
¿Cómo manejar el pastoreo de bots y las disputas de arañas para las clasificaciones?
Publicado: 2020-01-23
Los rastreadores de Google indexan cada pieza de contenido que publica en su sitio web. Estos rastreadores son softwares programados que siguen enlaces y códigos y los entregan a un algoritmo. Luego, el algoritmo lo indexa y agrega su contenido a una amplia base de datos. De esta forma, cada vez que un usuario busca una palabra clave, el motor de búsqueda extrae y clasifica los resultados relacionados de la base de datos de páginas ya indexadas.
Google asigna un presupuesto de rastreo a cada sitio web y los rastreadores ejecutan el rastreo de su sitio en consecuencia. Debe administrar y utilizar el presupuesto de rastreo para garantizar un rastreo e indexación inteligentes de todo su sitio web.
En esta publicación, puede aprender sobre los trucos y las herramientas para manejar cómo los motores de búsqueda rastrean e indexan su sitio web.
1. Optimización de la directiva Disallow para Robot.txt:

Robots.txt es un archivo de texto con una sintaxis estricta que funciona como una guía para que las arañas determinen cómo rastrear su sitio. Se guarda un archivo robots.txt en los repositorios de host de su sitio web desde donde los rastreadores buscan las URL. Para optimizar estos Robots.txt o "Protocolo de exclusión de robots", puede usar algunos trucos que pueden ayudar a los rastreadores de Google a rastrear las URL de su sitio para obtener clasificaciones más altas.
Uno de esos trucos es usar una "Directiva de rechazo" , esto es como poner un letrero de "Área restringida" en secciones específicas de su sitio web. Para optimizar la Directiva de rechazo, debe comprender la primera línea de defensa: "Usuarios-agentes".
¿Qué es una directiva de agente de usuario?
Cada archivo Robots.txt consta de una o más reglas y, entre ellas, la regla del agente de usuario es la más importante. Esta regla proporciona a los rastreadores acceso y no acceso a una lista particular en el sitio web.
Por lo tanto, la directiva de agente de usuario se usa para dirigirse a un rastreador específico y darle instrucciones sobre cómo ejecutar el rastreo.
Tipos de rastreadores de Google más utilizados:
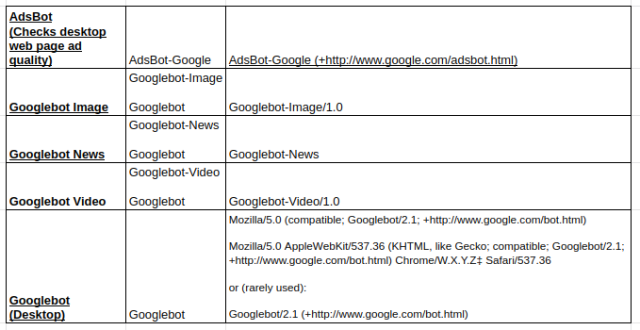
Directiva de rechazo:
Ahora, después de conocer el bot asignado para rastrear su sitio web, puede optimizar diferentes secciones del mismo según el tipo de agente de usuario. Algunos trucos y ejemplos esenciales que puedes seguir para optimizar la directiva disallow de tu sitio web son:
- Use un nombre de página completo que se pueda mostrar en el navegador para que se use para la directiva de rechazo.
- Si desea redirigir el rastreador desde una ruta de directorio, use una marca "/".
- Use * para el prefijo de la ruta, el sufijo o una cadena completa.
Ejemplos del uso de las directivas disallow son:
# Ejemplo 1: Bloquear solo Googlebot
Agente de usuario: robot de Google
No permitir: /
# Ejemplo 2: Bloquear Googlebot y Adsbot
Agente de usuario: robot de Google
Agente de usuario: AdsBot-Google
No permitir: /
# Ejemplo 3: bloquear todos los rastreadores menos AdsBot
Agente de usuario: *
No permitir: /
2. Una directiva sin índice para Robots.txt:
Cuando otros sitios web se vinculan a su sitio, existe la posibilidad de que la URL, que no desea que el rastreador indexe, pueda quedar expuesta. Para superar este problema, puede usar una directiva sin índice. Veamos, ¿cómo podemos aplicar la directiva sin índice a Robots.txt:
Hay dos métodos para aplicar una directiva sin índice para su sitio web:
Etiquetas <Meta>:
Las metaetiquetas son los fragmentos de texto que describen el contenido de su página de una manera breve y transparente que permite a los visitantes saber lo que está por venir. Podemos usar lo mismo para evitar que los rastreadores indexen la página.
Primero, coloque una etiqueta meta "<meta name= "robots" content=" noindex">" en la sección "<head>" de su página que no desea que los rastreadores indexen.
Para los rastreadores de Google, puede usar “<meta name=”googlebot” content=”noindex”/>” en la sección “<head>”.
Como diferentes rastreadores de motores de búsqueda están buscando sus páginas, pueden interpretar su directiva de no indexación de manera diferente. Debido a esto, sus páginas pueden aparecer en los resultados de búsqueda.
Por lo tanto, ayudaría si definiera directivas para páginas de acuerdo con los rastreadores o agentes de usuario.
Puede usar las siguientes etiquetas meta para aplicar la directiva para diferentes rastreadores:
<meta nombre=”googlebot” content=”noindex”>
<meta name=”googlebot-news” content=”nosnippet”>
Etiqueta de X-Robots:
Todos conocemos los encabezados HTTP que se utilizan como respuesta a la solicitud del cliente o del motor de búsqueda de información adicional relacionada con sus páginas web, como la ubicación o el servidor que la proporciona. Ahora, para optimizar estas respuestas de encabezado HTTP para la directiva sin índice, puede agregar etiquetas X-Robots como un elemento de la respuesta del encabezado HTTP para cualquier URL de su sitio web.
Puede combinar diferentes etiquetas de X-Robots con las respuestas del encabezado HTTP. Puede especificar varias directivas en una lista separadas por una coma. A continuación se muestra un ejemplo de una respuesta de encabezado HTTP con diferentes directivas combinadas con etiquetas X-Robots.
HTTP/1.1 200 Aceptar
Fecha: martes, 25 de enero de 2020 21:42:43 GMT
(…)
X-Robots-Etiqueta: noarchive
X-Robots-Tag: no disponible_después: 25 de julio de 2020 15:00:00 PST
(…)
3. Dominar los enlaces canónicos: 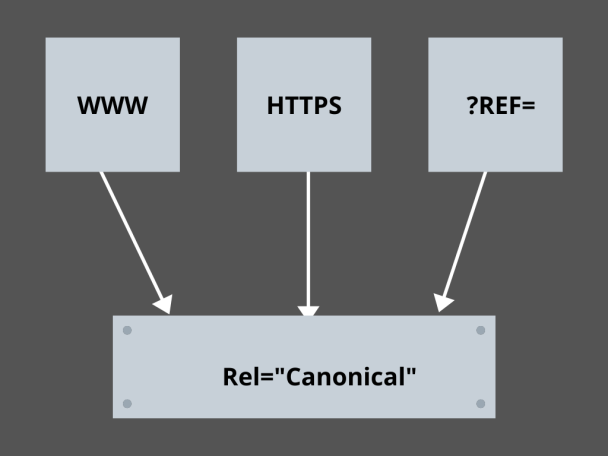
¿Cuál es el factor más temido en SEO hoy en día? ¿Clasificaciones? ¿Tráfico? ¡No! Es el miedo a que los motores de búsqueda penalicen tu sitio web por contenido duplicado. Por lo tanto, mientras elabora una estrategia para su presupuesto de rastreo, debe tener cuidado de no exponer su contenido duplicado.

Aquí, dominar sus enlaces canónicos lo ayudará a manejar sus problemas de contenido duplicado. La palabra contenido duplicado no es lo que significa. Tomemos un ejemplo de dos páginas de un sitio web de comercio electrónico:
Por ejemplo, tiene un sitio web de comercio electrónico con un par de páginas idénticas para un reloj inteligente y ambas tienen contenido similar. Cuando los robots de los motores de búsqueda rastrean su URL, buscarán contenido duplicado y pueden elegir cualquiera de las URL. Para redirigirlos a la URL que es esencial para usted, se puede establecer un enlace canónico para las páginas. Veamos cómo puedes hacerlo:
- Elija cualquier página de las dos páginas para su versión canónica.
- Elige la que recibe más visitas.
- Ahora agregue rel=”canonical” a su página no canónica.
- Redirigir el enlace de la página no canónica a la página canónica.
- Combinará ambos enlaces de su página como un solo enlace canónico.
4. Estructuración del Sitio Web:
Los rastreadores necesitan marcadores y letreros para ayudarlos a descubrir las URL importantes de su sitio, y si no estructura su sitio web, a los rastreadores les resultará difícil ejecutar el rastreo en sus URL. Para ello, utilizamos mapas de sitio porque proporcionan a los rastreadores enlaces a todas las páginas importantes de su sitio web.
Los formatos de mapa de sitio estándar para sitios web o incluso aplicaciones desarrolladas a través de procesos de desarrollo de aplicaciones móviles son mapas de sitio XML, Atom y RSS. Para optimizar el rastreo, debe combinar mapas de sitio XML y fuentes RSS/Atom.
- Los mapas de sitio XML proporcionan a los rastreadores instrucciones para llegar a todas las páginas de su sitio web o aplicación.
- Y el feed RSS/Atom proporciona actualizaciones en sus páginas del sitio web a los rastreadores.
- Los mapas de sitio XML proporcionan a los rastreadores instrucciones para llegar a todas las páginas de su sitio web o aplicación.
5. Navegación de páginas:
La navegación por la página es esencial para las arañas e incluso para los visitantes de su sitio web. Estas botas buscan páginas en su sitio web y una estructura jerárquica predefinida puede ayudar a los rastreadores a encontrar páginas importantes para su sitio web. Otros pasos a seguir para una mejor navegación por la página son:
- Mantenga la codificación en HTML o CSS.
- Organice jerárquicamente sus páginas.
- Use una estructura de sitio web poco profunda para una mejor navegación por la página.
- Mantenga el menú y las pestañas en el encabezado para que sean mínimos y específicos.
- Ayudará a que la navegación por la página sea más fácil.
6.Evitar las trampas de arañas:
Las trampas de araña son URL infinitas que apuntan al mismo contenido en las mismas páginas cuando los rastreadores rastrean su sitio web. Esto es más como disparar espacios en blanco. En última instancia, consumirá su presupuesto de rastreo. Este problema aumenta con cada rastreo, y se considera que su sitio web tiene contenido duplicado, ya que cada URL rastreada en la trampa no será única.
Puede romper la trampa bloqueando la sección a través de Robots.txt o usar una de las directivas de seguir o no seguir para bloquear páginas específicas. Finalmente, puede buscar solucionar el problema técnicamente deteniendo la aparición de URL infinitas.
7. Estructura de enlace:
La interconexión es una de las partes esenciales de la optimización del rastreo. Los rastreadores pueden encontrar mejor sus páginas con enlaces bien estructurados en todo su sitio web. Algunos de los trucos clave para una gran estructura de enlaces son:
- Uso de enlaces de texto, ya que los motores de búsqueda los rastrean fácilmente: <a href=”new-page.html”>enlace de texto</a>
- Uso de texto ancla descriptivo en tus enlaces
- Suponga que tiene un sitio web de gimnasio y desea vincular todos sus videos de gimnasio, puede usar un enlace como este: siéntase libre de explorar todos nuestros <a href=”videos.html”>videos de gimnasio</a>.
8. Felicidad HTML:
Es importante limpiar sus documentos HTML y mantener el tamaño de la carga útil de los documentos HTML al mínimo, ya que permite a los rastreadores rastrear las URL rápidamente. Otra ventaja de la optimización de HTML es que su servidor se carga mucho debido a varios rastreos de los motores de búsqueda, y esto puede ralentizar la carga de su página, lo que no es una buena señal para el SEO o el rastreo del motor de búsqueda. La optimización de HTML puede reducir la carga de rastreo en el servidor, lo que permite que la carga de la página sea rápida. También ayuda a resolver los errores de rastreo debido a tiempos de espera del servidor u otros problemas vitales.
9. Incrustarlo Simple:
Ningún sitio web de hoy en día ofrecerá contenido sin excelentes imágenes y videos que respalden el contenido, ya que eso es lo que hace que su contenido sea visualmente más atractivo y accesible para los rastreadores de los motores de búsqueda. Pero, si este contenido incrustado no está optimizado, puede reducir la velocidad de carga, alejando a los rastreadores de su contenido que puede clasificar.
Aquí, apegarse al HTML para su contenido incrustado puede ayudar a lograr un mejor rastreo de los motores de búsqueda. Las tecnologías como AJAX, Javascript, etc. son bastante buenas para proporcionar nuevas funciones, pero también dificultan el rastreo de los motores de búsqueda.
Conclusión:
Con un mayor enfoque en el SEO y un mayor tráfico, todos los propietarios de sitios web buscan mejores formas de manejar el pastoreo de bots y las disputas entre arañas. Pero las soluciones se encuentran en las optimizaciones granulares que necesita realizar en su sitio web y en el rastreo de URL que pueden hacer que el rastreo del motor de búsqueda sea más específico y optimizado para representar lo mejor de su sitio web que puede clasificarse más alto en las páginas de resultados del motor de búsqueda.