
使用 Prophet 和 Python 預測 SEO 流量
已發表: 2021-03-16設定目標並隨著時間的推移評估成就是一項非常有趣的練習,以便了解我們能夠實現什麼以及我們使用的策略是否有效。 然而,設定這些目標通常並不容易,因為我們首先需要做出預測。
創建預測並不是一件容易的事,但由於一些可用的預測程序、我們的 CPU 和一些編程技能,我們可以大大降低其複雜性。 在這篇文章中,我將向您展示我們如何做出準確的預測,以及如何通過使用 Python 和 Prophet 庫將其應用於 SEO,而無需擁有算命先生的超能力。
如果您從未聽說過 Prophet,您可能想知道它是什麼。 簡而言之,Prophet 是一個預測程序,由 Facebook 的核心數據科學團隊發布,提供 Python 和 R 語言版本,可以很好地處理異常值和季節性影響
提供準確和快速的預測。
當我們談論預測時,我們需要考慮兩件事:
- 我們擁有的歷史數據越多,我們的模型就越準確,因此我們的預測也就越準確。
- 預測模型只有在內部因素保持不變且沒有外部因素影響的情況下才有效。 這意味著,例如,如果我們每週發布一篇文章,而我們開始每週發布兩篇文章,則此模型可能無法有效預測此策略更改的結果。 另一方面,如果有算法更新,模型也可能無效。 請記住,該模型是基於歷史數據構建的。
要將其應用於 SEO,我們要做的是在接下來的步驟之後預測下個月的 SEO 會話:
- 從 Google Analytics 獲取特定時間段內自然會話的數據。
- 訓練我們的模型。
- 預測下個月的 SEO 流量。
- 用平均絕對誤差評估我們的模型有多好。
您想進一步了解此預測程序的工作原理嗎? 讓我們開始吧!
從 Google Analytics 獲取數據
我們可以通過兩種方式從 Google Analytics 中提取數據:從普通界面導出 Excel 文件或使用 API 檢索這些數據。
從 Excel 文件導入數據
從 Google Analytics 獲取這些數據的最簡單方法是轉到側欄上的 Channels 部分,單擊 Organic 並使用頁面頂部的按鈕導出數據。 確保在圖表頂部的下拉菜單中選擇要分析的變量,在本例中為 Sessions。
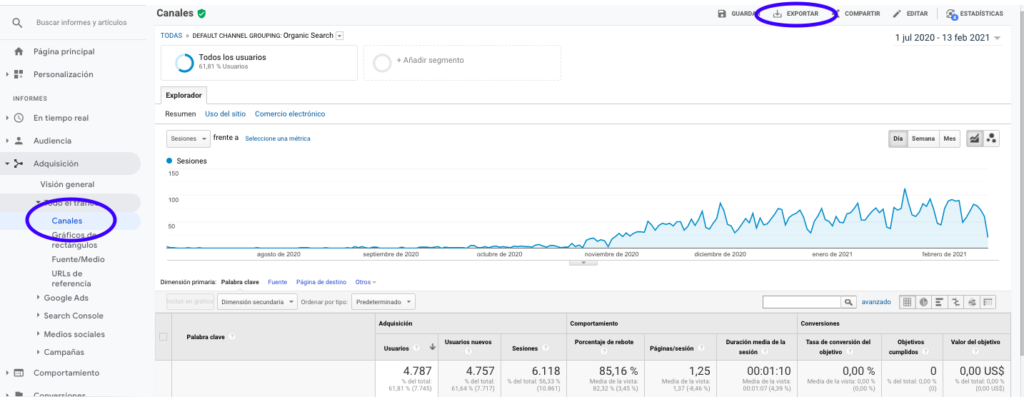
將數據導出為 Excel 文件後,我們可以使用 Pandas 將其導入到我們的筆記本中。 請注意,具有此類數據的 Excel 文件將包含不同的選項卡,因此需要在下面的代碼中將具有每月流量的選項卡指定為參數。 我們還刪除了最後一行,因為它包含會話總數,這會扭曲我們的模型。
將熊貓導入為 pd
df = pd.read_excel ('.xlsx', sheet_name="")
df = df.drop(len(df) - 1)
我們可以用 Matplotlib 畫出數據的樣子:
從 matplotlib 導入 pyplot
df["Sesiones"].plot(title = "Sesiones")
pyplot.show() 
使用谷歌分析 API
首先,為了使用 Google Analytics API,我們需要在 Google 的開發者控制台上創建一個項目,啟用 Google Analytics Reporting 服務並獲取憑證。 Jean-Christophe Chouinard 在這篇文章中很好地解釋瞭如何設置它。
獲得憑據後,我們需要在發出請求之前進行身份驗證。 身份驗證需要使用最初從 Google 開發者控制台獲得的憑證文件來完成。 我們還需要在我們的代碼中寫下我們想要使用的屬性的 GA View ID。
從 apiclient.discovery 導入構建 從 oauth2client.service_account 導入 ServiceAccountCredentials SCOPES = ['https://www.googleapis.com/auth/analytics.readonly'] KEY_FILE_LOCATION = '' 看法_ 憑據 = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE_LOCATION, SCOPES) 分析=構建('analyticsreporting','v4',憑證=憑證)
身份驗證後,我們只需要發出請求。 我們需要用來獲取每天有機會話數據的方法是:
響應 = analytics.reports().batchGet(body={
“報告請求”:[{
'viewId': VIEW_ID,
'dateRanges': [{'startDate': '2020-09-01', 'endDate': '2021-01-31'}],
“指標”:[
{“表達式”:“ga:會話”}
], “方面”: [
{“名稱”:“ga:日期”}
],
"filtersExpression":"ga:channelGrouping=~Organic",
“includeEmptyRows”:“真”
}]})。執行()請注意,我們在 dateRanges 中選擇時間範圍。 就我而言,我將從 9 月 1 日到 1 月 31 日檢索數據:[{'startDate': '2020-09-01', 'endDate': '2021-01-31'}]
在此之後,我們只需要獲取響應文件以將其有機會話的日期附加到列表中:
列表值 = [] 對於 x 響應 ["reports"][0]["data"]["rows"]: list_values.append([x["dimensions"][0],x["metrics"][0]["values"][0]])
如您所見,使用 Google Analytics API 非常簡單,它可以用於許多目標。 在本文中,我解釋瞭如何使用 Google Analytics API 創建警報以檢測表現不佳的頁面。

使列表適應數據框
要使用 Prophet,我們需要輸入一個包含兩列需要命名的 Dataframe:“ds”和“y”。 如果您從 Excel 文件中導入數據,我們已經將其作為 Dataframe,因此您只需將列命名為“ds”和“y”:
df.columns = ['ds', 'y']
如果您使用 API 來檢索數據,那麼我們需要將列表轉換為數據框並根據需要命名列:
從熊貓導入數據框 df_sessions = DataFrame(list_values,columns=['ds','y'])
訓練模型
一旦我們有了所需格式的數據框,我們就可以很容易地確定和訓練我們的模型:
導入 fbprophet 從 fbprophet 導入 Prophet 模型 = 先知() model.fit(df_sessions)
做出我們的預測
最後在訓練我們的模型之後,我們就可以開始預測了! 為了繼續進行預測,我們首先需要創建一個列表,其中包含我們想要預測的時間範圍並調整日期時間格式:
從熊貓導入 to_datetime 預測天數 = [] 對於範圍內的 x (1, 28): 日期 = "2021-02-" + str(x) Forecast_days.append([日期]) 預測天數 = 數據幀(預測天數) forecast_days.columns = ['ds'] forecast_days['ds']= to_datetime(forecast_days['ds'])
在這個例子中,我使用了一個循環來創建一個數據框,該數據框將包含從 2 月開始的所有日期。 現在只需要使用之前訓練的模型即可:
預測 = model.predict(forecast_days)
我們可以繪製一個突出顯示預測時間段的圖:
從 matplotlib 導入 pyplot model.plot(預測) pyplot.show()

評估模型
最後,我們可以通過從用於訓練模型的數據中剔除一些天數、預測這些天數的會話併計算平均絕對誤差來評估我們的模型的準確性。
例如,我要做的是從原始數據幀中剔除從一月份開始的最後 12 天,預測每天的會話並將實際流量與預測流量進行比較。
首先,我們使用 pop 從原始數據框中刪除最後 12 天,然後創建一個新數據框,其中僅包含將用於預測的那 12 天:
火車 = df_sessions.drop(df_sessions.index[-12:]) 未來 = df_sessions.loc[df_sessions["ds"]> train.iloc[len(train)-1]["ds"]]["ds"]
現在我們訓練模型,進行預測併計算平均絕對誤差。 最後,我們可以繪製一個圖表,顯示實際預測值與真實值之間的差異。 這是我從 Jason Brownlee 撰寫的這篇文章中學到的。
從 sklearn.metrics 導入 mean_absolute_error
將 numpy 導入為 np
從 numpy 導入數組
#我們訓練模型
模型 = 先知()
模型.fit(火車)
#將用於預測天數的數據框調整為 Prophet 所需的格式。
未來 = 列表(未來)
未來 = 數據幀(未來)
未來 = future.rename(columns={0: 'ds'})
# 我們做出預測
預測 = 模型.預測(未來)
# 我們計算實際值和預測值之間的 MAE
y_true = df_sessions['y'][-12:].values
y_pred = 預測['yhat'].values
mae = mean_absolute_error(y_true, y_pred)
# 我們繪製最終輸出以進行視覺理解
y_true = np.stack(y_true).astype(float)
pyplot.plot(y_true, label='實際')
pyplot.plot(y_pred, label='Predicted')
pyplot.legend()
pyplot.show()
打印(前) 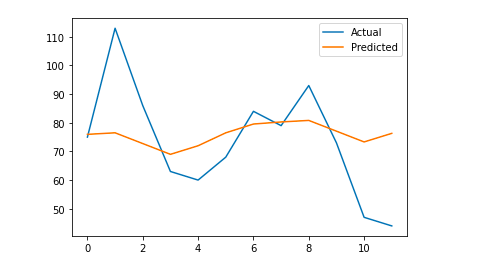
我的平均絕對誤差是 13,這意味著我的預測模型每天分配的會話數比實際會話數多 13,這似乎是一個可以接受的錯誤。
這就是所有的人! 我希望您發現這篇文章很有趣,並且您可以開始進行 SEO 預測以設定目標。
更進一步:OnCrawl 實驗室
如果您喜歡使用這種方法預測您的流量,您也會對 OnCrawl Labs 感興趣,它是 OnCrawl 的數據科學和機器學習實驗室,可為您的 SEO 工作流程提供預編碼項目。
在 SEO 預測中,OnCrawl Labs 將幫助您完善您的 SEO 預測:
- 更好地理解 Facebook Prophet 算法背後的理論和流程
- 分析一段流量,例如僅針對長尾關鍵詞的流量,或僅針對品牌關鍵詞的流量……
- 按照循序漸進的過程設置歷史事件,調整其影響和再次發生的可能性。