
Importancia estadística de las pruebas A/B: cómo y cuándo finalizar una prueba
Publicado: 2020-05-22
En nuestro análisis reciente de 28 304 experimentos realizados por clientes de Convert, encontramos que solo el 20 % de los experimentos alcanzan el nivel de significancia estadística del 95 %. Econsultancy descubrió una tendencia similar en su informe de optimización de 2018. Dos tercios de sus encuestados ven un "ganador claro y estadísticamente significativo" en solo el 30% o menos de sus experimentos.
Por lo tanto, la mayoría de los experimentos (70-80%) no son concluyentes o se detienen antes de tiempo.
De estos, los que se detuvieron antes constituyen un caso curioso, ya que los optimizadores toman la llamada para finalizar los experimentos cuando lo consideran oportuno. Lo hacen cuando pueden “ver” un claro ganador (o perdedor) o una prueba claramente insignificante. Por lo general, también tienen algunos datos para justificarlo.
Es posible que esto no parezca tan sorprendente, dado que el 50 % de los optimizadores no tienen un "punto final" estándar para sus experimentos. Para la mayoría, hacerlo es una necesidad, gracias a la presión de tener que mantener una determinada velocidad de prueba (XXX pruebas/mes) y la carrera por dominar a la competencia.
Luego también existe la posibilidad de que un experimento negativo perjudique los ingresos. ¡Nuestra propia investigación ha demostrado que los experimentos no ganadores, en promedio, pueden causar una disminución del 26% en la tasa de conversión !
Dicho todo esto, terminar los experimentos antes de tiempo sigue siendo arriesgado...
… porque deja la probabilidad de que si el experimento hubiera tenido la duración prevista, con el tamaño de muestra correcto, su resultado podría haber sido diferente.
Entonces, ¿cómo saben los equipos que terminan los experimentos antes de tiempo cuándo es el momento de terminarlos? Para la mayoría, la respuesta radica en diseñar reglas de parada que aceleren la toma de decisiones, sin comprometer su calidad.
Alejarse de las reglas de parada tradicionales
Para los experimentos web, un valor p de 0,05 sirve como estándar. Esta tolerancia de error del 5 % o el nivel de significancia estadística del 95 % ayuda a los optimizadores a mantener la integridad de sus pruebas. Pueden garantizar que los resultados sean resultados reales y no casualidades.
En los modelos estadísticos tradicionales para pruebas de horizonte fijo, donde los datos de prueba se evalúan solo una vez en un momento fijo o en un número específico de usuarios comprometidos, aceptará un resultado como significativo cuando tenga un valor p inferior a 0,05. En este punto, puede rechazar la hipótesis nula de que su control y tratamiento son los mismos y que los resultados observados no son casuales.
A diferencia de los modelos estadísticos que le brindan la posibilidad de evaluar sus datos a medida que se recopilan, dichos modelos de prueba le prohíben mirar los datos de su experimento mientras se está ejecutando. Esta práctica, también conocida como mirar a escondidas, se desaconseja en dichos modelos porque el valor p fluctúa casi a diario. Verá que un experimento será significativo un día y al día siguiente, su valor p aumentará hasta un punto en el que ya no será significativo.
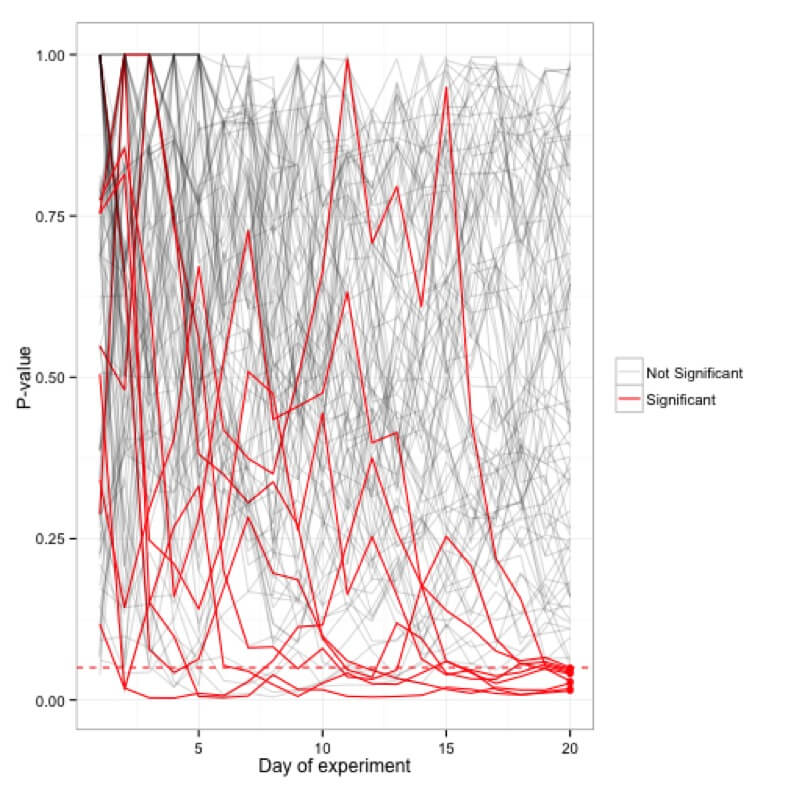
Simulaciones de los valores de p trazados para cien (20 días) experimentos; solo 5 experimentos terminan siendo significativos en la marca de 20 días, mientras que muchos ocasionalmente alcanzan el límite de <0.05 en el ínterin.
Echar un vistazo a sus experimentos mientras tanto puede mostrar resultados que no existen. Por ejemplo, a continuación tiene una prueba A/A con un nivel de significación de 0,1. Dado que es una prueba A/A, no hay diferencia entre el control y el tratamiento. Sin embargo, después de 500 observaciones durante el experimento en curso, hay más del 50 % de posibilidades de concluir que son diferentes y que se puede rechazar la hipótesis nula:

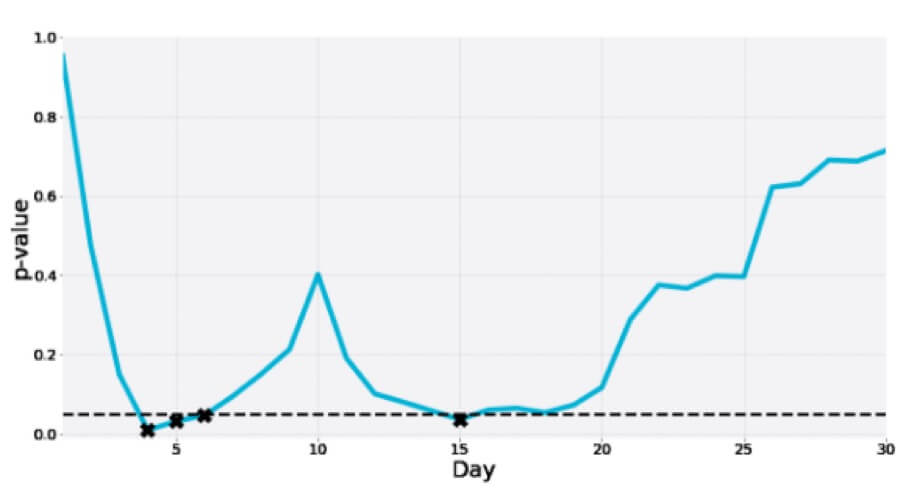
Aquí hay otra de una prueba A/A de 30 días de duración en la que el valor p cae a la zona de importancia varias veces en el ínterin solo para finalmente ser mucho más que el límite:
Informar correctamente un valor p de un experimento de horizonte fijo significa que debe comprometerse previamente con un tamaño de muestra o una duración de prueba fijos. Algunos equipos también agregan una cierta cantidad de conversiones a este experimento, criterios de detención y una duración prevista.
Sin embargo, el problema aquí es que tener suficiente tráfico de prueba para impulsar cada experimento para dejar de usar esta práctica estándar es difícil para la mayoría de los sitios web.
Aquí es donde ayuda el uso de métodos de prueba secuenciales que admitan reglas de parada opcionales.
Avanzando hacia reglas de parada flexibles que permitan decisiones más rápidas
Los métodos de prueba secuencial le permiten acceder a los datos de sus experimentos tal como aparecen y utilizar sus propios modelos de significación estadística para detectar antes a los ganadores, con reglas de parada flexibles.
Los equipos de optimización en los niveles más altos de madurez de CRO a menudo diseñan sus propias metodologías estadísticas para respaldar dichas pruebas. Algunas herramientas de prueba A/B también tienen esto incorporado y podrían sugerir si una versión parece estar ganando. Y algunos le dan control total sobre cómo desea que se calcule su importancia estadística, con sus valores personalizados y más. Para que pueda echar un vistazo y detectar un ganador incluso en un experimento en curso.

Estadístico, autor e instructor del popular curso CXL sobre estadísticas de pruebas A/B, Georgi Georgiev está totalmente a favor de los métodos de prueba secuenciales que permiten flexibilidad en el número y el momento de los análisis intermedios:
“ Las pruebas secuenciales le permiten maximizar las ganancias mediante la implementación temprana de una variante ganadora, así como detener las pruebas que tienen pocas probabilidades de producir un ganador lo antes posible. Este último minimiza las pérdidas debidas a variantes inferiores y acelera las pruebas cuando es poco probable que las variantes superen al control. En todos los casos se mantiene el rigor estadístico. ”
Georgiev incluso ha trabajado en una calculadora que ayuda a los equipos a deshacerse de los modelos de prueba de muestra fijos por uno que puede detectar un ganador mientras aún se está ejecutando un experimento. Su modelo tiene en cuenta muchas estadísticas y lo ayuda a llamar a las pruebas entre un 20 y un 80 % más rápido que los cálculos estándar de significación estadística, sin sacrificar la calidad.
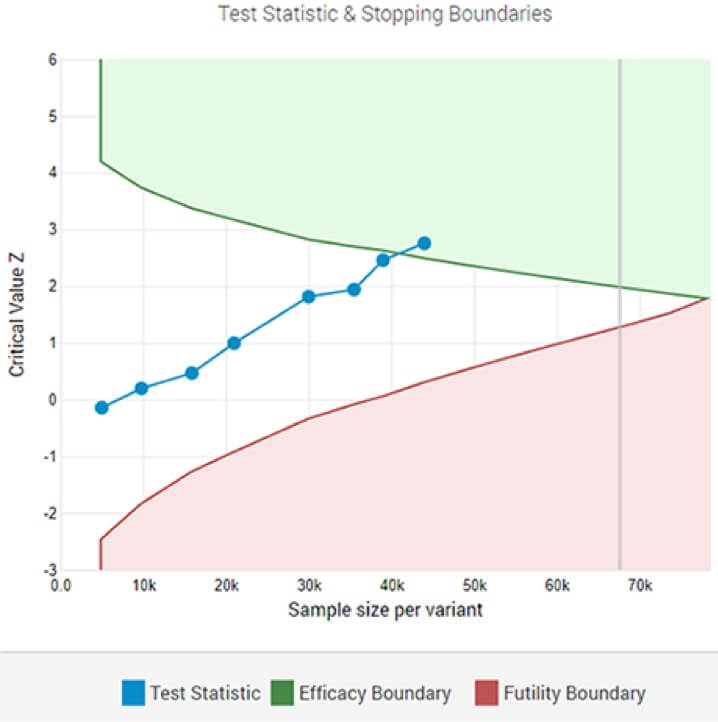
Una prueba A/B adaptativa que muestra un ganador estadísticamente significativo en el umbral de significación designado después del 8.º análisis intermedio.
Si bien estas pruebas pueden acelerar su proceso de toma de decisiones, hay un aspecto importante que debe abordarse: el impacto real del experimento . Terminar un experimento en el ínterin puede llevarlo a sobreestimarlo.
Observar estimaciones no ajustadas del tamaño del efecto puede ser peligroso, advierte Georgiev. Para evitar esto, su modelo usa métodos para aplicar ajustes que toman en cuenta el sesgo incurrido debido al monitoreo intermedio. Explica cómo su análisis ágil ajusta las estimaciones "según la etapa de detención y el valor observado de la estadística (sobrepaso, si lo hay)". A continuación, puede ver el análisis de la prueba anterior: (Observe cómo la elevación estimada es más baja que la observada y el intervalo no está centrado alrededor de ella).

Por lo tanto, una ganancia puede no ser tan grande como parece según su experimento más corto de lo previsto.
La pérdida también debe tenerse en cuenta, porque es posible que hayas terminado erróneamente llamando a un ganador demasiado pronto. Pero este riesgo existe incluso en las pruebas de horizonte fijo. Sin embargo, la validez externa puede ser una preocupación mayor cuando se realizan experimentos con anticipación en comparación con una prueba de horizonte fijo de mayor duración. Pero esto es, como explica Georgiev, “ una simple consecuencia del tamaño de muestra más pequeño y, por lo tanto, de la duración de la prueba. “
Al final... No se trata de ganadores o perdedores...
… sino de mejores decisiones empresariales, como dice Chris Stucchio.
O como Tom Redman (autor de Data Driven: Profiting from Your Most Important Business Asset) afirma que en los negocios: “ a menudo hay criterios más importantes que la significancia estadística. La pregunta importante es: “ ¿Se mantiene el resultado en el mercado, aunque solo sea por un breve período de tiempo? ”'
Y probablemente lo hará, y no solo por un breve período, señala Georgiev, " si es estadísticamente significativo y las consideraciones de validez externa se abordaron de manera satisfactoria en la etapa de diseño".
Toda la esencia de la experimentación es capacitar a los equipos para que tomen decisiones más informadas. Entonces, si puede transmitir los resultados, a los que apuntan los datos de sus experimentos, antes, ¿por qué no?
Puede ser un pequeño experimento de interfaz de usuario para el que prácticamente no puede obtener un tamaño de muestra "suficiente". ¡También podría ser un experimento en el que tu retador aplasta al original y podrías aceptar esa apuesta!
Como escribe Jeff Bezos en su carta a los accionistas de Amazon, los grandes experimentos pagan mucho:
“ Dada una probabilidad del diez por ciento de un pago de 100 veces, debe aceptar esa apuesta cada vez. Pero igual te equivocarás nueve de cada diez veces. Todos sabemos que si bateas hacia las cercas, vas a poncharte mucho, pero también vas a conectar algunos jonrones. Sin embargo, la diferencia entre el béisbol y los negocios es que el béisbol tiene una distribución de resultados truncada. Cuando haces el swing, no importa qué tan bien conectes con la pelota, la mayor cantidad de carreras que puedes obtener son cuatro. En los negocios, de vez en cuando, cuando te acercas al plato, puedes anotar 1,000 carreras. Esta distribución de rendimientos de cola larga es la razón por la cual es importante ser audaz. Los grandes ganadores pagan tantos experimentos. “
Llamar a los experimentos temprano, en gran medida, es como mirar todos los días los resultados y detenerse en un punto que garantiza una buena apuesta.

