
Como lidar com bot Herding e Spider Wrangling para classificações?
Publicados: 2020-01-23
Os rastreadores do Google indexam cada parte do conteúdo que você publica em seu site. Esses rastreadores são softwares programados que seguem links e códigos e os entregam a um algoritmo. Em seguida, o algoritmo o indexa e adiciona seu conteúdo a um vasto banco de dados. Dessa forma, sempre que um usuário pesquisa uma palavra-chave, o mecanismo de pesquisa extrai e classifica os resultados relacionados do banco de dados de páginas já indexadas.
O Google atribui um orçamento de rastreamento a cada site e os rastreadores executam o rastreamento do seu site de acordo. Você deve gerenciar e utilizar o orçamento de rastreamento para garantir o rastreamento e a indexação inteligentes de todo o seu site.
Neste post, você pode aprender sobre os truques e ferramentas para lidar com como os robôs/spiders ou rastreadores dos mecanismos de pesquisa rastreiam e indexam seu site.
1. Otimização da Diretiva Não Permitir para Robot.txt:

Robots.txt é um arquivo de texto com uma sintaxe estrita que funciona como um guia para os spiders determinarem como rastrear seu site. Um arquivo robots.txt é salvo nos repositórios do host do seu site de onde os rastreadores procuram os URLs. Para otimizar esses Robots.txt ou “Protocolo de exclusão de robôs”, você pode usar alguns truques que podem ajudar os URLs do seu site a serem rastreados pelos rastreadores do Google para classificações mais altas.
Um desses truques é usar uma “Diretiva de Proibição” , é como colocar uma placa de “Área Restrita” em seções específicas do seu site. Para otimizar a Diretiva de Proibição, você deve entender a primeira linha de defesa: “User-agents”.
O que é uma Diretiva User-Agent?
Cada arquivo Robots.txt consiste em uma ou mais regras e dentre elas, a regra do agente do usuário é a mais importante. Essa regra fornece aos rastreadores acesso e não acesso a uma lista específica no site.
Portanto, a diretiva user-agent é usada para endereçar um rastreador específico e fornecer instruções sobre como executar o rastreamento.
Tipos de rastreadores do Google usados popularmente:
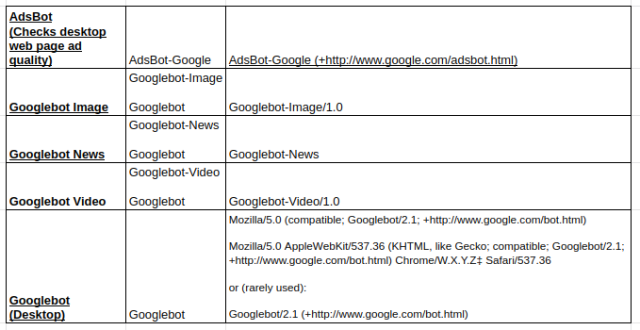
Diretiva de não permissão:
Agora, depois de aprender sobre o bot atribuído para rastrear seu site, você pode otimizar diferentes seções dele com base no tipo de agente do usuário. Alguns truques e exemplos essenciais que você pode seguir para otimizar a diretiva não permitir do seu site são:
- Use um nome de página completo que possa ser mostrado no navegador para ser usado para a diretiva não permitir.
- Se você quiser redirecionar o rastreador de um caminho de diretório, use uma marca “/”.
- Use * para prefixo de caminho, sufixo ou uma string inteira.
Exemplos de uso das diretivas disallow são:
# Exemplo 1: bloquear apenas o Googlebot
Agente do usuário: Googlebot
Não permitir: /
# Exemplo 2: bloquear o Googlebot e o Adsbot
Agente do usuário: Googlebot
Agente do usuário: AdsBot-Google
Não permitir: /
# Exemplo 3: bloquear todos os rastreadores, exceto AdsBot
Agente de usuário: *
Não permitir: /
2. Uma diretiva não indexada para Robots.txt:
Quando outros sites vinculam ao seu site, há chances de que o URL, que você não deseja que o rastreador indexe, possa ser exposto. Para superar esse problema, você pode usar uma diretiva que não seja de índice. Vamos ver como podemos aplicar a diretiva non-index ao Robots.txt:
Existem dois métodos para aplicar uma diretiva não indexada ao seu site:
Etiquetas <Meta>:
Meta tags são os trechos de texto que descrevem o conteúdo da sua página de uma forma curta e transparente que permite que os visitantes saibam o que está por vir? Podemos usar o mesmo para evitar que os rastreadores indexem a página.
Primeiro, coloque uma meta tag “<meta name= “robots” content=” noindex”>” na seção “<head>” de sua página que você não deseja que os rastreadores indexem.
Para rastreadores do Google, você pode usar "<meta name="googlebot" content="noindex"/>" na seção "<head>".
Como diferentes rastreadores de mecanismos de pesquisa estão procurando suas páginas, eles podem interpretar sua diretiva não indexada de maneira diferente. Devido a isso, suas páginas podem aparecer nos resultados da pesquisa.
Portanto, ajudaria se você definisse diretivas para páginas de acordo com os rastreadores ou agentes do usuário.
Você pode usar as seguintes metatags para aplicar a diretiva para diferentes rastreadores:
<meta name="googlebot" content="noindex">
<meta name="googlebot-news" content="nosnippet">
Etiqueta X-Robots:
Todos nós sabemos sobre os cabeçalhos HTTP que são usados como respostas à solicitação do cliente ou do mecanismo de pesquisa para obter informações extras relacionadas às suas páginas da web, como localização ou servidor que as fornece. Agora, para otimizar essas respostas de cabeçalho HTTP para a diretiva não indexada, você pode adicionar tags X-Robots como um elemento da resposta de cabeçalho HTTP para qualquer URL do seu site.
Você pode combinar diferentes tags X-Robots com as respostas do cabeçalho HTTP. Você pode especificar várias diretivas em uma lista separada por uma vírgula. Abaixo está um exemplo de uma resposta de cabeçalho HTTP com diferentes diretivas combinadas com tags X-Robots.
HTTP/1.1 200 OK
Data: Ter, 25 de janeiro de 2020 21:42:43 GMT
(…)
X-Robots-Tag: noarchive
X-Robots-Tag: indisponível_após: 25 de julho de 2020 15:00:00 PST
(…)
3. Dominando os Links Canônicos: 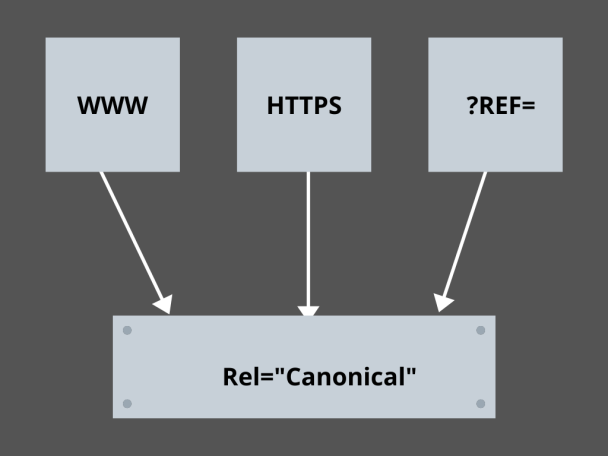
Qual é o fator mais temido em SEO hoje? Classificações? Tráfego? Não! É o medo dos motores de busca penalizarem o seu site por conteúdo duplicado. Então, enquanto você está planejando seu orçamento de rastreamento, você precisa ter cuidado para não expor seu conteúdo duplicado.

Aqui, dominar seus links canônicos ajudará você a lidar com seus problemas de conteúdo duplicado. A palavra conteúdo duplicado não é o que significa. Vamos dar um exemplo de duas páginas de um site de comércio eletrônico:
Por exemplo, você tem um site de comércio eletrônico com um par de páginas idênticas para um smartwatch e ambos têm conteúdo semelhante. Quando os bots do mecanismo de pesquisa rastreiam seu URL, eles verificam se há conteúdo duplicado e podem escolher qualquer um dos URLs. Para redirecioná-los para a URL que é essencial para você, um link canônico pode ser definido para as páginas. Vamos ver como você pode fazer isso:
- Escolha qualquer página das duas páginas para sua versão canônica.
- Escolha aquele que recebe mais visitantes.
- Agora adicione rel=”canonical” à sua página não canônica.
- Redirecione o link da página não canônica para a página canônica.
- Ele mesclará os dois links da sua página como um único link canônico.
4. Estruturação do Site:
Os rastreadores precisam de marcadores e placas de sinalização para ajudá-los a descobrir os URLs importantes do seu site e, se você não estruturar seu site, os rastreadores terão dificuldade em executar o rastreamento em seus URLs. Para isso, usamos sitemaps porque eles fornecem aos rastreadores links para todas as páginas importantes do seu site.
Os formatos padrão de mapa de site para sites ou até mesmo aplicativos desenvolvidos por meio de processos de desenvolvimento de aplicativos móveis são mapas de site XML, Atom e RSS. Para otimizar o rastreamento, você precisa combinar mapas de site XML e feeds RSS/Atom.
- Como os sitemaps XML fornecem aos rastreadores direções para todas as páginas do seu site ou aplicativo.
- E o feed RSS/Atom fornece atualizações em suas páginas do site para rastreadores.
- Como os sitemaps XML fornecem aos rastreadores direções para todas as páginas do seu site ou aplicativo.
5. Navegações de página:
A navegação na página é essencial para os spiders e até mesmo para os visitantes do seu site. Essas botas procuram páginas em seu site e uma estrutura hierárquica predefinida pode ajudar os rastreadores a encontrar páginas importantes para seu site. Outras etapas a serem seguidas para uma melhor navegação na página são:
- Mantenha a codificação em HTML ou CSS.
- Organize hierarquicamente suas páginas.
- Use uma estrutura de site superficial para uma melhor navegação na página.
- Mantenha o menu e as guias no cabeçalho mínimos e específicos.
- Isso ajudará a navegação na página a ser mais fácil.
6.Evitando as Armadilhas de Aranhas:
As armadilhas de aranha são URLs infinitos que apontam para o mesmo conteúdo nas mesmas páginas quando os rastreadores rastreiam seu site. Isso é mais como atirar em branco. Em última análise, isso consumirá seu orçamento de rastreamento. Esse problema aumenta a cada rastreamento, e seu site é considerado como tendo conteúdo duplicado, pois cada URL rastreado na armadilha não será exclusivo.
Você pode quebrar a armadilha bloqueando a seção por meio do Robots.txt ou usar uma das diretivas seguir ou não seguir para bloquear páginas específicas. Por fim, você pode tentar corrigir o problema tecnicamente interrompendo a ocorrência de URLs infinitas.
7. Estrutura de Ligação:
A interligação é uma das partes essenciais da otimização de rastreamento. Os rastreadores podem encontrar melhor suas páginas com links bem estruturados em todo o site. Alguns dos principais truques para uma ótima estrutura de links são:
- Uso de links de texto, pois os mecanismos de pesquisa os rastreiam facilmente: <a href=”new-page.html”>link de texto</a>
- Uso de texto âncora descritivo em seus links
- Suponha que você tenha um site de academia e queira vincular todos os seus vídeos de academia, você pode usar um link como este - Sinta-se à vontade para navegar em todos os nossos <a href="videos.html">vídeos de academia</a>.
8. Felicidade HTML:
Limpar seus documentos HTML e manter o tamanho mínimo da carga útil dos documentos HTML é importante, pois permite que os rastreadores rastreiem os URLs rapidamente. Outra vantagem da otimização de HTML é que seu servidor fica muito carregado devido a vários rastreamentos pelos mecanismos de pesquisa, e isso pode diminuir o carregamento da página, o que não é um ótimo sinal para SEO ou rastreamento do mecanismo de pesquisa. A otimização de HTML pode reduzir a carga de rastreamento no servidor, mantendo o carregamento da página rápido. Também ajuda a resolver os erros de rastreamento devido a tempos limite do servidor ou outros problemas vitais.
9. Incorpore de forma simples:
Nenhum site hoje oferecerá conteúdo sem ótimas imagens e vídeos de backup do conteúdo, pois é isso que torna seu conteúdo visualmente mais atraente e acessível para os rastreadores dos mecanismos de pesquisa. Mas, se esse conteúdo incorporado não for otimizado, pode reduzir a velocidade de carregamento, afastando os rastreadores do seu conteúdo que pode ser classificado.
Aqui, manter o HTML para seu conteúdo incorporado pode ajudar a obter um rastreamento melhor dos mecanismos de pesquisa. Tecnologias como AJAX, Javascript, etc. são muito boas em fornecer novos recursos, mas também tornam o rastreamento dos mecanismos de pesquisa bastante complicado.
Conclusão:
Com mais foco em SEO e maior tráfego, todos os proprietários de sites estão procurando melhores maneiras de lidar com o agrupamento de bots e as disputas de aranhas. Mas as soluções estão nas otimizações granulares que você precisa fazer em seu site e no rastreamento de URLs que podem tornar o rastreamento do mecanismo de pesquisa mais específico e otimizado para representar o melhor do seu site que pode ter uma classificação mais alta nas páginas de resultados do mecanismo de pesquisa.