
Uma introdução ao web crawler
Publicados: 2016-03-08Quando falo com as pessoas sobre o que faço e o que é SEO, elas geralmente entendem rapidamente ou agem como agem. Uma boa estrutura de site, um bom conteúdo, bons backlinks endossantes. Mas às vezes, fica um pouco mais técnico e acabo falando sobre mecanismos de busca rastreando seu site e geralmente os perco…
Por que rastrear um site?
O rastreamento da Web começou como um mapeamento da Internet e como cada site estava conectado entre si. Também foi usado pelos motores de busca para descobrir e indexar novas páginas online. Os rastreadores da Web também foram usados para testar a vulnerabilidade do site, testando um site e analisando se algum problema foi detectado.
Agora você pode encontrar ferramentas que rastreiam seu site para fornecer insights. Por exemplo, o OnCrawl fornece dados sobre seu conteúdo e SEO no site ou Majestic, que fornece informações sobre todos os links que apontam para uma página.
Os rastreadores são usados para coletar informações que podem ser usadas e processadas para classificar documentos e fornecer informações sobre os dados coletados.
Construir um rastreador é acessível a qualquer pessoa que conheça um pouco de código. No entanto, fazer um rastreador eficiente é mais difícil e leva tempo.
Como funciona ?
Para rastrear um site ou a Web, primeiro você precisa de um ponto de entrada. Os robôs precisam saber que seu site existe para que possam visitá-lo. Antigamente, você enviava seu site para os mecanismos de pesquisa para informar que seu site estava online. Agora você pode criar facilmente alguns links para seu site e Voila você está no circuito!
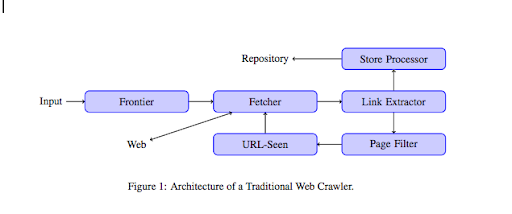
Quando um rastreador chega ao seu site, ele analisa todo o seu conteúdo linha por linha e segue cada um dos links que você possui, sejam eles internos ou externos. E assim por diante até chegar a uma página sem mais links ou se encontrar erros como 404, 403, 500, 503.
De um ponto de vista mais técnico, um rastreador trabalha com uma semente (ou lista) de URLs. Isso é passado para um Fetcher que irá recuperar o conteúdo de uma página. Esse conteúdo é então movido para um extrator de links que analisará o HTML e extrairá todos os links. Esses links são enviados tanto para um processador da Loja que irá, como o próprio nome diz, armazená-los. Esses URLs também passarão por um filtro de página que enviará todos os links interessantes para um módulo de URL visto. Este módulo detecta se a URL já foi vista ou não. Caso contrário, ele será enviado para o Fetcher, que recuperará o conteúdo da página e assim por diante.
Lembre-se de que alguns conteúdos são impossíveis de rastrear, como o Flash. O Javascript está sendo rastreado corretamente pelo GoogleBot, mas de vez em quando ele não rastreia nada. Imagens não são conteúdo que o Google pode rastrear tecnicamente, mas se tornou inteligente o suficiente para começar a entendê-las!
Se os robôs não forem informados do contrário, eles rastrearão tudo. É aqui que o arquivo robots.txt se torna muito útil. Ele informa aos rastreadores (pode ser específico por rastreador, ou seja, GoogleBot ou MSN Bot – saiba mais sobre bots aqui) quais páginas eles não podem rastrear. Digamos, por exemplo, que você tenha navegação usando facetas, talvez não queira que os robôs rastreiem todas elas, pois elas têm pouco valor agregado e usarão o orçamento de rastreamento. Usar esta linha simples ajudará você a evitar que qualquer robô o rastreie
Agente de usuário: *
Não permitir: /pasta-a/
Isso diz a todos os robôs para não rastrear a pasta A.
Agente do usuário: GoogleBot
Não permitir: /repertoire-b/
Isso, por outro lado, especifica que apenas o Google Bot não pode rastrear a pasta B.
Você também pode usar a indicação em HTML que diz aos robôs para não seguir um link específico usando a tag rel=”nofollow”. Alguns testes mostraram que mesmo o uso da tag rel=”nofollow” em um link não impedirá o Googlebot de segui-lo. Isso é contraditório ao seu propósito, mas será útil em outros casos.
[Estudo de caso] Aumente a visibilidade melhorando a rastreabilidade do site para o Googlebot
 Leia o estudo de caso
Leia o estudo de caso
Você mencionou o orçamento de rastreamento, mas o que é isso?
Digamos que você tenha um site que foi descoberto pelos mecanismos de pesquisa. Eles vêm regularmente para ver se você fez alguma atualização em seu site e criou novas páginas.
Cada site tem seu próprio orçamento de rastreamento, dependendo de vários fatores, como o número de páginas que seu site possui e a sanidade dele (se tiver muitos erros, por exemplo). Você pode ter uma ideia rápida do seu orçamento de rastreamento fazendo login no Search Console.
Seu orçamento de rastreamento fixará o número de páginas que um robô rastreia em seu site cada vez que ele é visitado. Ele está proporcionalmente vinculado ao número de páginas que você tem em seu site e já foi rastreado. Algumas páginas são rastreadas com mais frequência do que outras, especialmente se forem atualizadas regularmente ou se estiverem vinculadas a páginas importantes.
Por exemplo, sua casa é seu principal ponto de entrada, que será rastreado com muita frequência. Se você tiver um blog ou uma página de categoria, eles serão rastreados com frequência se estiverem vinculados à navegação principal. Um blog também será rastreado com frequência, pois é atualizado regularmente. Uma postagem de blog pode ser rastreada com frequência quando é publicada pela primeira vez, mas depois de alguns meses provavelmente não será atualizada.
Quanto mais uma página é rastreada, mais importante um robô considera importante em comparação com outros. É quando você precisa começar a trabalhar na otimização do seu orçamento de rastreamento.
Otimizando seu orçamento de rastreamento
Para otimizar seu orçamento e garantir que suas páginas mais importantes recebam a atenção que merecem, você pode analisar os logs do servidor e ver como seu site está sendo rastreado:
- Com que frequência suas principais páginas são rastreadas
- Você consegue ver páginas menos importantes sendo rastreadas mais do que outras mais importantes?
- Os robôs geralmente recebem um erro 4xx ou 5xx ao rastrear seu site?
- Os robôs encontram armadilhas de aranha? (Matthew Henry escreveu um ótimo artigo sobre eles)
Ao analisar seus logs, você verá quais páginas você considera menos importantes estão sendo muito rastreadas. Você então precisa se aprofundar em sua estrutura de links internos. Se estiver sendo rastreado, deve ter muitos links apontando para ele.
Você também pode trabalhar na correção de todos esses erros (4xx e 5xx) com o OnCrawl. Isso melhorará a rastreabilidade e a experiência do usuário, é um caso em que todos saem ganhando.
Rastreamento VS Raspagem?
Rastejar e raspar são duas coisas diferentes que são usadas para propósitos diferentes. Rastrear um site é acessar uma página e seguir os links que você encontra ao digitalizar o conteúdo. Um rastreador se moverá para outra página e assim por diante.
Scraping, por outro lado, é escanear uma página e coletar dados específicos da página: tag de título, meta descrição, tag h1 ou uma área específica do seu site, como uma lista de preços. Os raspadores geralmente agem como “humanos”, eles ignoram quaisquer regras do arquivo robots.txt, arquivam formulários e usam um agente de usuário do navegador para não serem detectados.
Os rastreadores de mecanismos de pesquisa geralmente atuam como scrappers, pois precisam coletar dados para processá-los para seu algoritmo de classificação. Eles não procuram dados específicos comparados ao scrapper, eles apenas usam todos os dados disponíveis na página e ainda mais (o tempo de carregamento é algo que você não pode obter de uma página). Os rastreadores de mecanismos de pesquisa sempre se identificarão como rastreadores para que o proprietário de um site possa saber quando foi a última vez que visitou seu site. Isso pode ser muito útil quando você acompanha a atividade real do usuário.
Agora que você já sabe um pouco mais sobre rastreamento, como funciona e por que é importante, o próximo passo é começar a analisar os logs do servidor. Isso fornecerá informações detalhadas sobre como os robôs interagem com seu site, quais páginas eles visitam com frequência e quantos erros encontram ao visitar seu site.
Para obter mais informações técnicas e históricas sobre o rastreador da Web, você pode ler “Um breve histórico dos rastreadores da Web”