหน่งหรือเซิร์ฟเวอร์ที่จัดหาให้ ในตอนนี้ เพื่อเพิ่มประสิทธิภาพการตอบกลับส่วนหัว HTTP เหล่านี้สำหรับคำสั่งที่ไม่ใช่ดัชนี คุณสามารถเพิ่มแท็ก X-Robots เป็นองค์ประกอบของการตอบสนองส่วนหัว HTTP สำหรับ URL ที่ระบุในเว็บไซต์ของคุณ
คุณสามารถรวมแท็ก X-Robots ต่างๆ กับการตอบสนองส่วนหัว HTTP ได้ คุณอาจระบุคำสั่งต่างๆ ในรายการโดยคั่นด้วยเครื่องหมายจุลภาค ด้านล่างนี้คือตัวอย่างการตอบสนองส่วนหัว HTTP ที่มีคำสั่งต่างๆ ร่วมกับแท็ก X-Robots
HTTP/1.1 200 ตกลง
วันที่: อ. 25 ม.ค. 2020 21:42:43 GMT
(…)
X-Robots-แท็ก: noarchive
X-Robots-Tag: ไม่พร้อมใช้งาน_หลัง: 25 ก.ค. 2020 15:00:00 PST
(…)
3. การเรียนรู้ลิงก์ Canonical: 
อะไรคือปัจจัยที่น่ากลัวที่สุดใน SEO ในปัจจุบัน? อันดับ? การจราจร? ไม่! เป็นความกลัวว่าเครื่องมือค้นหาจะลงโทษเว็บไซต์ของคุณสำหรับเนื้อหาที่ซ้ำกัน ดังนั้น ขณะที่คุณกำลังวางแผนงบประมาณการรวบรวมข้อมูล คุณต้องระวังไม่ให้เนื้อหาที่ซ้ำกันของคุณเปิดเผย

ที่นี่ การเรียนรู้ลิงก์ตามรูปแบบบัญญัติอย่างเชี่ยวชาญจะช่วยคุณจัดการกับปัญหาเนื้อหาที่ซ้ำกัน เนื้อหาที่ซ้ำกันของคำไม่ใช่ความหมาย ให้เรายกตัวอย่างสองหน้าของเว็บไซต์อีคอมเมิร์ซ:
ตัวอย่างเช่น คุณมีเว็บไซต์อีคอมเมิร์ซที่มีหน้าเพจที่เหมือนกันสำหรับนาฬิกาอัจฉริยะ และทั้งคู่มีเนื้อหาที่คล้ายคลึงกัน เมื่อบอทของเครื่องมือค้นหารวบรวมข้อมูล URL ของคุณ บอทจะตรวจสอบเนื้อหาที่ซ้ำกัน และอาจเลือก URL ใดก็ได้ หากต้องการเปลี่ยนเส้นทางไปยัง URL ที่จำเป็นสำหรับคุณ คุณสามารถตั้งค่าลิงก์ตามรูปแบบบัญญัติสำหรับหน้าต่างๆ ได้ มาดูกันว่าคุณจะทำอย่างไร:
- เลือกหน้าใดหน้าหนึ่งจากสองหน้าสำหรับเวอร์ชันตามรูปแบบบัญญัติของคุณ
- เลือกอันที่ได้รับผู้เข้าชมมากขึ้น
- ตอนนี้ให้เพิ่ม rel=”canonical” ในหน้าที่ไม่ใช่ Canonical ของคุณ
- เปลี่ยนเส้นทางลิงก์หน้าที่ไม่ใช่ Canonical ไปยังหน้า Canonical
- มันจะรวมลิงค์เพจทั้งสองของคุณเป็นลิงค์บัญญัติเดียว
4. โครงสร้างเว็บไซต์:
โปรแกรมรวบรวมข้อมูลจำเป็นต้องมีเครื่องหมายและป้ายเพื่อช่วยให้พวกเขาค้นพบ URL ที่สำคัญของเว็บไซต์ของคุณ และหากคุณไม่ได้จัดโครงสร้างเว็บไซต์ของคุณ โปรแกรมรวบรวมข้อมูลพบว่าเป็นการยากที่จะดำเนินการรวบรวมข้อมูลบน URL ของคุณ สำหรับสิ่งนี้ เราใช้แผนผังไซต์เนื่องจากมีการเชื่อมโยงไปยังหน้าที่สำคัญทั้งหมดของเว็บไซต์ของคุณแก่โปรแกรมรวบรวมข้อมูล
รูปแบบแผนผังเว็บไซต์มาตรฐานสำหรับเว็บไซต์หรือแม้แต่แอปที่พัฒนาผ่านกระบวนการพัฒนาแอปบนอุปกรณ์เคลื่อนที่ ได้แก่ แผนผังเว็บไซต์ XML, Atom และ RSS ในการเพิ่มประสิทธิภาพการรวบรวมข้อมูล คุณต้องรวมแผนผังเว็บไซต์ XML และฟีด RSS/Atom
- เนื่องจากแผนผังเว็บไซต์ XML ให้โปรแกรมรวบรวมข้อมูลมีเส้นทางไปยังหน้าทั้งหมดบนเว็บไซต์หรือแอปของคุณ
- และฟีด RSS/Atom จะให้ข้อมูลอัปเดตในหน้าเว็บไซต์แก่โปรแกรมรวบรวมข้อมูล
- เนื่องจากแผนผังเว็บไซต์ XML ให้โปรแกรมรวบรวมข้อมูลมีเส้นทางไปยังหน้าทั้งหมดบนเว็บไซต์หรือแอปของคุณ
5. การนำทางหน้า:
การนำทางเพจเป็นสิ่งจำเป็นสำหรับสไปเดอร์และแม้แต่ผู้เยี่ยมชมเว็บไซต์ของคุณ รองเท้าบู๊ตเหล่านี้ค้นหาหน้าในเว็บไซต์ของคุณ และโครงสร้างแบบลำดับชั้นที่กำหนดไว้ล่วงหน้าสามารถช่วยให้โปรแกรมรวบรวมข้อมูลค้นหาหน้าที่มีความสำคัญต่อเว็บไซต์ของคุณ ขั้นตอนอื่นๆ ที่ควรปฏิบัติตามเพื่อการนำทางเพจที่ดีขึ้นคือ:
- เก็บการเข้ารหัสใน HTML หรือ CSS
- จัดเรียงหน้าของคุณตามลำดับชั้น
- ใช้โครงสร้างเว็บไซต์แบบตื้นเพื่อการนำทางหน้าที่ดีขึ้น
- รักษาเมนูและแท็บที่ส่วนหัวให้น้อยที่สุดและเฉพาะเจาะจง
- จะช่วยให้การนำทางหน้าทำได้ง่ายขึ้น
6.หลีกเลี่ยงกับดักแมงมุม:
กับดักแมงมุมคือ URL ที่ไม่มีที่สิ้นสุดซึ่งชี้ไปยังเนื้อหาเดียวกันในหน้าเดียวกันเมื่อโปรแกรมรวบรวมข้อมูลรวบรวมข้อมูลเว็บไซต์ของคุณ นี้เป็นเหมือนการยิงช่องว่าง ในที่สุด มันจะกินงบประมาณการรวบรวมข้อมูลของคุณ ปัญหานี้บานปลายทุกครั้งที่มีการรวบรวมข้อมูล และเว็บไซต์ของคุณถือว่ามีเนื้อหาที่ซ้ำกัน เนื่องจากทุก URL ที่รวบรวมข้อมูลในกับดักจะไม่ซ้ำกัน
คุณสามารถทำลายกับดักได้โดยการบล็อกส่วนนั้นผ่าน Robots.txt หรือใช้หนึ่งใน คำสั่งติดตามหรือไม่ติดตาม เพื่อบล็อกบางหน้า สุดท้าย คุณสามารถแก้ไขปัญหาในทางเทคนิคได้โดยการหยุดการเกิด URL ที่ไม่มีที่สิ้นสุด
7. โครงสร้างการเชื่อมโยง:
การเชื่อมโยงกันเป็นส่วนสำคัญของการเพิ่มประสิทธิภาพการรวบรวมข้อมูล โปรแกรมรวบรวมข้อมูลสามารถค้นหาหน้าเว็บของคุณได้ดีขึ้นด้วยลิงก์ที่มีโครงสร้างดีทั่วทั้งเว็บไซต์ของคุณ เคล็ดลับสำคัญบางประการในโครงสร้างการเชื่อมโยงที่ยอดเยี่ยมคือ:
- การใช้ลิงก์ข้อความ เนื่องจากเครื่องมือค้นหารวบรวมข้อมูลได้ง่าย: <a href=”new-page.html”>ลิงก์ข้อความ</a>
- การใช้คำอธิบายของ anchor text ในลิงก์ของคุณ
- สมมติว่าคุณเปิดเว็บไซต์ยิม และต้องการลิงก์วิดีโอยิมทั้งหมดของคุณ คุณสามารถใช้ลิงก์แบบนี้ เรียกดู<a href=”videos.html”>วิดีโอยิม</a>ของเราได้ตามสบาย
8. ความสุข HTML:
การทำความสะอาดเอกสาร HTML และการรักษาขนาดเพย์โหลดของเอกสาร HTML ให้น้อยที่สุดเป็นสิ่งสำคัญ เนื่องจากช่วยให้โปรแกรมรวบรวมข้อมูลรวบรวมข้อมูล URL ได้อย่างรวดเร็ว ข้อดีอีกประการของการเพิ่มประสิทธิภาพ HTML คือเซิร์ฟเวอร์ของคุณมีการโหลดจำนวนมากเนื่องจากการรวบรวมข้อมูลหลายครั้งโดยเครื่องมือค้นหา และสิ่งนี้อาจทำให้การโหลดหน้าเว็บของคุณช้าลง ซึ่งไม่ใช่สัญญาณที่ดีสำหรับ SEO หรือการรวบรวมข้อมูลของเครื่องมือค้นหา การเพิ่มประสิทธิภาพ HTML สามารถลดภาระการรวบรวมข้อมูลบนเซิร์ฟเวอร์ ทำให้การโหลดหน้าเว็บรวดเร็ว นอกจากนี้ยังช่วยในการแก้ไขข้อผิดพลาดในการรวบรวมข้อมูลเนื่องจากการหมดเวลาของเซิร์ฟเวอร์หรือปัญหาสำคัญอื่นๆ
9. ฝังมันง่าย:
ไม่มีเว็บไซต์ใดในปัจจุบันที่จะนำเสนอเนื้อหาโดยไม่มีรูปภาพและวิดีโอที่ยอดเยี่ยมสำรองเนื้อหา เนื่องจากเป็นสิ่งที่ทำให้เนื้อหาดูน่าดึงดูดยิ่งขึ้นและหาได้สำหรับโปรแกรมรวบรวมข้อมูลของเครื่องมือค้นหา แต่ถ้าเนื้อหาที่ฝังนี้ไม่ได้รับการปรับให้เหมาะสม ก็สามารถลดความเร็วในการโหลด ขับให้โปรแกรมรวบรวมข้อมูลห่างจากเนื้อหาของคุณที่สามารถจัดอันดับได้
ในที่นี้ การใช้ HTML สำหรับเนื้อหาที่ฝังไว้ของคุณจะช่วยให้รวบรวมข้อมูลจากเครื่องมือค้นหาได้ดียิ่งขึ้น เทคโนโลยีต่างๆ เช่น AJAX, Javascript เป็นต้น ค่อนข้างดีในการให้บริการคุณลักษณะใหม่ๆ แต่ก็ทำให้เครื่องมือค้นหารวบรวมข้อมูลค่อนข้างยุ่งยาก
บทสรุป:
เจ้าของเว็บไซต์ทุกคนต่างมองหาวิธีที่ดีกว่าในการจัดการกับบอทต้อนและการทะเลาะวิวาทด้วยการให้ความสำคัญกับ SEO มากขึ้นและปริมาณการใช้งานที่สูงขึ้น แต่โซลูชันอยู่ในการเพิ่มประสิทธิภาพแบบละเอียดที่คุณต้องทำในเว็บไซต์ของคุณและการรวบรวมข้อมูล URL ที่สามารถทำให้เครื่องมือค้นหารวบรวมข้อมูลเฉพาะเจาะจงมากขึ้นและปรับให้เหมาะสมเพื่อแสดงสิ่งที่ดีที่สุดของเว็บไซต์ของคุณที่สามารถอยู่ในอันดับที่สูงขึ้นในหน้าผลลัพธ์ของเครื่องมือค้นหา