Ile testów A/B należy przeprowadzać miesięcznie?
Opublikowany: 2023-01-19
To ważne pytanie, które należy wziąć pod uwagę, jeśli chodzi o powodzenie programu testowania.
Przeprowadzając zbyt wiele testów, możesz marnować zasoby, nie uzyskując dużej wartości z żadnego pojedynczego eksperymentu.
Ale przeprowadź zbyt mało testów i możesz przegapić ważne możliwości optymalizacji, które mogą przynieść więcej konwersji.
Biorąc pod uwagę tę zagadkę, jaka jest idealna kadencja testowania?
Aby pomóc odpowiedzieć na to pytanie, $en$e przyjrzy się kilku najbardziej utytułowanym i postępowym zespołom eksperymentalnym na świecie.
Amazon to jedna z takich nazw, które przychodzą na myśl.
Gigant eCommerce jest także goliatem eksperymentalnym. W rzeczywistości mówi się, że Amazon przeprowadza ponad 12 000 eksperymentów rocznie! Kwota ta rozkłada się na około tysiąc eksperymentów miesięcznie.
Mówi się, że firmy takie jak Google i Bing Microsoftu utrzymują podobne tempo.
Według Wikipedii każdy z gigantów wyszukiwarek przeprowadza ponad 10 000 testów A/B rocznie lub około 800 testów miesięcznie.
I to nie tylko wyszukiwarki działają w takim tempie.
Booking.com to kolejna znana nazwa w eksperymentach. Według doniesień strona rezerwacji podróży przeprowadza ponad 25 000 testów rocznie, co daje ponad 2 tysiące testów miesięcznie lub 70 testów dziennie!
Jednak badania pokazują, że przeciętna firma przeprowadza tylko 2-3 testy miesięcznie.
Tak więc, jeśli większość firm przeprowadza tylko kilka testów miesięcznie, ale niektóre z najlepszych na świecie przeprowadzają tysiące eksperymentów miesięcznie, ile testów powinno się przeprowadzać?
W prawdziwym stylu CRO odpowiedź brzmi: to zależy.
Od czego to zależy? Należy wziąć pod uwagę kilka ważnych czynników.
Idealna liczba testów A/B do przeprowadzenia zależy od konkretnej sytuacji i czynników, takich jak wielkość próby, złożoność pomysłów na testy i dostępne zasoby.
6 czynników, które należy wziąć pod uwagę podczas przeprowadzania testów A/B
Decydując o tym, ile testów przeprowadzić w miesiącu, należy wziąć pod uwagę 6 podstawowych czynników. Zawierają
- Wymagania dotyczące wielkości próbki
- Dojrzałość organizacyjna
- Dostępne zasoby
- Złożoność pomysłów na testy
- Testowanie terminów
- Efekty interakcji
Zagłębmy się w każdy z nich.
Wymagania dotyczące wielkości próbki
W testach A/B wielkość próby opisuje ilość ruchu potrzebną do przeprowadzenia wiarygodnego testu.
Aby przeprowadzić statystycznie ważne badanie, potrzebujesz dużej, reprezentatywnej próby użytkowników.
Chociaż teoretycznie możesz przeprowadzić eksperyment z zaledwie kilkoma użytkownikami, nie uzyskasz zbyt miarodajnych wyników.
Małe rozmiary próbek mogą nadal dawać statystycznie istotne wyniki
Na przykład wyobraź sobie test A/B, w którym tylko 10 użytkowników widziało konwersję wersji A i 2. Tylko 8 użytkowników zobaczyło wersję B, a 6 osób dokonało konwersji.
Jak pokazuje ten wykres, wyniki są statystycznie istotne:
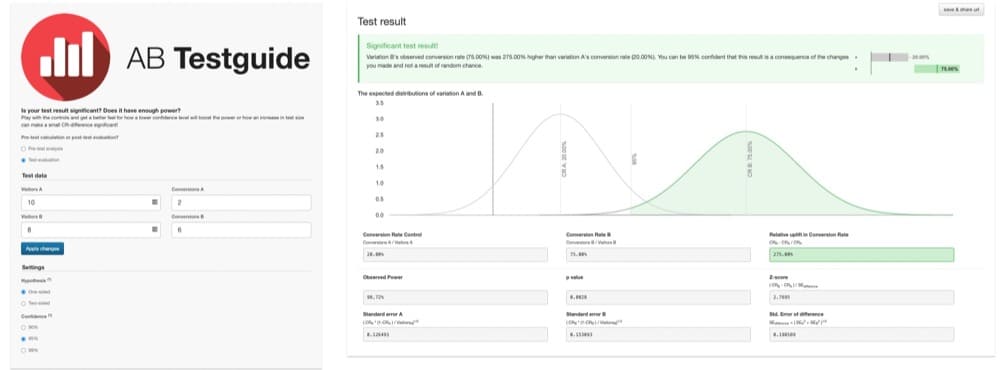
Wersja B wydaje się być wydajniejsza o 275%. Ale te ustalenia nie są zbyt wiarygodne. Wielkość próbki jest zbyt mała, aby zapewnić miarodajne wyniki.
Badanie jest za słabe. Nie zawiera dużej, reprezentatywnej próby użytkowników.
Ponieważ test ma zbyt małą moc, wyniki są podatne na błędy. I nie jest jasne, czy wynik nastąpił przypadkowo, czy też jedna wersja jest naprawdę lepsza.
Przy tak małej próbce łatwo wyciągnąć błędne wnioski.
Prawidłowo zasilane testy
Aby przezwyciężyć tę pułapkę, testy A/B muszą być odpowiednio zasilane dużą, reprezentatywną próbą użytkowników.
Jak duży jest wystarczająco duży?
Na to pytanie można odpowiedzieć, wykonując proste obliczenia wielkości próby.
Aby najłatwiej obliczyć wymagania dotyczące wielkości próbki, sugeruję użycie kalkulatora wielkości próbki. Jest ich tam mnóstwo.
Moim ulubionym jest Evana Millera, ponieważ jest elastyczny i dokładny. Ponadto, jeśli rozumiesz, jak go używać, możesz zrozumieć prawie każdy dostępny kalkulator.
Oto jak wygląda kalkulator Evana Millera:
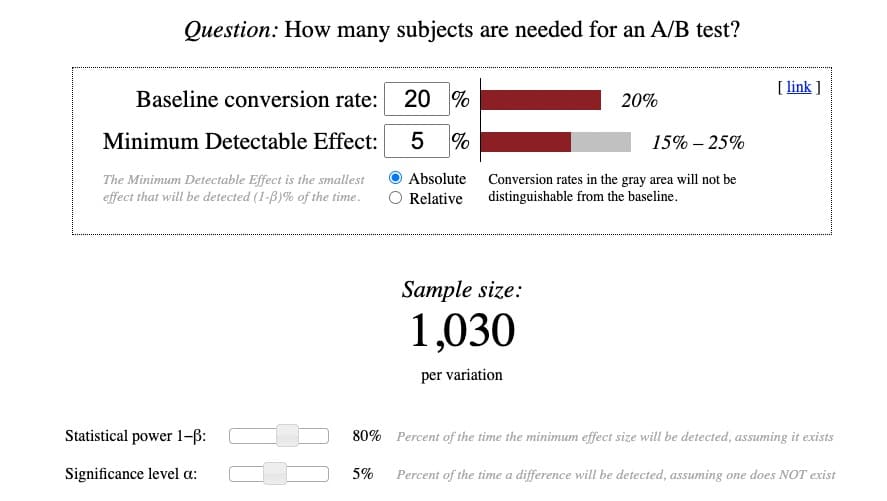
Chociaż same obliczenia są dość proste, zrozumienie stojącej za nimi terminologii już nie. Więc próbowałem wyjaśnić kompleks:
Podstawowy współczynnik konwersji
Podstawowy współczynnik konwersji to istniejący współczynnik konwersji wersji kontrolnej lub oryginalnej. Podczas konfigurowania testu A/B jest zwykle oznaczona jako „wersja A”.
Powinieneś być w stanie znaleźć ten współczynnik konwersji na swojej platformie analitycznej.
Jeśli nigdy nie przeprowadzałeś testu A/B lub nie znasz podstawowego współczynnika konwersji, zgadnij najlepiej.
Średni współczynnik konwersji w większości witryn, branż i typów urządzeń wynosi od 2 do 5%. Jeśli więc naprawdę nie masz pewności co do podstawowego współczynnika konwersji, zachowaj ostrożność i zacznij od poziomu bazowego 2%.
Im niższy bazowy współczynnik konwersji, tym większy rozmiar próbki będzie potrzebny. I wzajemnie.
Minimalny wykrywalny efekt (MDE)
Minimalny wykrywalny efekt (MDE) brzmi jak skomplikowana koncepcja. Ale staje się to o wiele łatwiejsze do zrozumienia, jeśli podzielisz ten termin na trzy części:
- Minimalna = najmniejsza
- Wykrywalny = pragnienie, które próbujesz wykryć lub znaleźć, przeprowadzając eksperyment
- Efekt = różnica konwersji między kontrolą a zabiegiem
Dlatego minimalny wykrywalny efekt to najmniejszy wzrost konwersji, jaki chcesz wykryć przeprowadzając test.
Niektórzy puryści danych będą argumentować, że ta definicja faktycznie opisuje minimalny efekt zainteresowania (MEI). Jakkolwiek chcesz to nazwać, celem jest przewidzenie, jak duży wzrost konwersji spodziewasz się uzyskać, przeprowadzając test.
Chociaż to ćwiczenie może wydawać się bardzo spekulacyjne, możesz użyć kalkulatora wielkości próby, takiego jak ten, lub kalkulatora statystycznego testu A/B firmy Convert, aby obliczyć przewidywany MDE.
Jako bardzo ogólną zasadę przyjmuje się, że 2-5% MDE jest uważane za rozsądne. Wszystko, co jest znacznie wyższe, jest zwykle nierealne, gdy przeprowadza się test z naprawdę odpowiednią mocą.
Im mniejszy MDE, tym większy rozmiar próbki jest potrzebny. I wzajemnie.
MDE można wyrazić jako wartość bezwzględną lub względną.
Absolutny
Bezwzględny MDE to surowa liczba różnic między współczynnikiem konwersji kontroli i wariantu.
Na przykład, jeśli bazowy współczynnik konwersji wynosi 2,77% i oczekujesz, że wariant osiągnie bezwzględny MDE +3%, bezwzględna różnica wyniesie 5,77%.
Względny
Natomiast efekt względny wyraża procentową różnicę między wariantami.
Na przykład, jeśli bazowy współczynnik konwersji wynosi 2,77% i oczekujesz, że wariant osiągnie względny MDE +3%, względna różnica wyniesie 2,89%.
Ogólnie rzecz biorąc, większość eksperymentatorów stosuje względny wzrost procentowy, więc zwykle najlepiej przedstawiać wyniki w ten sposób.
Potęga statystyczna 1−β
Moc odnosi się do prawdopodobieństwa znalezienia efektu lub różnicy konwersji, zakładając, że naprawdę istnieje.
Podczas testowania Twoim celem jest upewnienie się, że masz wystarczającą moc, aby w znaczący sposób wykryć różnicę, jeśli taka istnieje, bez błędów. Dlatego wyższa moc jest zawsze lepsza. Ale kompromis polega na tym, że wymaga większej wielkości próbki.
Moc 0,80 jest uważana za standardową najlepszą praktykę. Możesz więc pozostawić go jako domyślny zakres w tym kalkulatorze.
Ta ilość oznacza, że istnieje 80% szans, że jeśli pojawi się efekt, wykryjesz go dokładnie i bezbłędnie. W związku z tym istnieje tylko 20% szans, że przegapisz prawidłowe wykrycie efektu. Ryzyko warte podjęcia.
Poziom istotności α
W bardzo prostej definicji poziom istotności alfa to odsetek wyników fałszywie dodatnich, czyli procent czasu, w którym różnica konwersji zostanie wykryta — nawet jeśli tak naprawdę nie istnieje.
Zgodnie z najlepszą praktyką testowania A/B poziom istotności powinien wynosić 5% lub mniej. Więc możesz po prostu zostawić to jako domyślne w tym kalkulatorze.
Poziom istotności α wynoszący 5% oznacza, że istnieje 5% szansa, że znajdziesz różnicę między kontrolą a wariantem — podczas gdy w rzeczywistości różnica nie istnieje.
Znowu ryzyko, które warto podjąć.
Ocena wymagań dotyczących wielkości próbki
Po podłączeniu tych liczb do kalkulatora możesz teraz upewnić się, że Twoja witryna ma wystarczający ruch, aby przeprowadzić test z odpowiednią mocą w standardowym okresie testowym od 2 do 6 tygodni.
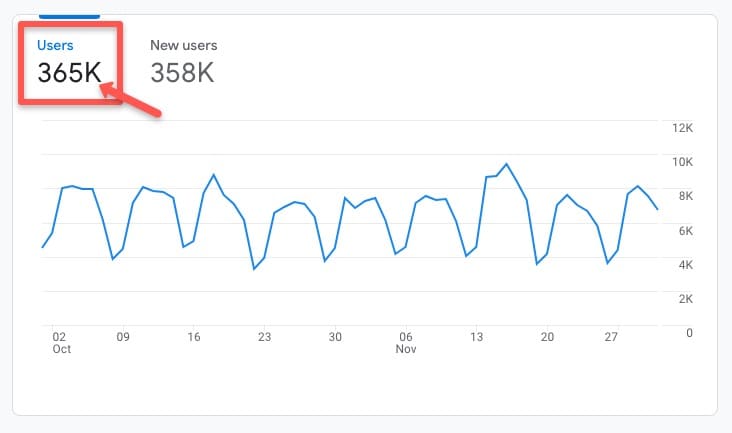
Aby to zweryfikować, przejdź do preferowanej platformy analitycznej i spójrz na historyczny średni ruch w witrynie lub na stronie, którą chcesz przetestować, w określonym czasie.
Na przykład na tym koncie Google Analytics 4 (GA4), przechodząc do karty Cykl życia > Pozyskiwanie > Przegląd pozyskiwania , możesz zobaczyć, że w ostatnim okresie historycznym od października do listopada 2022 r. było 365 tysięcy użytkowników:
Opierając się na istniejącym bazowym współczynniku konwersji wynoszącym 3,5%, przy względnym MDE wynoszącym 5%, przy standardowej mocy 80% i standardowym poziomie istotności 5%, kalkulator pokazuje wielkość próby wynoszącą 174 369 odwiedzających na wariant potrzebnych do przeprowadzenia prawidłowego zasilany test A/B:
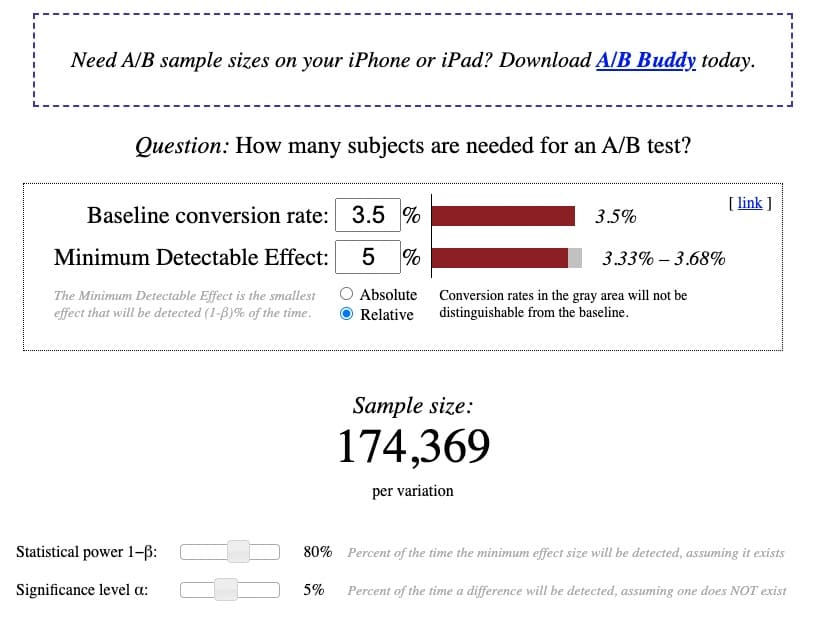
Zakładając, że trendy ruchu w nadchodzących miesiącach utrzymają się na stosunkowo stabilnym poziomie, można oczekiwać, że witryna osiągnie około 365 tysięcy użytkowników lub (365 tysięcy/2 warianty) 182 tysiące odwiedzających na wariant w rozsądnym czasie testowania.
Wymagania dotyczące wielkości próby są osiągalne, co daje zielone światło do przeprowadzenia testu.
Ważna uwaga: to ćwiczenie weryfikujące wymagania dotyczące wielkości próby powinno być zawsze przeprowadzane PRZED uruchomieniem jakiegokolwiek badania, aby wiedzieć, czy masz wystarczający ruch, aby przeprowadzić test z odpowiednią mocą.
Ponadto podczas przeprowadzania testu NIGDY nie należy go przerywać przed osiągnięciem wstępnie obliczonej wielkości próbki — nawet jeśli wyniki wydają się znaczące wcześniej.
Przedwczesne ogłaszanie zwycięzcy lub przegranego przed spełnieniem wymagań dotyczących wielkości próby jest tak zwanym „podglądaniem” i jest niebezpieczną praktyką testową, która może prowadzić do błędnych ocen, zanim wyniki zostaną w pełni usunięte.
Ile testów możesz przeprowadzić, jeśli masz wystarczający ruch?
Zakładając, że witryna lub strony, które chcesz przetestować, spełniają wymagania dotyczące wielkości próbki, ile testów możesz przeprowadzić?
Odpowiedź brzmi: to zależy.
Według prezentacji udostępnionej przez Ronny'ego Kohavi, byłego wiceprezesa ds. eksperymentów w Bing firmy Microsoft, Microsoft zazwyczaj przeprowadza ponad 300 eksperymentów dziennie.
Ale mają ruch, aby to zrobić.
W każdym eksperymencie bierze udział ponad 100 tysięcy użytkowników:
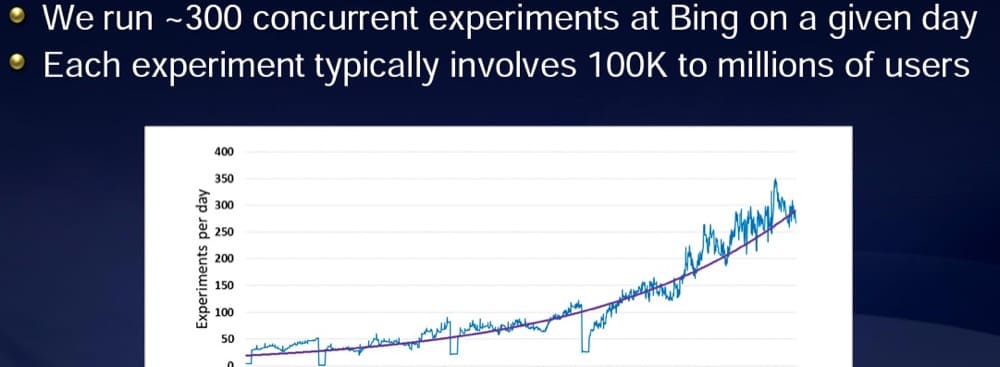
Im większy dostępny ruch, tym więcej testów możesz przeprowadzić.

W przypadku każdego testu musisz upewnić się, że masz wystarczająco dużą próbkę, aby przeprowadzić eksperyment z odpowiednią mocą.
Jeśli reprezentujesz mniejszą organizację z mniejszym ruchem, rozważ mniej testów wyższej jakości.
Ostatecznie tak naprawdę nie chodzi o to, ile testów przeprowadzasz, ale o wynik eksperymentów.
Opcje, jeśli nie możesz spełnić wymagań dotyczących wielkości próbki
Jeśli odkryjesz, że nie możesz spełnić wymagań dotyczących wielkości próbki, nie martw się. Eksperymentowanie nie jest dla Ciebie wykluczone. Masz kilka potencjalnych opcji eksperymentowania:
- Skoncentruj się na pozyskiwaniu ruchu
Nawet duże witryny mogą mieć mały ruch na niektórych stronach.
Jeśli stwierdzisz, że ruch w witrynie lub ruch na niektórych stronach nie spełnia wymagań dotyczących wielkości próby, rozważ skoncentrowanie wysiłków na pozyskaniu większego ruchu.
Aby to zrobić, możesz zastosować agresywną taktykę optymalizacji pod kątem wyszukiwarek (SEO), aby uzyskać wyższą pozycję w wyszukiwarkach i zebrać więcej kliknięć.
Możesz także pozyskiwać płatny ruch za pośrednictwem kanałów takich jak Google Ads, reklamy LinkedIn, a nawet banery reklamowe.
Oba te działania związane z pozyskiwaniem mogą pomóc zwiększyć ruch w sieci i dać większą możliwość testowania tego, co najlepiej konwertuje z użytkownikami.
Jeśli jednak korzystasz z płatnego ruchu, aby spełnić wymagania dotyczące wielkości próby, rozważ segmentację wyników testu według typu ruchu, ponieważ zachowanie użytkowników może się różnić w zależności od źródła ruchu.
- Oceń, czy testy A/B są dla Ciebie najlepszą metodą eksperymentowania
Chociaż testy A/B są uważane za złoty standard eksperymentowania, wyniki są tak dobre, jak dane, które za nimi stoją.
Jeśli okaże się, że nie masz wystarczającego ruchu, aby przeprowadzić test z odpowiednią mocą, możesz rozważyć, czy testowanie A/B jest naprawdę najlepszą opcją eksperymentowania.
Istnieją inne podejścia oparte na badaniach, które wymagają znacznie mniejszych próbek i mogą nadal dostarczać niezwykle cennych informacji dotyczących optymalizacji.
Testy User Experience (UX), ankiety konsumenckie, ankiety wyjściowe lub wywiady z klientami to kilka innych sposobów eksperymentowania, które możesz wypróbować jako alternatywę dla testów A/B.
- Wyniki realizacji mogą dostarczać tylko danych kierunkowych
Ale jeśli pozostaniesz skupiony na testach A/B, nadal możesz przeprowadzać testy.
Po prostu zdaj sobie sprawę, że wyniki mogą nie być w pełni dokładne i dostarczą jedynie „danych kierunkowych” wskazujących na prawdopodobny – a nie w pełni godny zaufania – wynik.
Ponieważ wyniki mogą nie być całkowicie prawdziwe, warto dokładnie monitorować efekt konwersji w czasie.
To powiedziawszy, często ważniejsze niż dokładne dane dotyczące konwersji są liczby na koncie bankowym. Jeśli idą w górę, wiesz, że praca nad optymalizacją, którą wykonujesz, działa.
Testowanie dojrzałości
Oprócz wymagań dotyczących wielkości próby, innym czynnikiem wpływającym na rytm testowania jest poziom dojrzałości organizacji testującej.
Dojrzałość testowa to termin używany do opisania, jak zakorzenione jest eksperymentowanie w kulturze organizacyjnej i jak zaawansowane są praktyki eksperymentalne.
Organizacje takie jak Amazon, Google, Bing i Booking – które przeprowadzają tysiące testów miesięcznie – dysponują progresywnymi, dojrzałymi zespołami testowymi.
To nie przypadek.
Rytm testowania jest zwykle ściśle powiązany z poziomem dojrzałości organizacji.
Jeśli eksperymentowanie jest zakorzenione w organizacji, kierownictwo jest w to zaangażowane. Ponadto pracownicy w całej organizacji są zwykle zachęcani do wspierania eksperymentów i ustalania ich priorytetów, a nawet mogą pomagać w dostarczaniu pomysłów na testy.
Kiedy te czynniki się łączą, znacznie łatwiej jest uruchomić celowy program testowania.
Jeśli masz nadzieję przyspieszyć testowanie, pomocne może być najpierw przyjrzenie się poziomowi dojrzałości Twojej organizacji.
Zacznij od oceny pytań takich jak
- Jak ważne jest eksperymentowanie dla C-Suite?
- Jakie zasoby są udostępniane w celu wspierania eksperymentowania?
- Jakie kanały komunikacji są dostępne do przekazywania aktualizacji testów?
Jeśli odpowiedź brzmi „żadna” lub jest jej bliska, rozważ najpierw stworzenie kultury testowania.
Gdy Twoja organizacja przyjmie bardziej postępową kulturę eksperymentowania, naturalnie łatwiej będzie przyspieszyć tempo testowania.
Sugestie dotyczące tworzenia kultury eksperymentowania można znaleźć w zasobach takich jak ten i ten artykuł.
Ograniczenia zasobów
Zakładając, że masz już pewien stopień zaangażowania organizacyjnego, następnym problemem do pokonania są ograniczenia zasobów.
Czas, pieniądze i siła ludzka to ograniczenia, które mogą ograniczać twoją zdolność do testowania. I szybko przetestuj.
Aby przezwyciężyć ograniczenia zasobów, pomocne może być rozpoczęcie od oceny złożoności testów.
Zrównoważ proste i złożone testy
Jako eksperymentator możesz przeprowadzać testy od super prostych po szalenie złożone.
Proste testy mogą obejmować optymalizację elementów, takich jak kopia lub kolor, aktualizowanie obrazów lub przesuwanie pojedynczych elementów na stronie.
Złożone testy mogą obejmować zmianę kilku elementów, zmianę struktury strony lub aktualizację lejka konwersji. Tego rodzaju testy często wymagają głębokiej pracy z kodowaniem.
Przeprowadzając tysiące testów A/B, uznałem, że przydatne jest posiadanie mieszanki około ⅗ prostszych i ⅖ bardziej złożonych testów, które są wykonywane jednocześnie przez cały czas.
Prostsze testy mogą zapewnić szybkie i łatwe wygrane.
Ale większe testy, z większymi zmianami, często dają większe efekty. W rzeczywistości, zgodnie z niektórymi badaniami optymalizacyjnymi, im więcej i bardziej złożonych testów przeprowadzasz, tym bardziej prawdopodobne jest, że odniesiesz sukces. Więc nie bój się często przeprowadzać dużych testów wahań.
Pamiętaj tylko, że kompromis polega na tym, że wydasz więcej zasobów na zaprojektowanie i zbudowanie testu. I nie ma gwarancji, że wygra.
Test oparty na dostępnych zasobach ludzkich
Jeśli jesteś samotnym strategiem CRO lub pracujesz z małym zespołem, Twoje możliwości są ograniczone. Niezależnie od tego, czy jest to proste, czy złożone, możesz znaleźć 2-5 testów miesięcznie.
Z drugiej strony, jeśli pracujesz w organizacji, która ma oddany zespół badaczy, strategów, projektantów, programistów i specjalistów ds. kontroli jakości, prawdopodobnie masz możliwość przeprowadzania dziesiątek, a nawet setek testów miesięcznie.
Aby określić, ile testów należy przeprowadzić, oceń dostępność zasobów ludzkich.
Średnio prosty test może zająć 3-6 godzin, aby wymyślić, stworzyć szkielet, zaprojektować, opracować, wdrożyć, zapewnić kontrolę jakości i monitorować wyniki.
Z drugiej strony bardzo złożony test może trwać nawet od 15 do 20 godzin.
Miesiąc ma około 730 godzin, więc będziesz chciał być bardzo wyrachowany w kwestii testów i liczby testów, które przeprowadzasz w tym cennym czasie.
Zaplanuj i uszereguj swoje pomysły na testy
Aby pomóc sobie w określeniu optymalnej struktury testowania, rozważ użycie struktury priorytetyzacji testów, takiej jak PIE, ICE lub PXL.
Ramy te zapewniają ilościową technikę klasyfikowania najlepszych pomysłów na testy, oceniania łatwości implementacji i oceny, które testy z największym prawdopodobieństwem zwiększą liczbę konwersji.
Po przeprowadzeniu tej oceny lista pomysłów na testy z priorytetami będzie wyglądać mniej więcej tak:

Po uszeregowaniu najlepszych pomysłów na testy zaleca się również utworzenie planu testowania, aby wizualnie zaplanować oś czasu testu i kolejne kroki.
Twoja mapa drogowa może wyglądać mniej więcej tak:
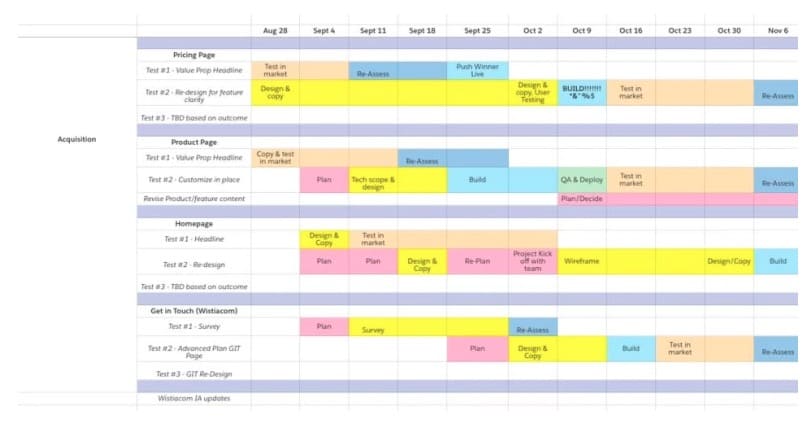
Powinien zawierać:
- Lista pomysłów, które planujesz przetestować, według stron.
- Jak długo przewidujesz, że zajmie każdy etap testowania (projektowanie, rozwój, kontrola jakości itp.).
- Jak długo planujesz przeprowadzać każdy test, w oparciu o wstępnie obliczone wymagania dotyczące wielkości próbki. Możesz obliczyć wymagania dotyczące czasu trwania testu za pomocą kalkulatora czasu trwania testu, takiego jak ten.
Mapując swoje pomysły na testy, będziesz w stanie dokładniej określić rytm i możliwości testowania.
W miarę wypełniania planu testowania może stać się bardzo jasne, że liczba testów, które można przeprowadzić, zależy od dostępnych zasobów.
Czy należy przeprowadzać wiele testów jednocześnie?
Ale tylko dlatego, że możesz coś zrobić, nie zawsze oznacza, że powinieneś.
Jeśli chodzi o przeprowadzanie wielu testów jednocześnie, toczy się wielka debata na temat najlepszego podejścia.
Artykuły, takie jak ten, autorstwa lidera Experiment Nation, Rommila Santiago, poruszają kontrowersyjne pytanie: czy można przeprowadzać wiele testów A/B jednocześnie?
Niektórzy eksperymentatorzy powiedzą, że absolutnie nie!
Będą argumentować, że powinieneś przeprowadzać tylko jeden test, po jednej stronie na raz. W przeciwnym razie nie będziesz w stanie właściwie wyizolować żadnego efektu.
Byłem w tym obozie, bo tak mnie uczono prawie dekadę temu.
Ściśle przekazano mi, że należy przeprowadzać tylko jeden test, z jedną zmianą, na jednej stronie, w jednym czasie. Działałem z takim nastawieniem przez wiele lat — ku konsternacji niespokojnych klientów, którzy chcieli szybciej uzyskać więcej wyników.
Jednak ten artykuł Timothy'ego Chana, byłego analityka danych na Facebooku, a obecnie głównego analityka danych w Statsig, całkowicie zmienił moje zdanie.
Chan argumentuje w swoim artykule, że efekty interakcji są zdecydowanie przereklamowane.
W rzeczywistości jednoczesne przeprowadzanie wielu testów nie tylko nie stanowi problemu; to naprawdę jedyny sposób na przetestowanie!
To stanowisko jest poparte danymi z jego pracy na Facebooku, gdzie Chan widział, jak gigant mediów społecznościowych z powodzeniem przeprowadzał setki eksperymentów jednocześnie, wiele z nich nawet na tej samej stronie.
Eksperci ds. danych, tacy jak Ronny Kohavi i Hazjier Pourkhalkhali, są zgodni: efekty interakcji są wysoce nieprawdopodobne. W rzeczywistości najlepszym sposobem sprawdzenia sukcesu jest wielokrotne przeprowadzanie wielu testów na bieżąco.
Tak więc, rozważając rytm testowania, nie martw się o efekt interakcji nakładających się testów. Testuj swobodnie.
Streszczenie
W testach A/B nie ma optymalnej liczby testów A/B, które należy przeprowadzić.
Idealna liczba jest odpowiednia dla Twojej wyjątkowej sytuacji.
Liczba ta opiera się na kilku czynnikach, w tym ograniczeniach wielkości próbki Twojej witryny, złożoności koncepcji testowania oraz dostępnej pomocy technicznej i zasobów.
W końcu nie chodzi tak bardzo o liczbę testów, które przeprowadzasz, ale raczej o jakość testów i uzyskiwane wyniki. Pojedynczy test, który przynosi duży wzrost, jest o wiele bardziej wartościowy niż kilka niejednoznacznych testów, które nie poruszają igły.
W testowaniu naprawdę chodzi o jakość, a nie ilość!
Więcej informacji o tym, jak najlepiej wykorzystać program testów A/B, znajdziesz w tym artykule Convert.