
如何使用 Python 根據 URL 位置預測非品牌自然流量收入
已發表: 2022-05-24什麼是SEO預測?
SEO 預測或自然流量估算是使用您自己網站的數據或第三方數據來估算您網站未來的自然流量、SEO 收入和 SEO 投資回報率的過程。 這個估計可以根據我們的數據使用許多不同的方法來計算。
在本教程中,我們希望根據我們的 URL 位置及其當前收入來預測我們的非品牌自然收入和非品牌自然流量。 這可以幫助我們作為 SEO 獲得其他利益相關者的更多支持:從增加每月、每季度或每年的預算到產品和開發團隊的更多工時。
請記住,本教程不僅適用於非品牌自然流量; 通過進行一些更改並了解 Python,您可以使用它來估計您的目標頁面流量。
因此,我們可以生成如下圖所示的 Google Sheet。
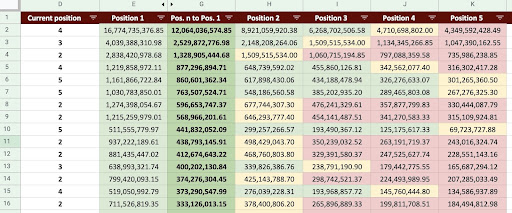
谷歌表格圖片
非品牌SEO流量預測
閱讀介紹後,您可能會問的第一個問題是,“為什麼要計算非品牌自然流量?”。
讓我們考慮像亞馬遜這樣的公司。 當您想購買書籍或口罩時,只需搜索“buy mask amazon”即可。
品牌通常是最重要的,當你想買東西時,你的偏好是從這些公司購買你需要的東西。 在每個行業中,都有影響用戶在 Google 搜索中的行為的品牌公司。
如果我們檢查亞馬遜的 Google Search Console (GSC) 數據,我們可能會發現它從品牌查詢中獲得了大量流量,而且大多數時候,品牌查詢的第一個結果是該品牌的網站。
作為一名 SEO,和我一樣,您可能已經聽過很多次了,“只有我們的品牌才能幫助我們的 SEO!” 我們如何說“不,不是這樣”,並顯示非品牌查詢的流量和收入?
證明這一點更加複雜,因為我們知道谷歌的算法非常複雜,很難將品牌搜索與非品牌搜索區分開來。 但這就是使我們作為 SEO 所做的一切變得更加重要的原因。
在本教程中,我將向您展示如何區分品牌和非品牌這兩者,並向您展示 SEO 的強大功能。
即使您的公司沒有品牌,您仍然可以從這篇文章中獲益良多:您可以了解如何估算您網站的自然數據。
基於流量估計的 SEO ROI
無論您身在何處或做什麼,資源都是有限的; 無論是預算還是工作日的小時數。 了解如何最好地分配資源在整體和 SEO 投資回報率 (ROI) 中起著重要作用。
CMO、營銷副總裁或績效營銷人員都有不同的 KPI,並且需要不同的資源來實現他們的目標。 確保您獲得所需的最佳方法是通過展示它將給公司帶來的回報來證明其必要性。 SEO 投資回報率也不例外。 當一年中的預算分配時間到來並且您的團隊想要請求更大的預算時,估算您的 SEO 投資回報率可以讓您在談判中佔上風。 計算出非品牌流量估算後,您可以更好地評估實現預期結果所需的預算。
SEO預測對SEO策略的影響
正如我們所知,每 3 或 6 個月我們都會審查我們的 SEO 策略並對其進行調整,以盡可能獲得最佳結果。 但是,當您不知道對您的公司來說最大的利潤在哪裡時會發生什麼? 您可以做出決定,但是當您對網站的流量有更全面的了解時,它們不會像做出的決定那樣有效。
非品牌有機流量收入估算可以與您的登錄頁面和查詢細分相結合,以提供全局,幫助您作為 SEO 經理或 SEO 策略師制定更好的策略。
預測自然流量的不同方法
SEO 社區中有很多不同的方法和公共腳本來預測未來的自然流量。
其中一些方法包括:
- 全站有機流量預測
- 特定頁面(博客、產品、類別等)或單個頁面的自然流量預測
- 針對特定查詢(查詢包含“購買”、“操作方法”等)或查詢的有機流量預測
- 特定時期的自然流量預測(尤其是季節性事件)
我的方法是針對特定頁面的,時間範圍是一個月。
[案例研究] 通過頁面 SEO 推動新市場的增長
 閱讀案例研究
閱讀案例研究如何計算自然流量收入
準確的方法基於您的 Google Analytics (GA) 數據。 如果您的網站是全新的,則必須使用 3rd 方工具。 當您擁有自己的數據時,我寧願避免使用此類工具。
請記住,您需要針對您的一些真實頁面數據測試您正在使用的第 3 方數據,以發現其數據中可能存在的任何錯誤。
如何用 Python 計算非品牌 SEO 流量收入
到目前為止,我們已經介紹了許多我們應該熟悉的理論概念,以便更好地理解我們的自然流量和收入預測的不同方面。 現在,我們將深入探討本文的實際部分。
首先,我們將從計算 CTR 曲線開始。 在我關於 Oncrawl 的CTR 曲線文章中,我解釋了兩種不同的方法以及您可以通過對我的代碼進行一些更改來使用的其他方法。 我建議你先閱讀點擊曲線文章; 它為您提供有關本文的見解。
在本文中,我調整了我的代碼的某些部分以獲得我們在流量估計中想要的特定結果。 然後,我們將從 GA 中獲取數據並使用 GA 收入維度來估算我們的收入。
使用 Python 預測非品牌自然流量收入:入門
您可以自己運行此代碼,無需了解任何 Python。 但是,我希望您對 Python 語法和我將在此預測代碼中使用的 Python 庫的基本知識有所了解。 這將幫助您更好地理解我的代碼並以對您有用的方式對其進行自定義。
為了運行此代碼,我將使用 Visual Studio Code 和 Microsoft 的 Python 擴展,其中包括“Jupyter”擴展。 但是,您可以使用 Jupyter notebook 本身。
對於整個過程,我們需要用到這些 Python 庫:
- 麻木的
- 熊貓
- 情節
此外,我們將導入一些 Python 標準庫:
- JSON
- 打印
# 導入我們流程所需的庫 導入json 從 pprint 導入 pprint 將 numpy 導入為 np 將熊貓導入為 pd 將 plotly.express 導入為 px
第一步:計算相對點擊率曲線(Relative click curve)
第一步,我們要計算我們的相對 CTR 曲線。 但是,什麼是相對點擊率曲線?
什麼是相對點擊率曲線?
讓我們首先談談“絕對點擊率曲線”。 當我們計算絕對 CTR 曲線時,我們說第一個位置的 CTR 中值(或平均 CTR)為 36%,第二個位置為 20%,以此類推。
在相對 CTR 曲線中,百分比瞬間,我們將每個位置的中位數除以第一個位置的 CTR。 例如,第一個位置的相對 CTR 曲線為 0.36 / 0.36 = 1,第二個位置為 0.20 / 0.36 = 0.55,依此類推。
也許您想知道為什麼計算它很有用? 想想排名第一的頁面,它的點擊率為 44%。 如果此頁面轉到位置二,CTR 曲線不會下降到 20%,它的 CTR 很可能會下降到 44% * 0.55 = 24.2%。
1. 從 GSC 獲取品牌和非品牌自然流量數據
對於我們的計算過程,我們需要從 GSC 獲取數據。 第一次,所有數據都將基於品牌查詢,下一次,所有數據都將基於非品牌查詢。
要獲取此數據,您可以使用不同的方法:從 Python 腳本或從“Search Analytics for Sheets”Google 表格插件。 我將使用 GSC API 資源管理器。
此數據的輸出是兩個 JSON 文件,顯示每個頁面的性能。 一個 JSON 文件顯示基於品牌查詢的著陸頁性能,另一個顯示基於非品牌查詢的著陸頁性能。
要從 GSC API 資源管理器獲取數據,請執行以下步驟:
- 轉到 https://developers.google.com/webmaster-tools/v1/searchanalytics/query。
- 最大化頁面右上角的 API 資源管理器。
- 在“
siteUrl”字段中,插入您的域名。 例如“https://www.example.com”或“http://your-domain.com”。 - 在請求正文中,首先我們需要定義“
startDate”和“endDate”參數。 我的偏好是過去 30 天。 - 然後我們添加“
dimensions”並為此列表選擇“page”。 - 現在我們添加“
dimensionFilterGroups”來過濾我們的查詢。 一次用於品牌查詢,另一次用於非品牌查詢。 - 最後,我們將“
rowLimit”設置為 25,000。 如果您每月獲得自然流量的網站頁面超過 25K,則必須修改您的請求正文。 - 發出每個請求後,保存 JSON 響應。 對於品牌性能,將 JSON 文件保存為“
branded_data.json”,對於非品牌性能,將 JSON 文件保存為“non_branded_data.json”。
在我們了解了請求正文中的參數後,您唯一需要做的就是複制並粘貼到請求正文下方。 考慮用“ brand variation names ”替換您的品牌名稱。
您必須使用管道或“ | ”。 例如“ amazon|amazon.com|amazn ”。
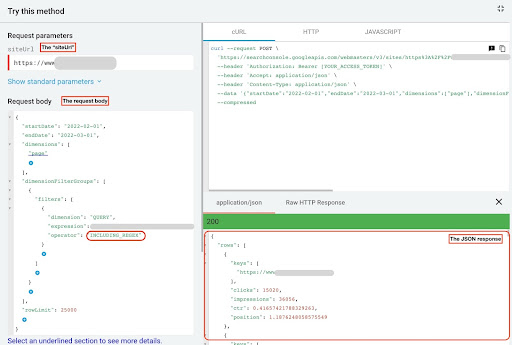
GSC API 瀏覽器
品牌請求正文:
{
"開始日期": "2022-02-01",
"endDate": "2022-03-01",
“方面”: [
“頁”
],
“維度過濾器組”:[
{
“過濾器”:[
{
“維度”:“查詢”,
“表達”:“品牌變體名稱”,
“操作員”:“INCLUDING_REGEX”
}
]
}
],
“行限制”:25000
}
非品牌請求正文:
{
"開始日期": "2022-02-01",
"endDate": "2022-03-01",
“方面”: [
“頁”
],
“維度過濾器組”:[
{
“過濾器”:[
{
“維度”:“查詢”,
“表達”:“品牌變體名稱”,
“操作員”:“EXCLUDING_REGEX”
}
]
}
],
“行限制”:25000
}
2. 將數據導入我們的 Jupyter notebook 並提取站點目錄
現在,我們需要將數據加載到 Jupyter 筆記本中,以便能夠對其進行修改並從中提取我們想要的內容。 讓我們從上面離開的地方繼續。
為了加載品牌數據,您需要執行以下代碼塊:
# 為品牌的網站 URL 性能和品牌查詢創建一個 DataFrame
使用 open("./brand_data.json") 作為 json_file:
brand_data = json.loads(json_file.read())["rows"]
brand_df = pd.DataFrame(brand_data)
# 將“keys”列重命名為“landing page”列,並將“landing page”列表轉換為 URL
brand_df.rename(columns={"keys": "landing page"}, inplace=True)
brand_df["著陸頁"] = brand_df["著陸頁"].apply(lambda x: x[0])
對於著陸頁非品牌性能,您需要執行以下代碼塊:
# 為非品牌查詢的網站 URL 性能創建一個 DataFrame
使用 open("./non_brand_data.json") 作為 json_file:
non_brand_data = json.loads(json_file.read())["rows"]
non_brand_df = pd.DataFrame(non_brand_data)
# 將“keys”列重命名為“landing page”列,並將“landing page”列表轉換為 URL
non_brand_df.rename(columns={"keys": "landing page"}, inplace=True)
non_brand_df["著陸頁"] = non_brand_df["著陸頁"].apply(lambda x: x[0])
我們加載我們的數據,然後我們需要定義我們的站點名稱以提取其目錄。
# 在引號之間定義您的站點名稱。 例如,“https://www.example.com/”或“http://mydomain.com/” SITE_NAME = "https://www.your_domain.com/"
我們只需要從非品牌表現中提取目錄。
# 獲取每個登陸頁面(URL)目錄
non_brand_df["目錄"] = non_brand_df["著陸頁"].str.extract(
pat=f"((?<={SITE_NAME})[^/]+)"
)
然後我們打印出目錄,以便選擇哪些目錄對這個過程很重要。 您可能希望選擇所有目錄以更好地了解您的站點。
# 為了獲取輸出中的所有目錄,我們需要操作 Pandas 選項
pd.set_option("display.max_rows", 無)
# 網站目錄
non_brand_df["目錄"].value_counts()
在這裡,您可以插入對您很重要的目錄。
""" 選擇哪些目錄對於獲取他們的 CTR 曲線很重要。
將目錄插入到“important_directories”變量中。
例如,“產品、標籤、產品類別、雜誌”。 用逗號分隔目錄值。
"""
IMPORTANT_DIRECTORIES = "你的重要目錄"
IMPORTANT_DIRECTORIES = IMPORTANT_DIRECTORIES.split(",")
3.根據頁面位置標記頁面併計算相對CTR曲線
現在我們需要根據它們的位置標記我們的著陸頁。 我們這樣做是因為我們需要根據每個目錄的著陸頁位置來計算每個目錄的相對 CTR 曲線。
# 標記非品牌職位
對於範圍內的 i (1, 11):
non_brand_df.loc[
(non_brand_df["position"] >= i) & (non_brand_df["position"] < i + 1),
“位置標籤”,
] = 我
然後,我們根據目錄對登錄頁面進行分組。

# 根據“目錄”值對登錄頁面進行分組 non_brand_grouped_df = non_brand_df.groupby(["目錄"])
讓我們定義計算相對 CTR 曲線的函數。
def each_dir_relative_ctr_curve(dir_df, key):
"""函數計算每條IMPORTANT_DIRECTORIES的相對CTR曲線。
"""
# 根據“位置標籤”值對“non_brand_grouped_df”進行分組
dir_grouped_df = dir_df.groupby(["位置標籤"])
# 保存每個位置中值 CTR 的列表
中位數_ctr_list = []
# 將每個目錄存儲為鍵,並將其“median_ctr_list”作為值
目錄_median_ctr = {}
# 遍歷每個“dir_grouped_df”組
對於範圍內的 i (1, 11):
# 一個 try-except 用於處理目錄例如位置 4 沒有任何數據的情況
嘗試:
tmp_df = dir_grouped_df.get_group(i)
median_ctr_list.append(np.median(tmp_df["ctr"]))
除了:
中位數_ctr_list.append(0)
# 計算相對點擊率曲線
directory_median_ctr[key] = np.array(median_ctr_list) / np.array(
[median_ctr_list[0]] * 10
)
返回目錄_median_ctr
定義函數後,我們運行它。
# 遍歷目錄並執行 'each_dir_relative_ctr_curve' 函數
目錄_median_ctr_dict = dict()
對於 key,non_brand_grouped_df 中的項目:
如果鍵入 IMPORTANT_DIRECTORIES:
目錄_median_ctr_dict.update(每個_dir_relative_ctr_curve(項目,鍵))
pprint(directories_median_ctr_dict)
現在,我們將加載我們的著陸頁、品牌和非品牌、性能併計算我們的非品牌數據的相對 CTR 曲線。 為什麼我們只對非品牌數據這樣做? 因為我們要預測非品牌的自然流量和收入。
第 2 步:預測非品牌自然流量收入
在第二步中,我們將了解如何檢索我們的收入數據並預測我們的收入。
1. 合併品牌和非品牌有機數據
現在,我們將合併我們的品牌和非品牌數據。 這將幫助我們計算每個著陸頁上的非品牌自然流量與所有流量相比的百分比。
# 'main_df' 是“整個站點數據”和“非品牌數據”數據幀的組合。
# 使用這個DataFrame,你可以找出我們的點擊次數和展示次數最多的地方
# 來自未標記的查詢。
main_df = non_brand_df.merge(
brand_df, on="著陸頁", suffixes=("_non_brand", "_brand")
)
然後我們修改列以刪除無用的列。
# 將 'main_df' 列修改為我們需要的列
main_df = main_df[
[
“登陸頁面”,
"clicks_non_brand",
"ctr_non_brand",
“目錄”,
“位置標籤”,
"clicks_brand",
]
]
現在,讓我們計算非品牌點擊次數佔著陸頁總點擊次數的百分比。
# 根據著陸頁計算非品牌查詢點擊次數佔整個著陸頁點擊次數的百分比
main_df.loc[:, "clicks_non_brand_percentage"] = main_df.apply(
lambda x: x["clicks_non_brand"] / (x["clicks_non_brand"] + x["clicks_brand"]),
軸=1,
)
[電子書] 使用 Oncrawl 自動化 SEO
 閱讀電子書
閱讀電子書2.加載自然流量收入
就像檢索 GSC 數據一樣,我們有多種獲取 GA 數據的方法:我們可以使用“Google Analytics Sheets 插件”或 GA API。 在本教程中,我更喜歡使用 Google Data Studio (GDS),因為它很簡單。
要從 GDS 獲取 GA 數據,請執行以下步驟:
- 在 GDS 中,創建一個新報表或資源管理器和一個表格。
- 對於維度,添加“著陸頁”,對於指標,我們必須添加“收入”。
- 然後,您需要在 GA 中基於來源和媒介創建自定義細分。 過濾“谷歌/自然”流量。 段創建後,將其添加到 GDS 中的段部分。
- 在最後一步,導出表格並將其保存為“
landing_pages_revenue.csv”。
著陸頁收入 csv 導出
讓我們加載我們的數據。
Organic_revenue_df = pd.read_csv("./data/landing_pages_revenue.csv")
現在,我們需要將我們的網站名稱附加到 GA 登錄頁面的 URL。
當我們從 GA 導出數據時,著陸頁是相對形式,但我們的 GSC 數據是絕對形式。
不要忘記檢查您的 GA 著陸頁數據。 在我使用的數據集中,我發現 GA 數據每次都需要稍微清理一下。
# 將 GA 著陸頁 URL 與 SITE_NAME 連接起來。
# 另外,重命名列
Organic_revenue_df.loc[:, "登陸頁面"] = (
SITE_NAME[:-1] + organic_revenue_df[organic_revenue_df.columns[0]]
)
Organic_revenue_df.rename(columns={"Landing Page": "landing page", "Revenue": "revenue"}, inplace=True)
現在,讓我們將 GSC 數據與 GA 數據合併。
# 在這一步中,我將 'main_df' 與 'dk_organic_revenue_df' DataFrame 合併,其中包含非品牌查詢數據的百分比 main_df = main_df.merge(organic_revenue_df, on="登陸頁", how="left")
在本節的最後,我們對 DataFrame 列進行了一些清理。
# 稍微清理一下 'main_df' DataFrame
main_df = main_df[
[
“登陸頁面”,
"clicks_non_brand",
"ctr_non_brand",
“目錄”,
“位置標籤”,
"clicks_non_brand_percentage",
“收入”,
]
]
3.計算非品牌收入
在本節中,我們將處理數據以提取我們正在尋找的信息。
但在此之前,讓我們根據“ IMPORTANT_DIRECTORIES ”過濾我們的登錄頁面:
# 刪除其他目錄登陸頁面,不包含在“IMPORTANT_DIRECTORIES”中
main_df = (
main_df[main_df["目錄"].isin(IMPORTANT_DIRECTORIES)]
.dropna(子集=["收入"])
.reset_index(drop=True)
)
現在,讓我們計算非品牌有機收入流量。
我定義了一個我們無法輕易計算的指標,它比其他任何東西都更直觀,可以讓我們為其分配一個數字。
“ brand_influence ”指標顯示了您的品牌實力。 如果您認為 non_brand 搜索會減少對您的業務的銷售額,請降低此數字; 例如 0.8 之類的東西。
# 如果您的品牌非常強大,以至於沒有您的品牌的查詢與使用您的品牌的查詢一樣多,那麼 1 對您有好處。
# 考慮尋找一本書,但查詢中沒有包含品牌名稱。 當您看到亞馬遜時,您會從其他市場或商店購買嗎?
品牌影響 = 1
main_df.loc[:, "non_brand_revenue"] = main_df.apply(
lambda x: x["revenue"] * x["clicks_non_brand_percentage"] * brand_influence, axis=1
)
讓我們繪製一個餅圖,以了解基於重要目錄的非品牌收入。
# 在這個單元格中,我想根據他們的目錄獲得所有非品牌登陸頁面的收入
non_brand_directory_dist_revenue_df = pd.pivot_table(
main_df,
索引="目錄",
值=[“non_brand_revenue”],
aggfunc={"non_brand_revenue": "sum"},
)
pie_fig = px.pie(
non_brand_directory_dist_revenue_df,
values="non_brand_revenue",
名稱=non_brand_directory_dist_revenue_df.index,
title="基於網站目錄的非品牌收入",
)
pie_fig.update_traces(textposition="inside", textinfo="percent+label")
pie_fig.show()
該圖顯示了IMPORTANT_DIRECTORIES上的非品牌查詢分佈。
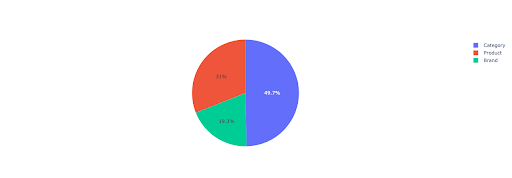
非品牌查詢分佈
根據我的 CTR 曲線數據,我發現我不能依賴高於 5 的位置的 CTR。因此,我根據位置過濾我的數據。
您可以根據您的數據修改以下代碼塊。
# 由於我們的 CTR 曲線中的 CTR 準確性,我認為我們可以跳過位置超過 5 的著陸頁。因此,我過濾了其他著陸頁 main_df = main_df[main_df["位置標籤"] < 6].reset_index(drop=True)
4. 計算“每次點擊收入”(RPC)
在這裡,我創建了一個自定義指標並將其稱為“每次點擊收入”或 RPC。 這向我們展示了每次非品牌點擊產生的收入。
您可以通過不同方式使用此指標。 我發現了一個 RPC 高但點擊率低的頁面。 當我檢查頁面時,我發現它在不到一周前被索引,我們可以使用不同的方法來優化頁面。
# 計算每次點擊產生的收入(RPC:Revenue Per Click)
main_df["rpc"] = main_df.apply(
lambda x: x["non_brand_revenue"] / x["clicks_non_brand"], axis=1
)
5. 預測收入!
我們快到頭了,我們一直等到現在才預測我們的非品牌有機收入。
讓我們運行最後的代碼塊。
# 主函數根據不同職位計算收益
對於 main_df.iterrows() 中的索引,row_values:
# 在目錄之間切換 CTR 列表
ctr_curve = 目錄_median_ctr_dict[row_values["directory"]]
# 循環位置 1 到 5,根據 CTR 的增減計算收益
對於範圍內的 i (1, 6):
如果 i == row_values["位置標籤"]:
main_df.loc[index, i] = row_values["non_brand_revenue"]
別的:
# main_df.loc[index, i + 1] ==
main_df.loc[index, i] = (
row_values["non_brand_revenue"]
* (ctr_curve[i - 1])
/ ctr_curve[int(row_values["位置標籤"] - 1)]
)
# 計算“N to 1”度量。 這顯示了當您的排名從“N”變為“1”時收入的增加
main_df.loc[index, "N to 1"] = main_df.loc[index, 1] - main_df.loc[index, row_values["位置標籤"]]
查看最終輸出,我們有新的列。 這些列的名稱是“1”、“2”、“3”、“4”、“5”。
這些名字是什麼意思? 例如,我們有一個位於第 3 位的頁面,如果它提高了它的位置,我們想預測它的收入,或者我們想知道如果我們的排名下降我們會損失多少。
“1”和“2”列顯示了當該頁面的平均排名提高時該頁面的收入,“4”和“5”列顯示了當我們排名下降時該頁面的收入。
此示例中的“3”列顯示頁面的當前收入。
此外,我創建了一個名為“N to 1”的指標。 這會顯示此頁面的平均排名是否從“3”(或 N)變為“1”,以及該移動對收入的影響程度。
包起來
我在本文中介紹了很多內容,現在輪到您動手並預測您的非品牌自然流量收入了。
這是我們可以使用此預測的最簡單方法。 我們可以讓這個算法更複雜,並將它與一些 ML 模型結合起來,但這會使文章變得更複雜。
我更喜歡將這些數據保存在 CSV 中並將其上傳到 Google 表格。 或者,如果我打算與我的團隊或組織的其他成員共享它,我將使用 excel 打開它並使用顏色設置列的格式,以便於閱讀。
根據這些數據,您可以預測您的非品牌自然流量投資回報率並將其用於您的談判過程。