
Comment gérer l'élevage de bots et les querelles d'araignées pour les classements ?
Publié: 2020-01-23
Les robots d'exploration de Google indexent chaque élément de contenu que vous publiez sur votre site Web. Ces robots sont des logiciels programmés qui suivent des liens et des codes et les transmettent à un algorithme. Ensuite, l'algorithme l'indexe et ajoute votre contenu à une vaste base de données. De cette façon, chaque fois qu'un utilisateur recherche un mot-clé, le moteur de recherche extrait et classe les résultats associés de la base de données des pages déjà indexées.
Google attribue un budget d'exploration à chaque site Web et les robots exécutent l'exploration de votre site en conséquence. Vous devez gérer et utiliser le budget d'exploration pour assurer une exploration et une indexation intelligentes de l'ensemble de votre site Web.
Dans cet article, vous pouvez découvrir les astuces et les outils pour gérer la façon dont les robots/araignées ou les robots des moteurs de recherche explorent et indexent votre site Web.
1. Optimisation de la directive Disallow pour Robot.txt :

Robots.txt est un fichier texte avec une syntaxe stricte qui fonctionne comme un guide pour les araignées pour déterminer comment explorer votre site. Un fichier robots.txt est enregistré dans les référentiels hôtes de votre site Web à partir desquels les robots recherchent les URL. Pour optimiser ces Robots.txt ou "Robots Exclusion Protocol", vous pouvez utiliser quelques astuces qui peuvent aider les URL de votre site à être explorées par les robots d'exploration Google pour un meilleur classement.
L'une de ces astuces consiste à utiliser une "directive d'interdiction" , c'est comme mettre un panneau de "zone restreinte" sur des sections spécifiques de votre site Web. Pour optimiser la directive Disallow, vous devez comprendre la première ligne de défense : "User-agents".
Qu'est-ce qu'une directive utilisateur-agent ?
Chaque fichier Robots.txt se compose d'une ou plusieurs règles et parmi elles, la règle de l'agent utilisateur est la plus importante. Cette règle fournit aux robots d'exploration un accès et un non-accès à une liste particulière sur le site Web.
Ainsi, la directive user-agent est utilisée pour s'adresser à un crawler spécifique et lui donner des instructions sur la façon d'exécuter le crawl.
Types de robots d'exploration Google couramment utilisés :
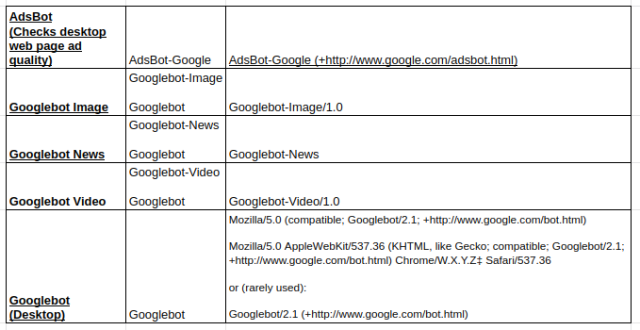
Interdire la directive :
Maintenant, après avoir pris connaissance du bot qui est chargé d'explorer votre site Web, vous pouvez en optimiser différentes sections en fonction du type d'agent utilisateur. Voici quelques astuces et exemples essentiels que vous pouvez suivre pour optimiser la directive d'interdiction de votre site Web :
- Utilisez un nom de page complet qui peut être affiché dans le navigateur à utiliser pour la directive d'interdiction.
- Si vous souhaitez rediriger le robot à partir d'un chemin de répertoire, utilisez une marque "/".
- Utilisez * pour le préfixe de chemin, le suffixe ou une chaîne entière.
Voici des exemples d'utilisation des directives d'interdiction :
# Exemple 1 : Bloquer uniquement Googlebot
Agent utilisateur : Googlebot
Interdire : /
# Exemple 2 : Bloquer Googlebot et Adsbot
Agent utilisateur : Googlebot
Agent utilisateur : AdsBot-Google
Interdire : /
# Exemple 3 : Bloquer tous les robots d'exploration sauf AdsBot
Agent utilisateur: *
Interdire : /
2. Une directive sans index pour Robots.txt :
Lorsque d'autres sites Web renvoient vers votre site, il est possible que l'URL, que vous ne souhaitez pas que le robot indexe, soit exposée. Pour résoudre ce problème, vous pouvez utiliser une directive non indexée. Voyons, comment pouvons-nous appliquer la directive non-index à Robots.txt :
Il existe deux méthodes pour appliquer une directive non indexée à votre site Web :
Balises <méta> :
Les balises Meta sont les extraits de texte qui décrivent le contenu de votre page d'une manière courte et transparente qui permet aux visiteurs de savoir ce qui va arriver ? Nous pouvons utiliser la même chose pour éviter que les robots n'indexent la page.
Tout d'abord, placez une balise méta "<meta name= "robots" content=" noindex">" dans la section "<head>" de votre page que vous ne voulez pas que les robots indexent.
Pour les robots d'exploration Google, vous pouvez utiliser "<meta name="googlebot" content="noindex"/>" dans la section "<head>".
Étant donné que différents robots d'exploration des moteurs de recherche recherchent vos pages, ils peuvent interpréter différemment votre directive de non-indexation. Pour cette raison, vos pages peuvent apparaître dans les résultats de recherche.
Il serait donc utile de définir des directives pour les pages en fonction des robots d'exploration ou des agents utilisateurs.
Vous pouvez utiliser les balises Meta suivantes pour appliquer la directive à différents robots d'exploration :
<meta name=”googlebot” content=”noindex”>
<meta name=”googlebot-news” content=”nosnippet”>
Balise X-Robots :
Nous connaissons tous les en-têtes HTTP qui sont utilisés comme réponses à la demande du client ou du moteur de recherche pour des informations supplémentaires liées à vos pages Web, comme l'emplacement ou le serveur qui les fournit. Maintenant, pour optimiser ces réponses d'en-tête HTTP pour la directive non-index, vous pouvez ajouter des balises X-Robots en tant qu'élément de la réponse d'en-tête HTTP pour n'importe quelle URL donnée de votre site Web.
Vous pouvez combiner différentes balises X-Robots avec les réponses d'en-tête HTTP. Vous pouvez spécifier différentes directives dans une liste séparées par une virgule. Vous trouverez ci-dessous un exemple de réponse d'en-tête HTTP avec différentes directives combinées avec des balises X-Robots.
HTTP/1.1 200 OK
Date : mar. 25 janvier 2020 21:42:43 GMT
(…)
X-Robots-Tag : pas d'archive
X-Robots-Tag : non disponible_après : 25 juillet 2020 15:00:00 PST
(…)
3. Maîtriser les Liens Canoniques : 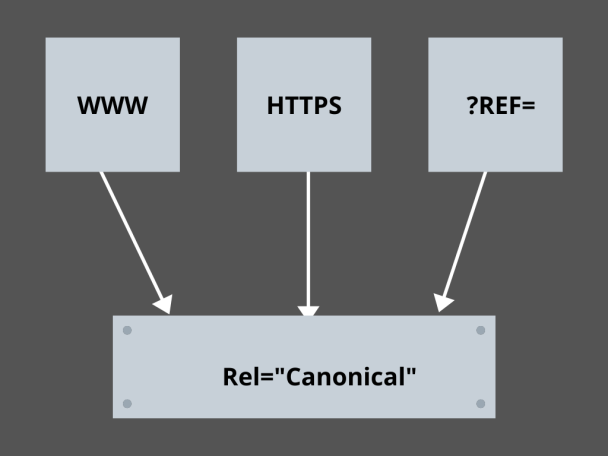
Quel est le facteur le plus redouté en SEO aujourd'hui ? Classements ? Trafic? Non! C'est la peur que les moteurs de recherche pénalisent votre site Web pour le contenu dupliqué. Ainsi, pendant que vous élaborez une stratégie pour votre budget de crawl, vous devez faire attention à ne pas exposer votre contenu dupliqué.

Ici, maîtriser vos liens canoniques vous aidera à gérer vos problèmes de contenu dupliqué. Le mot contenu dupliqué n'est pas ce qu'il signifie. Prenons l'exemple de deux pages d'un site e-commerce :
Par exemple, vous avez un site Web de commerce électronique avec une paire de pages identiques pour une smartwatch, et les deux ont un contenu similaire. Lorsque les robots des moteurs de recherche analysent votre URL, ils vérifient le contenu en double et peuvent choisir n'importe laquelle des URL. Pour les rediriger vers l'URL qui vous est indispensable, un lien canonique peut être défini pour les pages. Voyons comment pouvez-vous le faire:
- Choisissez une page parmi les deux pages pour votre version canonique.
- Choisissez celui qui reçoit le plus de visiteurs.
- Ajoutez maintenant rel="canonical" à votre page non canonique.
- Redirigez le lien de la page non canonique vers la page canonique.
- Il fusionnera les deux liens de votre page en un seul lien canonique.
4. Structuration du Site :
Les robots ont besoin de marqueurs et de panneaux pour les aider à découvrir les URL importantes de votre site, et si vous ne structurez pas votre site Web, les robots ont du mal à exécuter le crawl sur vos URL. Pour cela, nous utilisons des sitemaps car ils fournissent aux robots des liens vers toutes les pages importantes de votre site Web.
Les formats de plan de site standard pour les sites Web ou même les applications développées via des processus de développement d'applications mobiles sont les plans de site XML, Atom et RSS. Pour optimiser l'exploration, vous devez combiner des sitemaps XML et des flux RSS/Atom.
- Comme les sitemaps XML fournissent aux crawlers des directions vers toutes les pages de votre site Web ou de votre application.
- Et le flux RSS/Atom fournit des mises à jour dans vos pages du site Web aux robots.
- Comme les sitemaps XML fournissent aux crawlers des directions vers toutes les pages de votre site Web ou de votre application.
5. Navigations de pages :
La navigation dans les pages est essentielle pour les araignées et même pour les visiteurs de votre site Web. Ces bottes recherchent des pages sur votre site Web et une structure hiérarchique prédéfinie peut aider les robots d'exploration à trouver des pages importantes pour votre site Web. Les autres étapes à suivre pour une meilleure navigation dans les pages sont :
- Gardez le codage en HTML ou CSS.
- Organisez vos pages de manière hiérarchique.
- Utilisez une structure de site Web peu profonde pour une meilleure navigation dans les pages.
- Gardez le menu et les onglets de l'en-tête minimaux et spécifiques.
- Cela aidera la navigation de la page à être plus facile.
6.Éviter les pièges à araignées :
Les pièges à araignées sont des URL infinies pointant vers le même contenu sur les mêmes pages lorsque les robots explorent votre site Web. Cela ressemble plus à du tir à blanc. En fin de compte, cela grignotera votre budget de crawl. Ce problème s'aggrave à chaque exploration, et votre site Web est réputé avoir un contenu en double, car chaque URL explorée dans le piège ne sera pas unique.
Vous pouvez briser le piège en bloquant la section via Robots.txt ou utiliser l'une des directives de suivi ou de non-suivi pour bloquer des pages spécifiques. Enfin, vous pouvez chercher à résoudre techniquement le problème en arrêtant l'apparition d'URL infinies.
7. Structure de liaison :
L'interconnexion est l'une des parties essentielles de l'optimisation du crawl. Les robots d'exploration peuvent mieux trouver vos pages avec des liens bien structurés sur votre site Web. Certaines des astuces clés pour une excellente structure de liaison sont :
- Utilisation de liens textuels, car les moteurs de recherche les explorent facilement : <a href="new-page.html">lien textuel</a>
- Utilisation d'un texte d'ancrage descriptif dans vos liens
- Supposons que vous gérez un site Web de salle de sport et que vous souhaitiez lier toutes vos vidéos de salle de sport, vous pouvez utiliser un lien comme celui-ci. N'hésitez pas à parcourir toutes nos <a href="videos.html">vidéos de salle de sport</a>.
8. Le bonheur HTML :
Il est important de nettoyer vos documents HTML et de minimiser la taille de la charge utile des documents HTML, car cela permet aux robots d'exploration d'explorer rapidement les URL. Un autre avantage de l'optimisation HTML est que votre serveur est fortement chargé en raison de plusieurs explorations par les moteurs de recherche, ce qui peut ralentir le chargement de votre page, ce qui n'est pas un bon signe pour le référencement ou l'exploration des moteurs de recherche. L'optimisation HTML peut réduire la charge d'exploration sur le serveur, en maintenant les chargements de page rapides. Cela aide également à résoudre les erreurs d'exploration dues aux délais d'attente du serveur ou à d'autres problèmes vitaux.
9. Intégrez-le simplement :
Aucun site Web aujourd'hui n'offrira de contenu sans de superbes images et vidéos pour sauvegarder le contenu, car c'est ce qui rend leur contenu visuellement plus attrayant et accessible aux robots des moteurs de recherche. Mais, si ce contenu intégré n'est pas optimisé, cela peut réduire la vitesse de chargement, éloignant les robots d'exploration de votre contenu qui peut se classer.
Ici, s'en tenir au HTML pour votre contenu intégré peut aider à obtenir une meilleure exploration à partir des moteurs de recherche. Des technologies comme AJAX, Javascript, etc. sont assez bonnes pour fournir de nouvelles fonctionnalités, mais elles rendent également l'exploration des moteurs de recherche assez délicate.
Conclusion:
En mettant davantage l'accent sur le référencement et l'augmentation du trafic, chaque propriétaire de site Web recherche de meilleures façons de gérer l'élevage de bots et les querelles d'araignées. Mais les solutions résident dans les optimisations granulaires que vous devez apporter à votre site Web et dans les URL d'exploration qui peuvent rendre l'exploration des moteurs de recherche plus spécifique et optimisée pour représenter le meilleur de votre site Web qui peut se classer plus haut dans les pages de résultats des moteurs de recherche.